RANT: IA acabou com os programadores?
Quem só acompanhou cortes e comentários, sem assistir aos meus vídeos sobre IA no meu canal, ou pelo menos ao podcast no Flow, está achando que eu disse o seguinte:
“IAs NUNCA vão substituir NENHUM programador”
E isso está errado. Assista ao vídeo com a explicação (ou procure a transcrição). Mas em resumo, o que eu disse foi:
“IAs nunca vão substituir programadores COMO EU - EU nunca vou ser substituído”
Outra coisa que afirmei e continuo a afirmar é:
“AGIs não são possíveis na arquitetura atual: não vai acontecer. Precisa vir uma nova descoberta — que, obviamente, ainda não sabemos qual — pra ultrapassar a barreira atual, que é intransponível.
E foi disso que eu derivei esta frase:
“Sua empolgação com IA é inversamente proporcional ao seu conhecimento sobre IA” — e isso continua valendo igual.

A Bolha de Programação já estourou
Meu canal começou em 2018 e durou até o início de 2024, com um único propósito:
Ajudar a preparar programadores de verdade para sobreviverem ao estouro iminente da bolha (que se iniciou por volta de 2014).
Tenho uma playlist inteira intitulada EU AVISEI.
Em resumo, nos anos recentes, “programação” se tornou a “profissão do futuro”, e parecia fácil. Ficou óbvio quando o que mais se via era propaganda de todo tipo de curso e bootcamp, com promessas como: “vire programador em 2 meses, ganhe salário de Google e nem precisa trabalhar muito.”
Eu chamei esse tipo de programador de “chef de Miojo”. Só porque você sabe esquentar água e fazer miojo, isso não te torna um chef. Deveria ser óbvio, mas é como a programação era vista. Nenhum desses cursos formou nenhum “programador”, muito menos “engenheiro de software”.
Mas “engenheiro de software” não é uma engenharia de verdade. Não existe um CREA, CRM, OAB, nada equivalente que certifique alguém como “engenheiro de software”. Isso é um título inventado que qualquer pessoa pode colocar no LinkedIn.
O Cisne Negro da Pandemia foi algo que eu não previ, mas isso só ajudou a inflar ainda mais a fase final da bolha, que estourou no fim de 2022 quando se iniciaram layoffs em massa em todas as big techs. E isso foi ANTES do advento das LLMs pra programação. Por coincidência, ChatGPT surgiu na mesma época em 2022, mas essa não foi a causa; foi só o último prego no caixão. O estouro daquela bolha e os layoffs viriam de qualquer forma.
Por isso, meu canal deve ser o único que, ainda hoje, oferece os conteúdos de que alguém que realmente pensa em ser programador precisa. Imagina os outros canais que só propagandearam que virar programador era fácil, envelheceram BEM mal.
Portanto, sim, concordo com o CEO da Anthropic: esses “engenheiros de software” se tornarão completamente obsoletos. Não existe virar “engenheiro” em um bootcamp de 1 mês. Isso era bullshit e tinha que ser muito idiota pra acreditar. Notem que todos esses vendedores de óleo de cobra SUMIRAM. Cadê eles?
Não sabe por onde começar no meu canal? Duas sugestões:
- Playlist “Que cursos devo fazer?”
- Playlist “Carreira”
O “teto” das IAs
Eu terminei de gravar vídeos pro meu canal exatamente quando começou essa onda de IAs. Considerei que tudo o que queria dizer já foi dito e isso continua disponível no canal. Meu objetivo foi atingido.
Durante 2024 e 2025 eu participei de podcasts como Flow e Inteligência Ltda falando muito sobre IAs e coisas como computação quântica (e como também é só um hype que não vai em nada prático pro nosso dia a dia).
O principal: desde o paper sobre transformers Attention is all you need, ainda não surgiu nenhum outro “breakthrough” que ultrapasse esse marco. Tudo o que temos hoje, de OpenAI à Anthropic, e de open sources como DeepSeek, Qwen3, GLM, MiniMax etc., se baseia exatamente na mesma fundação, na mesma “arquitetura”.
E eu teorizei - corretamente - que a evolução dessa arquitetura obedeceria a uma Curva em S:
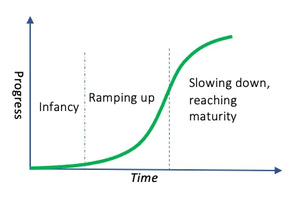
GPT-1 para o 2 foi um salto quântico. GPT-2 para o 3 foi um salto gigante. GPT-3 para o 4 foi excelente, mas, notavelmente, não na mesma proporção. GPT-4 para o 5, a maioria das pessoas comuns nem notou tanta diferença.
Claro, ninguém ficou parado; todo cientista da computação, matemático, engenheiro foi fazendo o que sempre fazemos: otimizando. Surgiram melhores formas de treinar, a ideia de “reasoning”, a ideia de agentes trabalhando em conjunto (um dando feedback pro outro), novas formas de alinhamento e de instrução. Mas nada disso altera a arquitetura da fundação.
O problema: pra treinar cada nova geração de LLMs, fica consideravelmente mais caro (em hardware e, principalmente, no consumo de energia) pra gerar uma versão que não é muito melhor que a anterior. Esse é o teto da curva. E eu reafirmo: enquanto não surgir uma NOVA ARQUITETURA, vamos só chegar cada vez mais perto desse teto, sem ultrapassá-la, mas gastando níveis absurdos de mais memória e mais energia.
Por isso, está faltando energia: com o aumento da demanda de uso (inferência), eles têm que se dividir entre gastar energia pra treinar novas versões e atender à demanda. Não dá pra fazer os dois.
Pior, por isso, a memória RAM explodiu em preço e seu PC também vai ficar muito mais caro. Não tem mais recursos pra treinar modelos tão grandes que, proporcionalmente, oferecem cada vez menos resultado (definição de “diminishing returns”). É o destino de toda inovação: bater no teto da curva em S até surgir outra que a substitua.
O foco agora está em usar melhor as versões que já temos. No caso de programação, surgem GPT Codex ou Claude Code, que são estratégias de uso de agentes, MCPs, skills e outras ferramentas e formas de orquestração pra extrair o máximo do que já temos hoje.
Estratégias das LLMs
Todo mundo já sabe que é impossível só fazer um prompt e que qualquer LLM saia com um sistema perfeito no final. Vai sair muito ruim; continua assim e vai continuar assim nesta arquitetura.
Toda LLM tem um limite de contexto (memória). É impossível carregar todo o código-fonte de um ERP gigante como o da Totus ou o da SAP. Não cabe, e mesmo se coubesse, não seria possível dar “atenção” a tudo. Existem limites: quanto mais memória você coloca, pior fica a inferência; o resultado fica pior. Como tudo em software, é um “trade-off”.
Em vez disso, o melhor é criar scripts que percorrem seu código e extraem pedaços específicos a cada execução. Se estiver mexendo no carrinho de compras, não precisa carregar código que lida com a tela inicial da loja, por exemplo. É parecido com o que um programador humano faria: dividir pra conquistar (como diria Napoleão).
Toda LLM específica pra código, como Codex ou Opus, foi treinada pra fazer “tool calling”, que é enviar um pedido ao “chat” pra que ele busque informações (como código) e carregue trechos no contexto. Pra isso, ele manda executar ferramentas como “rg” ripgrep (no caso do Codex) ou “grep” (no caso do OpenCode).
Se, por acaso, o modelo não foi treinado com informações que só saíram recentemente na Web, ele pode fazer “agentic fetch”, que é executar comandos como “curl” pra, literalmente, ir no Google, no Stack Overflow, etc., e puxar as páginas web pra usar como parte do contexto (o trade-off é que isso vai usar o espaço limitado de contexto).
Quando o contexto está prestes a acabar (a faixa de 200 mil tokens, no caso de um Claude, ou 1 milhão, no caso de um Gemini), o “chat” que orquestra (Claude Code, OpenCode, etc.) manda gerar um resumo do contexto atual, pra “compactar” o entendimento e reiniciar com um novo contexto com base nesse resumo.
Pra garantir que o código gerado “funcione”, o tool calling pede pra rodar ferramentas locais, como linters, compiladores ou LSPs (como uma IDE, como o VSCode, faria). Isso gera feedback (e gasta mais contexto). Se errar, o “chat” pode pedir automaticamente pra refazer, levando essa nova informação em consideração.
Além disso, pra ir “mais rápido”, o “chat” pode mandar executar vários agentes em paralelo. Cada agente é um novo contexto - e nada disso é de graça, lembrem-se: tokens por segundo. Então, poderia mandar um agente vasculhar todo o código relevante ao banco de dados e, no final, gerar um resumo. Outro agente vasculha todo o código de pagamentos e, ao final, gera um resumo. Outro agente vasculha o código relevante ao front-end do carrinho e gera um resumo. Então o “chat” pega esses resumos e volta ao contexto anterior pra executar alguma tarefa.
O que chamo de “chat” é só pra ficar mais fácil de visualizar. Pense na interface simples de chat que todo mundo usa no dia a dia, mas com recursos adicionais. Isso é o que faz um Codex ou um Claude Code. Não tem segredo nenhum, toda ferramenta dessas, assim como as open source como Opencode ou Crush, fazem a mesma coisa: configuram um “Harness”:
- Iniciam com um prompt de sistema detalhando exatamente como quer que a LLM responda. Este GitHub tem vários exemplos desses prompts que a ferramenta envia sem você saber.
- As LLMs são treinadas com tool calling e a ferramenta sabe como responder a essas chamadas (executando bash, curl, ripgrep, sed, diff, git, etc)
- A ferramenta é capaz de executar múltiplos agentes em paralelo (pense múltiplos “chats” em paralelo)
- A ferramenta pede pra LLM gerar um “plano” primeiro e enumerar tarefas. Daí ela pode orquestrar a execução sequencial dessas tarefas, cada uma em um agente diferente, por exemplo.
- A ferramenta é capaz de gerenciar os limites de contexto e saber quando mandar resumir, e como reiniciar um novo contexto e continuar a execução das tarefas restantes
- A ferramenta é responsável por criar um contêiner e evitar que comandos malfeitos afetem seu sistema (isso é opcional; nem todos fazem ou não ligam por padrão. Cuidado!)
Eu documentei sobre isso em vários posts neste blog:
- Hello World de LLM: criando seu próprio chat de I.A. que roda local
- Rant - LLMs vão evoluir pra sempre? Desmistificando LLMs na programação
- Quando LLMs não Funcionam pra Programar? Um caso de uso mais real.
- AI Agents: Garantindo a Proteção do seu Sistema
- AI Agents: Comparando as principais LLM de 2026 no Desafio de Zig
- AI Agents: Instalando LSPs pro Crush
- AI Agents: Qual é o melhor? OpenCode, Crush, Claude Code, GPT Codex, GoPilot, Cursor, WindSurf, AntiGravity?
- Vibe Code: Eu fiz um appzinho 100% com GLM 4.7 (TV Clipboard)
- Vibe Code: Qual LLM é a MELHOR?? Vamos falar a REAL
- Vibe Code: Fiz um Editor de Markdown do zero com Claude Code (FrankMD) PARTE 1
- Vibe Code: Fiz um Editor de Markdown do zero com Claude Code (FrankMD) PARTE 2
O Fim do Stack Overflow
Na época do GPT-3 e do GPT-4, eu já fazia códigos usando LLMs e funcionava bem. Mas eles ainda tinham muitas chatices. As alucinações eram muito frequentes. Tinha muito “agentic loop” (quando a LLM “acha” que já consertou, mas não consertou e fica em loop, sem saber o que fazer). A atenção ao contexto era facilmente perdida (melhorou muito com a Flash attention). Enfim, vários problemas mais “grosseiros” já foram ajustados a ponto de não aparecerem mais com tanta frequência. Não é “resolvido”; ainda acontece, mas cada vez está melhorando.
Quanto mais se aprimoraram os dados de treinamento e o alinhamento, mais esses problemas desapareceram. O problema é que já chegamos ao ponto em que acabaram os dados de treinamento no mundo. Tudo o que poderia ser usado já foi. Não é só falta de energia e de hardware. Acabou a informação pra treinar.
A solução foi massagear os dados existentes pra extrair o máximo possível e adicionar muitos dados sintéticos (gerados pela própria IA). De novo, isso já bate num teto de “diminishing returns”.
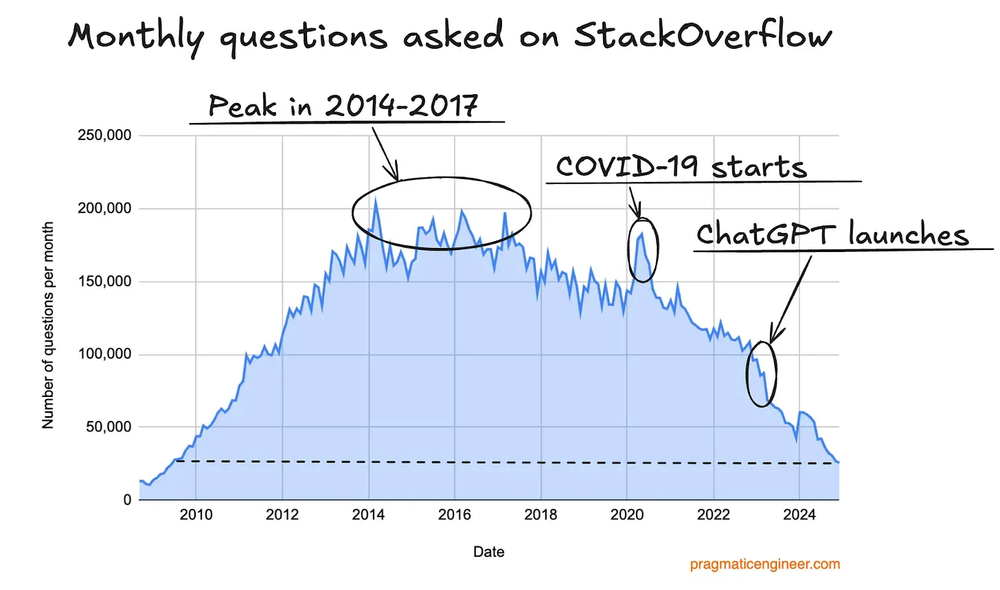
Além disso, vários sites usados pra extrair dados pra treinar as LLMs estão caindo em desuso. O exemplo mais notável é o venerável Stack Overflow. Vejam como caiu o tráfego.
Alguns desavisados poderiam só pensar: “ah, tudo bem, o povo passou a fazer pergunta idiota pras LLMs, acabou aquele monte de gente postando pergunta básica nos fóruns.”
É verdade, parece um avanço. Mas até “pergunta idiota” é um dado relevante de treinamento. Se a LLM “vê” que certos assuntos têm maior probabilidade, quando ela receber a mesma pergunta, “tende” a dar a resposta mais popular. Se esse dado desaparece, também desaparece a relevância de diversos novos assuntos. Agora, cada LLM vai depender de usar as perguntas feitas ao chat como novo dado de treinamento, só que a OpenAI só vai ter perguntas feitas pra ela, e ela não vai saber quais são as perguntas mais populares feitas no Claude, o que diminui cada vez mais as fontes de informação relevantes.
O que toda plataforma deve estar fazendo agora é coletar todas as perguntas que você faz a elas, todas as respostas que a LLM gerou, todo o feedback que você ou suas ferramentas dão sobre se foi sucesso ou erro, e vai acumulando isso pra usar pra treinar a próxima versão, o GPT-6 ou o Sonnet-5. Vamos ver o quanto dá pra evoluir só com isso — lembrando que o “volume” de informação não se iguala à “qualidade” pro treinamento. Esse ainda é o calcanhar de Aquiles.
O ponto é: pelo menos temporariamente, a maior parte dos dados relevantes na Web acabou, e estamos produzindo menos do que antes.
Restrição == Inovação
Sim, eu também acredito que uma categoria inteira, que se autointitulava “engenheiro de software”, vai deixar de existir por causa das IAs.
Não vai mais existir aquela “especialização” esquisita de “front-end que não mexe em nada de back-end” ou de “back-end que não mexe em nada de infra”. Front-end, em particular, é o mais fácil de substituir, pois era um grande volume de código de baixo valor agregado, com muita duplicação. Não era difícil automatizar, mas ninguém queria: era mais “legal” ficar inventando novos frameworks toda semana que fazem a mesma coisa, com formas levemente diferentes. Finalmente acabou essa palhaçada.
Palestrei anos sobre Restrição == Inovação e como inovação não acontece quando se tem dinheiro sobrando, que foi o que aconteceu na última Bolha de Programação: pra que automatizar as coisas, ser eficiente, se tem dinheiro sobrando, é só contratar mais e mais gente pra fazer coisas mais e mais simples e braçais?
Na Bolha da Internet, havia tanto dinheiro sobrando que existia a profissão de “catalogador de sites”: gente que ficava o dia inteiro digitando manualmente todos os novos sites que surgiam na recém-lançada Web. Levou anos até surgirem um Altavista e, depois, um Google, que descobriram como automatizar isso. Antigamente, não existiam “admins” web pra publicar novos produtos num e-commerce: alguém editava o HTML da página principal do Submarino.com todos os dias, com novas ofertas. Tudo trabalho de alto volume e baixo valor agregado. Automatizamos tudo isso e, agora, com LLMs, só fomos um passo à frente.
Mesmo antes de LLMs, não fazia sentido precisar de gente exclusivamente pra ficar fazendo HTML/CSS descartáveis o dia todo. As ferramentas um pouco mais automáticas, como um SquareSpace.com da vida, não eram tão boas.
O problema é o seguinte: algo simples, como um “Web Admin” pra editar conteúdo sem precisar saber HTML, nos anos 90, não existia. Alguém precisou criar as primeiras versões desse tipo de software pra entendermos o que funciona e o que não funciona. Quem era dos anos 90 vai se lembrar de softwares comerciais caros como o famoso Vignette Story Server. Hoje em dia, qualquer Wordpress open source faz a mesma coisa melhor.
Ninguém se lembra de software e de empresas que não existem mais. Especialmente jovens, acham que o mundo já apareceu com a Web pronta, com redes sociais prontas e plataformas de e-commerce prontas. A sensação deve ser que, no Egito Antigo, o povo já comprava na Amazon, pedia delivery no iFood e todo mundo se comunicava pelo Whatsapp. Eu fiz um video chamado A Dimensão do Tempo, Minha Máquina do Tempo e Meus Primeiros Cinco Anos pra tentar dar um pouco de perspectiva sobre isso.
O ponto é: tudo o que as LLMs sabem fazer já existe ou já existiu.
Eles não são capazes de inventar seja lá o que for, seja a “Vignette dos anos 2030” ou o “Instagram dos anos 2030”. E não digo isso no sentido do “próximo gerenciador de conteúdo” ou “próxima rede social”. Eu digo no sentido de que “rede social” era um termo que não existia nos anos 2000 e “gerenciador de conteúdo” não existia nos anos 80, por exemplo. O que é a nova categoria que vai aparecer nos anos 2030?
Não sei; se eu soubesse, obviamente estaria construindo pra lançar e ficar bilionário. Ninguém sabe, muito menos LLMs. Elas conseguem derivar muitas coisas do treinamento, mas o que não está nas probabilidades do modelo não vai “espontaneamente” aparecer”. Não é assim que IAs funcionam.
Podemos ficar pra sempre só refazendo tudo o que já foi feito igual já existe hoje. Mas não muito mais do que isso. Mas o ponto das minhas palestras foi justamente que somente com muito dinheiro e muita força bruta, não nascem inovações.
Programadores na Era das LLMs
A conclusão é muito simples: programadores como eu sempre vão existir. O que sempre deixa de existir são profissões que só têm volume, mas baixo valor agregado. Esse é o conceito.
Como disse nos meus videos, durante minha carreira eu já sobrevivi ao fim da bolha dos microcomputadores no começo ao meio dos anos 90, a bolha da internet do meio dos anos 90 até o começo dos 2000, a recessão de programação de 2001 a 2008, a bolha financeira imobiliária que estourou em 2008 mas deu origem à bolha da programação, principalmente dos anos 2014 até 2022, e agora a bolha de IAs.
Não se enganem: é sempre assim, e esse é nada mais do que um episódio.
Quem é o programador que sobrevive a todas essas bolhas? Este:
O teto das LLMs já está aqui e o que elas estão entregando agora não vai mudar muito: o processo vai ser o mesmo. Vai ficar um pouco mais rápido. Vai gerar um pouco menos de erros e pequenos ajustes assim. Mas o processo vai continuar igual até aparecer alguma nova arquitetura ou alguma nova descoberta que ainda não sabemos.
Nenhum código gerado por IA vai ser automaticamente perfeito pra ser colocado em produção sem nenhum tipo de revisão ou intervenção humana. - Qualquer um que ache o contrário ou que não testou nenhuma LLM na prática ou nunca trabalhou em projetos de verdade.
Como disse no Flow, esta é a SEGUNDA Bolha de IAs. A primeira foi nos anos 60 por causa do inventor de redes neurais, Frank Rosenblatt. Assim como o Sam Altman ou o Dario Amodel, ele também fez MUITO hype sobre redes neurais e computadores que iriam ficar muito mais inteligentes do que seres humanos “muito em breve”, e todo jornal da época publicou sobre isso. As promessas morreram como promessas e isso gerou o “Inverno das IAs” nos anos 70, onde muito investimento foi feito, o resultado não foi proporcional, e pesquisas sobre IA estagnaram pelas décadas seguintes, andando a passos de tartaruga.
Isso só começou a mudar mesmo com o advento e a popularização da Web, o surgimento de redes sociais, o surgimento de Big Data e, agora, com volumes grandes de dados pra iniciar uma nova era de pesquisa em redes neurais, com muito mais material de treinamento. E agora com a existência de GPUs pra acelerar o processamento. Foi quando surgiu a AlexNet, de George Hinton, Yann LeCunn e Ilya Sutskever, o “breakthrough” das convolutional neural networks (CNNs) e da paralelização de processamento via GPUs.
Sem isso, não se evoluiria pra transformers, difusores e coisas como Nano Banana e Sora. Esse é um tipo de área em que LLMs não vão contribuir: pesquisa de ponta e novas descobertas. Nesse campo vão continuar sendo necessários cientistas da computação, matemáticos, físicos teóricos, etc. Se você tem vocação pra pesquisa, ainda vai ser uma área fértil por muitos anos. A régua só subiu, o que é bom.
Sobre o Claude que conseguiu fazer um compilador de C:
O compilador de C é o mais fácil de fazer; é literalmente matéria de faculdade, porque C é uma das linguagens mais “simples” (começou como macros de Assembly).

Como o próprio artigo da Anthropic — que ninguém leu, lógico — diz, eles usaram o GCC pra comparar.
Claro, GCC existe; é o compilador principal pra compilar o kernel do Linux. Se você copiar o GCC, vai chegar em outro GCC, não importa em que outra linguagem escrever — essa não é a parte difícil, porque toda linguagem consegue fazer tudo o que outra linguagem faz (todas são Turing Complete: pode ser mais lenta, pode ser mais insegura, pode dar mais trabalho, mas eu posso fazer um compilador de C em Visual Basic, se eu quiser, não é impressionante).
Nenhuma LLM substituiu o Linus Torvalds, nem Richard Stallman, nem nenhum dos grandes programadores cujos nomes você já ouviu falar. Eles conseguem copiar o que já foi feito e só. Sim, eles são “stochastic parrots” (papagaios estocásticos), independentemente do que um George Hinton tente propagandear a seu favor (todos têm vieses). Aliás, como eu já disse nos podcasts: foda-se George Hinton. Parem de cair na Falácia do Apelo à Autoridade.
Recado às Empresas
Isso deveria ser óbvio, mas vou deixar registrado só pra poder dizer “EU AVISEI” depois.
- Nenhuma LLM vai escrever código sozinha. Precisa de um sênior pra especificar.
- Todo código gerado por LLMs precisa de revisão. Precisa de um sênior pra revisar.
- Uma parte do código gerado precisa ser reescrita. Precisa de um sênior pra saber.
- Outra parte do código vai ter bugs que a LLM vai deixar passar. Precisa de um sênior pra saber.
- Sabendo quais são esses bugs, dá pra LLM consertar.
Isso dito, algumas coisas que LLMs fazem muito bem:
- Análise exploratória de código legado
- Refatorar partes de código legado
- Adicionar testes unitários em partes de código legado
- Sugerir melhorias em partes de código legado
- Achar alguns buracos de segurança ou performance em código legado
Note como eu digo “partes” ou “alguns”. Não há garantia de que ele consiga fazer isso em qualquer legado ou parte. Novamente, precisa de um bom sênior avaliando cada passo.
Tudo é feito PASSO A PASSO. Uma tentativa, uma checagem, um ajuste, repita. É o famoso ciclo PDCA: Plan, Do, Check, Act. Esse é o processo que funciona. Cada novo ajuste testado vira um “git commit” e vamos ao próximo passo. Sempre um passo de cada vez, sistematicamente, organizadamente. Nunca algo genérico como “Conserte tudo neste sistema legado”.
Outra coisa em que LLMs são muito boas é reescrever código de uma linguagem para outra (traduções em geral). Mas não recomendo e nem é só por ser LLM:
Eu nunca recomendo reescrever do zero como primeira opção.
Não existe garantia de que uma linguagem mais nova seja “melhor” do que uma mais antiga. O “melhor” sempre “depende” da sua definição de “melhor”.
Está na moda essa ideia de reescrever tudo em Rust porque teria menos problemas de segurança. Isso é incorreto. Rust é bom para algumas categorias de segurança, mas não pra todas. E existe toda uma categoria de problemas funcionais que não aparecem em nenhum compilador. Reescrever algo complexo, como um kernel do Linux, em Rust é uma ilusão e uma inutilidade enormes. Se “parece fácil” fazer uma LLM reescrever em Rust, é igualmente fácil ela consertar pontualmente um errinho em C também, sem mexer no resto que já funciona.
Reescrever é, sim, garantia de que vários novos bugs vão surgir e você não vai detectá-los imediatamente; vai ser uma nova bomba-relógio. Pra consertar um bug conhecido, você acabou criando vários outros bugs desconhecidos. Reescrever, por definição, sempre vai adicionar novos bugs.
E não, quando se pede pra LLM: “encontre todos os bugs de segurança neste código”, ele vai encontrar alguns, mas nunca todos.
Entenda o português: ele sempre vai dizer algo como “Eis todos os bugs que descobri…” Até a LLM hoje em dia não vai mais tentar dizer “Eis todos os bugs que existem”.
Nenhuma IA é feita pra dar respostas 100% corretas e sem ambiguidade. Pelo contrário, é sempre uma máquina probabilística que vai dar a resposta com base nas probabilidades do modelo gerado pelo treinamento. O que não estiver nesse modelo, ele não sabe. E, mesmo dando contexto, não há garantias de “entendimento completo”, e sim de “algum entendimento”. Sempre trabalhe com probabilidades inferiores a 100%.
Linguagens de programação, por sua própria natureza, não são determinísticas. Não existe nenhuma forma de escrever uma equação matemática em que eu possa passar o programa e ele garanta a ausência de bugs. Isso é uma impossibilidade matemática; não é “questão de tempo”. O tempo não tem nenhuma relevância nessa definição.
A detecção de bugs (funcionais, de segurança, de performance, etc.) é sempre um processo estocástico, uma heurística, nunca um algoritmo. Isso é algo que todo cientista da computação ou matemático entende, mas ninguém que nunca estudou consegue entender. Para pessoas comuns, heurística é a mesma coisa que algoritmo. Esse é um erro que pode ser fatal.
Então, toda LLM, por sua própria fundação e arquitetura, sempre vai ter essas e outras limitações embutidas. Mas isso não é um problema, é apenas a natureza da ferramenta. Martelos não servem pra girar parafusos, e isso não é um defeito. Deveria ser óbvio, mas bater um martelo num prego e não girar é uma característica natural. Não é nem uma vantagem nem um defeito. Depende de qual problema quer resolver.
No geral, LLMs vão ser muito boas em lidar com trabalhos braçais: adicionar testes, refatorar código, ajustar front-end, criar telas novas a partir de telas antigas, criar relatórios novos a partir de relatórios antigos. Criar tradução do português para o espanhol das telas do seu sistema. Pra esse tipo de prego, LLMs são o martelo perfeito.
Agora, interpretação exata de leis, regras de negócio, casos individuais e exceções à regra, flexibilização de certas regras — tudo o que faz parte das tomadas de decisão numa empresa. Nunca confie totalmente em nenhuma LLM: vai precisar de um humano experiente pra aprovar ou rejeitar. Por mais que ele tenha memorizado todas as leis do país, não há garantia de que saiba quando usar ou não usar, e como isso pode variar nos mais variados casos, especialmente nas exceções.
Nunca pergunte a um martelo como você deve dirigir sua empresa.
“Como ter sênior se não vai mais ter júnior?”
Notem que a premissa é que, no mínimo, sempre vão precisar de um sênior instruindo e revisando o trabalho das LLMs.
Mas se as LLMs conseguirem executar todas as tarefas braçais que antes eram destinadas aos estagiários e júniors, como vão crescer pra virar sênior?
É a pergunta de 1 bilhão de dólares e já adianto que eu não sei a resposta inteira. Ninguém sabe.
O início é fácil. É como eu disse em todos os vídeos do canal: é como fiz minha carreira inteira: ter uma boa formação e “aprender a aprender” de verdade. Mais fácil falar do que fazer; por isso, levei 5 anos de vídeos tentando explicar dos mais variados jeitos pra ver se alguém entende.
A próxima parte que é difícil: como aprender se as LLMs já fazem tudo?
Essa pergunta parte de uma premissa errada: as LLMs não fazem tudo. Elas fazem o que for pedido. Se o pedido estiver bem especificado, vai sair um prato gourmet de um restaurante com 3 estrelas Michelin. Se o pedido for tosco, de alguém claramente inexperiente, vai sair um miojo. É assim, simples.
O resultado da LLM é diretamente proporcional ao trabalho de instrução, avaliação e acompanhamento do humano no controle.

“Como alguém vai ser programador se nem sabe como fazer pra perfurar um cartão?” - É uma pergunta justa se perguntar a alguém nos anos 60.
“Como alguém vai ser programador se nem sabe gravar numa fita cassete?” - É outra pergunta justa se for alguém dos anos 80.
“Como alguém vai ser programador se nem sabe editar código num editor de textos como Emacs e precisa de Eclipse?” - Outra pergunta justa, se for alguém dos anos 90.
“Como alguém vai ser programador se nem sabe programar pra Web?” - Uma boa pergunta pra alguém no começo dos anos 2000.
“Como alguém vai ser programador se sequer sabe fazer um app mobile?” - Se for alguém nos anos 2010.
¨Como alguém vai ser programador se tem LLMs?" - A pergunta dos anos 2020. Boa sorte.
Toda geração tem perguntas similares. Nenhuma tem uma solução exata. Veja os fatos: ainda estamos aqui. Em 2026, sei coisas de programação que nunca sonhava saber quando entrei na faculdade em 1995. Tudo mudou. Todo mundo que “aprendeu a aprender” soube se ADAPTAR e usar o conhecimento que já tinha pra aprender novas formas de trabalhar.
É tudo uma questão de adaptação: quem não se adapta é extinto. Essa é a lei.
Não tem muito mais a dizer a respeito disso. Mas na prática:
Se você é programador, use LLMs. Aprenda os pontos fortes e fracos, os diferentes resultados que ela obtém dependendo do seu próprio conhecimento, e nunca pare de estudar e treinar.
Se você é sênior/empresa, continue contratando júniores. Seus sêniores não são imortais. No mínimo, em uma hora eles vão se aposentar. Mais realista: uma hora eles vão mudar de emprego. A segunda tarefa mais importante de qualquer sênior é mentorar júniors e criar substitutos. Sênior incapaz de criar seu próprio substituto não é um sênior, é uma liability.
Mentorar é a mesma coisa de sempre: treinamento com acompanhamento e feedback, melhoria contínua, com a diferença de que, além de sistema operacional, editor de texto e IDEs, sistemas de CI, etc., agora tem LLM na caixa de ferramentas. É isso. Não tente complicar o que não precisa e não sofra por antecedência.
Conclusão
“Ain, mas você falou que a bolha das IAs vai estourar.”
Sim, e continuo dizendo. Mas você está entendendo errado, novamente. De 1994 a 2001 existiu a Bolha da Internet, e ela estourou!
Entenda: a “Bolha da Internet” estourou. Mas a “Internet” continua existindo até hoje. ¿Está claro?
Mesma coisa: a “Bolha das IAs” vai estourar, muitas empresas vão falir, muita gente da área vai perder o emprego, etc. Mas IAs vão continuar existindo. A bolha das IAs dos anos 60 estourou, mas as IAs continuaram existindo e até formaram uma nova bolha agora. Ciclo econômico não tem a ver com ciclo tecnológico.
Só quer dizer: “não aposte todas as fichas no mesmo cavalo, especialmente se sua vida/carreira depende disso.”
LLMs vão continuar existindo, aproximadamente no mesmo formato, um pouco mais rápidas e eficientes, mas com o mesmo processo por trás e a mesma forma de trabalhar. Assim como a Web de 2026 não é muito diferente da tecnologia dos anos 90, mas é mais refinada e otimizada.
Eu nunca fui “hater” de IA, pelo contrário, sou um que já arriscava fazer código com o GPT-2. E sempre está melhorando. Agora está num ponto em que é fácil recomendar até pra não-programadores brincarem com sistemas que não vão pra produção nem são de missão crítica.
Desde que comecei com programação, no fim dos anos 80, felizmente nunca tive um único momento em que achei nossa área “entediante” ou “monótona”. Pra mim, é só mais um capítulo nessa história, e eu tenho expectativa de novos capítulos.
O que eu falo que “parece hate” é só argumentação e explicação das limitações atuais e das expectativas irreais, ilusões ou até apostas cegas em que sei que não vão vingar. Estou avisando do que é real. Mas sempre estou dizendo: “precisa haver uma nova descoberta”. Com a expectativa de que algo mais vindo no futuro, e não de que “não vai dar nada certo”.
No final do dia, o Java dos anos 90 não substituiu o Cobol e o Fortran do mundo, como se pretendia. A Web não virou uma utopia pacífica de puro conhecimento como se queria. O mobile não substituiu outras formas de computação, como se queria. VR não se tornou a nova onda. Nada disso invalida as qualidades do Java, da Web, do Mobile ou até da VR.
A última Bolha da Programação foi um período entediante pra mim em termos de inovação: porque tudo era substituído por programadores baratos. Pra mim, o estouro dessa bolha era esperado e me deixa muito feliz. Porque finalmente saímos do marasmo de cursos idiotas pra falarmos de tecnologia de ponta de novo. Programadores voltando a ser programadores de verdade.
Só vejo coisas boas nisso.