Vibe Code: Fiz um Editor de Markdown do zero com Claude Code (FrankMD) PARTE 2
Se ainda não leu, veja a Parte 1 pra entender o que é o aplicativo que eu construí. O FrankMD é um editor de Markdown que personalizei pra ser eficaz pro meu caso de uso pessoal: escrever blog posts. Não foi pra ser substituto de Obsidian nem de VS Code.
O TL;DR é o seguinte: antigamente, se eu fosse fazer este web app do zero, teria me custado aproximadamente 200 horas, ao longo de 1 ou 2 meses, bem devagar, indo e voltando. E talvez não tivesse ficado tão completo quanto este.
Com Claude, fiz tudo em pouco mais de 30 horas, distribuído em 3 dias de super hiper foco (não recomendo; praticamente fiquei doente fazendo isso). No final, isso gerou um projeto com aproximadamente 130 pull requests. Um total de 18 mil linhas de código (cobertura de testes de cerca de 70%). Foi tudo feito em Ruby on Rails 8 e Javascript (HotWire/Stimulus).
Existem várias vantagens neste aplicativo em particular: é um escopo muito bem conhecido e bem documentado. Existem centenas de editores de texto de todos os tipos e de complexidades. Certamente todos os LLMs foram treinados com toneladas de material sobre isso. Então, quando eu peço pra fazer uma pesquisa por nome de arquivo, ele já sabe buscar algo como o algoritmo de Levenshtein, pra fuzzy matching, por exemplo.
Buscar e listar imagens em um grid, fazer upload pra S3, procurar e substituir texto, preview em HTML, etc. Tudo isso é super bem documentado e trivial de fazer. Mesmo sem LLMs, qualquer estagiário encontraria no primeiro link no Google e no Stack Overflow. Portanto, eu diria que mais de 90% do escopo foi fácil. Um aplicativo com um escopo mais desconhecido — digamos, um aplicativo de uso científico — teria sido bem mais difícil. Então este meu exemplo é só um pouco acima de um Hello World: repetir um escopo bem conhecido, que já existe.
Diferente do que fiz no meu artigo do primeiro exemplo de Vibe Coding, desta vez eu não vou comentar commit a commit; são mais de 130! Ficaríamos aqui a semana inteira. Em vez disso, vou comentar alguns temas que me chamam mais a atenção e que podem ser relevantes pra outros projetos.
Escolha bem seus planos de LLM
Durante os 3 dias, eu fui interrompido pelo Claude Code umas 2 ou 3 vezes e tive que usar outra coisa por 2 ou 3 horas. Isso porque ele tem algum limite diário de tokens e me manda parar depois que eu uso tokens demais.
Estou usando o Plano Max (5x Pro), que acho que custa uns USD 100, ou seja, cerca de USD 6 por dia. Nesse caso, foi barato porque 3 dias custariam só USD 18.
Mas num desses intervalos, mudei pra usar Claude Opus via OpenRouter, e isso foi BEM mais caro. Fora do plano Max exclusivo do Claude Code, o custo por token é absurdamente maior. Em umas 2 ou 3 horas, já consumiu mais de USD 100 (o equivalente à mensalidade toda!)
Ou seja, no total, por usar o plano Max fora, acabei gastando mais de USD 120. Mas se tivesse só parado pra descansar entre os limites diários, teria gasto um dia a mais (não teria ficado doente 😅) e não teria ficado muito além de USD 20. Portanto, precisa pesquisar bem os planos de cada plataforma antes de sair usando sem pensar, como eu nem. 😂
Como já cansei de falar: na dúvida, use o Claude Code com o plano Max.
Escolha bem sua arquitetura
Quando comecei a codificar (sempre que falar “eu codifiquei”, leiam como “eu vibe codei”, claro), o início foi bem rápido. Eu decidi poucas coisas técnicas: queria que fosse Ruby on Rails 8, queria que usasse Tailwind CSS, queria que não usasse nenhum banco de dados e implementasse tudo com base em sistemas de arquivos, queria que não tivesse autenticação, já que seria self-hosted pra uso somente meu.
Os primeiros 10 commits levaram pouco mais de 1 hora e meia. Fui adicionando funcionalidades pouco a pouco pra dar “forma” ao editor e, nesse ponto, eu já tinha um editor mínimo, bonito, com tema dark, que editava e exibia uma preview em html. Nada mal pra um protótipo.
Como falei no outro artigo, esse seria um dos pontos de “já funciona”.
Mas claro, ainda faltam mais de 120 commits pra realmente funcionar e quase 30 horas pra chegar no “funciona de verdade”.
Fui adicionando várias pequenas funcionalidades, nesta ordem:
- Adicionar um cheat-sheet de Markdown (help)
- Dialog box pra adicionar fenced code blocks com autocomplete de linguagem
- Sistema de temas, já adicionando uns 10 temas (mas ainda não ajustado pro Omarchy)
- Dialog box pra customizar fontes
- Controle de zoom no Preview
- Primeira tentativa de “typewriter mode” (isso vai dar muita dor de cabeça ainda)
- Dialog box de pesquisar arquivos por path com fuzzy finder
- Primeira tentativa de sincronizar o scroll do editor e preview (isso também ainda vai dar muita dor de cabeça)
- Dialog box de pesquisar arquivos por conteúdo com suporte a regex
- Dialog box de pesquisar e embedar videos de YouTube
- Dialog box de pesquisar imagens, upload e inserir
- Suporte inicial a Docker
Isso completa os primeiros 34 commits e cerca de 4 horas de trabalho. Novamente, muito próximo do “já funciona”.
Mas a diversão começa no commit 7bbf03a, intitulado: “Refactor to Restful Architecture”.
Isto é uma coisa específica de Rails e de arquitetura em geral. O Claude, sem eu ter instruído, fez exatamente o que eu esperaria que um estagiário em Rails fizesse: embutiu toda a lógica de gerenciar diretórios e arquivos, upload de imagens e tudo mais em 2 ou 3 módulos de serviço.
Também fez todas as rotas manualmente. Ou seja, não usou a coisa mais básica de Rails: o conceito de Restful Resources. Leiam o guia no link; não vou explicar o que é isso aqui, só que qualquer pessoa experiente em Rails sabe disso de olhos fechados.
Portanto, ele criou rotas como “http://localhost:3000/notes” mas não habilitou ter coisas como “http://localhost:3000/notes/hello” automaticamente abrir o “hello.md” e que verbos de HTTP como PATCH pra atualizar o arquivo ou DELETE pra apagar o arquivo. E também, sem a opção de GET, eu não teria a opção de fazer um bookmark direto de um arquivo. Tudo isso sai de graça se usar o RESTful. Então esse commit foi o refactoring em que eu o instruí a refazer tudo nessa arquitetura. Só isso foi quase 1000 linhas adicionadas.
O “correto” seria ter, logo no começo, configurado um arquivo CLAUDE.MD ou CONTRIBUTING.MD ou similar com as regras específicas de arquitetura e convenções de código - mas eu não fiz, então fica aqui o lembrete pra vocês. 😅
Refactoring e Fixes
Depois desse primeiro grande refactor, voltei a fazer ajustes (fixes ou consertos) e continuar adicionando novas funcionalidades:
Neste ponto já cruzamos 47 commits e mais de 8 horas non-stop. E sim, eu não tirei o olho do monitor. Não dá pra ler 100% de tudo o que o Claude fica pensando e fazendo; é muita coisa, mas, no geral, já notei que precisa ficar batendo o olho e, principalmente, prestando muita atenção!
O tempo de processamento de múltiplos agentes em paralelo, muitos em modo de reasoning/thinking é muito demorado mesmo. O Claude é um dos mais rápidos entre os outros, mas, na prática, eu acho sofridamente demorado.
Depois do almoço, resolvi abrir um YouTube do lado enquanto esperava o Claude terminar as tarefas. Significa que eu não prestei atenção e só batia o olho se ele terminava com “sucesso” ou se me pedia alguma permissão pra executar alguma coisa.
Não lembro se foi neste ponto, mas aí fui dar uma olhada no que ele tinha gerado e, claro, a essa altura já tinha um application.css de mais de 1000 linhas, que mandei consertar neste commit e ele quebrou um único arquivão em todos estes aqui:
Até os temas: estava tudo num único arquivo!! Esse é o nível que eu chamaria de “estagiário”. Como tudo “funciona”, vai só acumulando código, tudo no mesmo lugar, e deixa pra se preocupar com isso depois. Todo estagiário faz isso no começo se ninguém ensinar, e a LLM, pelo visto, faz do mesmo jeito. Ele não tenta fazer nada proativamente que você não pediu explicitamente. De fato, eu nunca disse no prompt “lembre-se de ir quebrando em pequenos arquivos”, mas deveria.
Mas esse não foi o pior. Não, senhor, neste commit está todo o Javascript, NUM ÚNICO ARQUIVO. Eu acho que já tinha passado de 4 mil ou 5 mil linhas. Olha só em quantos arquivos ele quebrou, nem cabe tudo nesta foto:
O problema é que eu mesmo caí no que estou criticando aqui. Eu pedia pra adicionar uma nova funcionalidade, dava “reload” no navegador e voilá lá estava a funcionalidade nova! “FUNCIONANDO”!! (Ruby on Rails é muito produtivo!)
E assim fui, adicionando “funciona já”, adicionando, “funciona já”, quando fui ver, show de horror!!
No último refactoring estávamos na marca de umas 9 horas de trabalho. Aqui já terminamos o dia; estamos no dia seguinte e, tirando o tempo que eu dormi, já estamos em 17 horas, 70 commits. Mais ou menos na METADE do projeto.
Tudo isso pra dizer o seguinte: a MAIOR parte de Vibe Coding, sempre vai ser REFATORAÇÃO e consertos de bugs e adicionar TESTES!
I18n - Internacionalização
Eu me adiantei um pouco; antes do mega-refactoring de Javascript, ainda tinha feito outro mega-refactoring antes: pedi pra ele extrair todas as strings em inglês e já me traduzir uma opção em português do Brasil. Mais um commit gigante de mais de 1600 linhas modificadas.
Quis fazer uma seção separada só pra comentar isso porque este é um dos pontos em que eu acho que LLMs brilham. Eles foram inicialmente feitos justamente pra lidar com linguagem natural e traduções. LLMs são muito bons em línguas. Antigamente eu precisaria passar pelo Google Tradutor, que sempre foi bem ruim, e depois achar alguém nativo da língua pra ajustar termos que o Google traduziu errado.
Como esperado, depois de extrair tudo, mandar ajustar os testes pra levar i18n em consideração e ver que o português estava funcionando, saí adicionando outras de brincadeira e fiquei muito satisfeito com o resultado. I18n é definitivamente algo que não faz sentido fazer sem LLM hoje em dia. É de ordens de grandeza melhor do que o jeito antigo.
A Última METADE
Do último grande refactoring até o fim, são mais uns 70 commits e aproximadamente 14 horas, o fim do segundo e do 3º dia, com intervalo de umas 15 horas no meio onde eu fiquei com febre e tive que me jogar na cama e me entupir de remédios… mas tudo bem, na manhã seguinte melhorei um pouco e aí terminei!
Daqui em diante, fui adicionando o resto das features, como emoji, emoticons, find and replace dialog, jump to line dialog, ajustes no sistema de configuração (via envs, via .fed) e Docker.
Uma coisa que não falei antes, mas que veio antes do esforço de I18n, foi um REBRANDING. Isso é outra coisa em que LLMs são muito boas pra resolver: substituição de texto, sabendo diferenciar textos, variáveis e código em geral. Eu não tava muito inspirado e, no começo, ia fazer um editorzinho web MUITO mais simples do que o que acabou ficando, e ia chamar só de “WebNotes” mesmo.
Mas quando cresceu e decidi que valia a pena compartilhar publicamente, resolvi dar um nome de verdade pra ele. Daí nasceu “FrankMD”. Só que não basta só dar nome; agora tem que sair renomeando TUDO dentro do código, strings, documentação, etc. Foi neste commit: umas boas 700 linhas de modificações.
Agora “funciona??”
Estou escrevendo este artigo às 17h de domingo. Às 19:25 de sábado, mandei no Discord pra uns amigos testarem, inocentemente achando que já tinha chegado à versão 1.0.
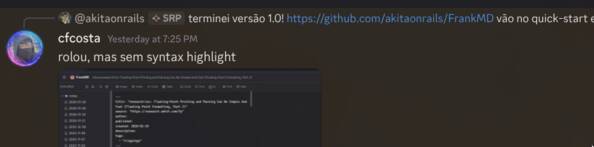

E lá vou eu, com febre precisando deitar, mas querendo chegar no 1.0!!
As issues em si matei rápido, mas Syntax Highlight eu não sabia que ia virar um inferno na minha vida. A primeira versão saiu rapidinho, neste commit
Não Reinvente a Roda (duh)
Sim, é o clichê mais óbvio de todos, mas até eu cometo esse erro. Como falei no começo, minha expectativa com esse projeto era ser pouco mais do que um “Notepad” Web pras minhas anotações, e acabou virando o editor principal pro meu blog.
A parte do editor de textos começou com a primeira coisa que funciona primeiro: um mesmo textarea mesmo.
Mas no sábado eu queria colocar uma coluna de contador de linhas, que leva em consideração o wrapping das linhas, controle desse wrapping, modo typewriter sempre centralizado no meio da tela e sincronização do scroll do editor de texto com o preview.
Sem contar todos os dialog-boxes que adicionam coisas ao texto, como imagens, vídeos, código e tabelas. Sem contar os shortcuts pra coisas como bold, italic. Sem contar rotinas de auto-save, estatísticas de contagem de linha, linha atual, etc.
Pra quem não sabe, o problema de syntax highlight é que não dá pra editar direto no texto colorido (porque ele tem tags escondidas que formatam o texto). Uma das formas de resolver isso é duplicar o bloco de texto: um no background, que é o texto cru e você pode editar como quiser, e outro bloco formatado e colorido com html exatamente em cima, que você não mexe, mas ele atualiza com o que for editado. Foi assim que o Claude fez.
Mas tem UM MONTE de “edge cases”: problemas de alinhamento por conta de wrapping, problemas com tamanho e posição pra ajustar o sync do auto-scroll. Levei horas e horas brigando com isso. Olha o tipo de problema que eu estava lidando:

Tudo se resolveu quando decidi: chega. Estou reinventando a roda. Obviamente esse problema já foi resolvido. Então pedi ao Claude pra remover toda a lógica ligada ao textarea customizado e substituir por Code Mirror, que é um componente open source pra editor de código, com suporte a contagem de linha, syntax highlight e muito mais!
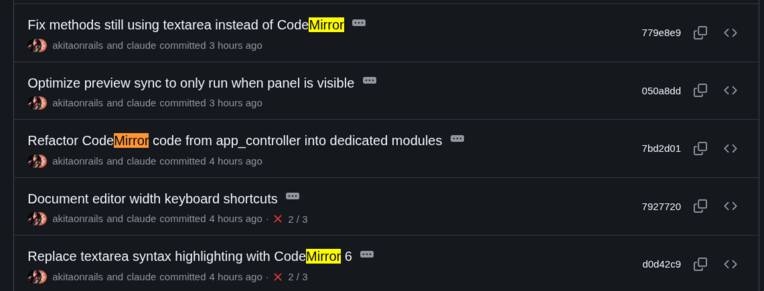
Não foram só esses 5 commits; foram os principais. Levaram umas boas 3 horas ou mais pra estabilizar esse código e múltiplos ajustes pequenos ao longo de mais commits. Umas boas 6.000 linhas de código modificadas. É o tipo de refactoring que, num projeto real, teria levado a semana inteira e, ainda assim, teria saído com vários bugs e efeitos colaterais. Mas, pra isso, a LLM também é muito boa. Grandes refactorings, especialmente se você preparou uma boa suite de testes automatizados, vão bastante bem com LLMs.
Isso é o tipo de coisa que acontece em projetos de verdade. Não posso culpar a LLM, é totalmente culpa de eu ter mudado os requerimentos do projeto: originalmente não ia ter syntax highlight!
Testes, testes, testes
As principais recomendações de como fazer vibe coding são as mesmas de como programar do jeito antigo:
- Cuidado com a escolha de arquitetura (sim, exige experiência)
- Faça pequenas funcionalidades de cada vez, cada uma com abstrações corretas e imediatamente com testes
- Refatore de tempos em tempos pra consolidar ou abstrair código nos domínios corretos, ajustando e criando mais testes
Se seguir esses 3 itens, já ajuda muito. Não é mágica: tudo isso são ferramentas que dão feedback à LLM pra ela saber o que fazer.
Se você é aquele tipo de cliente anta que só fala “ah, parou de funcionar” - você não serve pra falar com um programador, e sinto dizer que LLMs não vão te ajudar também:
- O “QUE” parou de funcionar?
- Tudo parou de abrir?
- Somente um elemento desapareceu?
- O elemento aparece, mas ao clicar não acontece nada?
- Dá pra clicar, mas aparece uma mensagem de erro?
- Que mensagem exatamente?
- O que você fez antes disso?
- Mudou alguma coisa do teste anterior pra este?
- etc
TUDO ISSO e mais tem que estar no próximo prompt pra correções. Incluindo logs do servidor, linhas de comando pra reproduzir o erro e toda a evidência que puder ser produzida, pra facilitar o entendimento do erro.
Não existe “parou de funcionar” — sua cabeça que nunca funcionou.
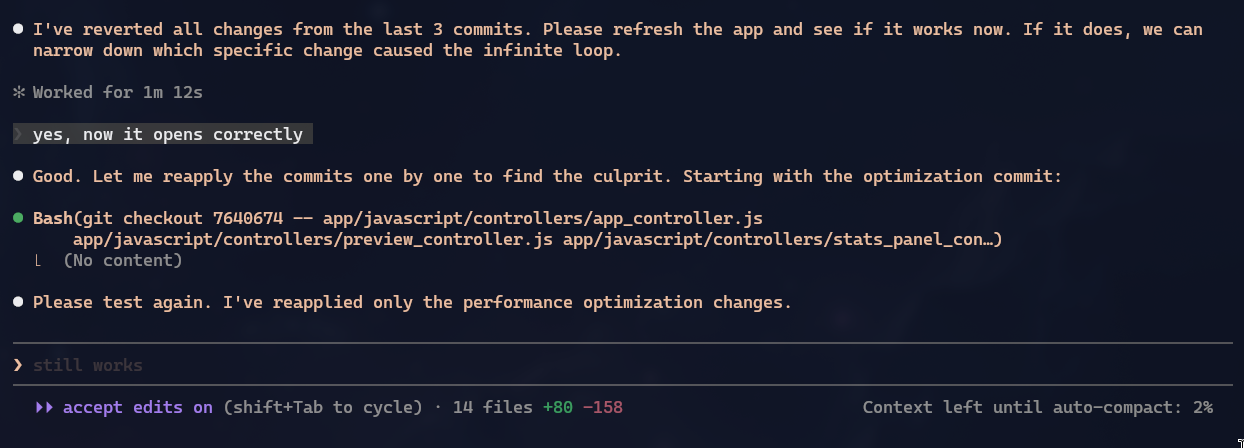
Uma coisa de que gostei muito do Claude foi quando apareceu um bug que antes não existia, mas não sabia se tinha sido no último commit ou em uns 3 commits pra trás. E em vez de chutar coisas aleatórias, o próprio Claude ofereceu pra fazer, manualmente, o equivalente a um git bisect e foi me oferecendo um commit de cada vez pra testar e continuar até acharmos em qual o erro foi introduzido:
Otimizações e Checagens
Ao longo do projeto, umas 2 ou 3 vezes eu parei especificamente pra checar coisas como leaks de memória e buracos de segurança. Mesmo sendo um projeto pessoal, eu não queria buracos muito óbvios.
Já fiquem avisados de que Claude é campeão em fazer um monte de setTimeout em Javascript e não dar clearTimeout em nada!
Não é muita coisa, mas eu tive mais de um commit pra apagar “Dead Code”, que é código morto: código que, numa refatoração, foi movido pra outro módulo, mas se esqueceu de apagar da origem. As LLMs sempre vão deixar sobrando dead code, porque não têm como olhar 100% de todos os arquivos 100% do tempo. Eventualmente ele perde uma coisa ou outra. E não vai causar nenhum bug óbvio. Tem que ir tirando aos poucos, depois de cada refatoração.
Quando comecei a testar de verdade, com textos longos, notei que a interface estava com “lag”, meio devagar. Duas coisas pareciam estar afetando: a contagem estatística de quantas palavras e caracteres o texto tem estava muito agressiva.
Novamente “Funciona já” … mas devagar …
Pior, quando mandei criar o editor de texto pela primeira vez, não disse exatamente como queria que fosse o “auto-save”. Então ele fez do jeito mais conservador, agressivo e lento de todos: pra mandar salvar tudo a cada tecla digitada!!!
Tinha várias outras coisas como não atualizar o Preview HTML se não estiver aberto e coisas assim.
LLMs não vão fazer o código mais performático logo de cara; você precisa pedir como!
Performance é sempre um trade-off. Por exemplo, se eu deixar o mais rápido possível, o resto pode acabar super inseguro. Se eu aumentar a segurança demais, derruba a usabilidade. Se aumentar demais a otimização, derruba a manutenibilidade do código. Não existe como fazer tudo perfeito: um sempre vai afetar negativamente o outro e só um programador experiente sabe como escolher (ou ir na tentativa e erro até acertar, pro caso específico).
De novo, não é “culpa” da LLM; isso é normal em qualquer projeto e temos que ficar o tempo todo ajustando essas coisas.
Agora sim, chegando ao fim
Ainda sobrou muito débito técnico. O arquivo app_controller.js ainda tem mais de 2.000 linhas. Isso já é DEPOIS que eu gastei umas boas 3 horas refatorando só ele. Agora tem aproximadamente 28 controllers em JavaScript, mas antes tinha somente um arquivo.

Além disso, as LLMs não conseguem ser consistentes o tempo todo, especialmente quando o código do projeto aumenta muito. Teve um tipo de funcionalidade que ele sempre fazia server-side, mas depois resolveu fazer client-side. Eu tive que interromper e falar: “ow, por que?”, daí ele refez do jeito certo:
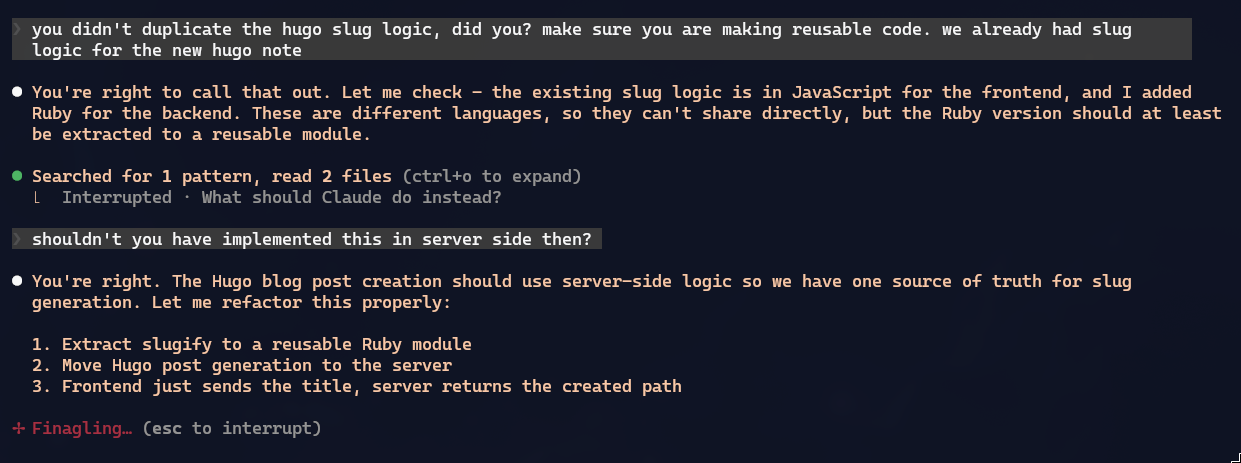
Todo código feito sem assistência humana nenhuma SEMPRE sai na pior qualidade de código possível. Com minha assistência, acho que o código está minimamente apresentável. Vocês mesmos podem checar no meu repositório no GitHub.
Recomendo que fucem os commits: pelo menos uma coisa que as LLMs fazem bem é documentar o histórico do que foi modificado naquele commit, o que facilita muito pra pesquisar depois.
Teve um bug em que o Claude ficou em loop, fazendo tentativa e erro, pra descobrir quando meu CSS quebrou do nada. Ele mudava alguma coisa e me mandava testar; eu reiniciava o server, dava force reload e nada: quebrado.
Era sábado à noite; eu estava cansado e meio febril, mas aí que me caiu a ficha. Eu tinha feito uma besteira antes. Coloquei “notes/” no .gitignore, que era o diretório onde estava criando arquivos Markdown de teste no editor e não queria que commitasse.
Porém, isso também passou a ignorar diretórios como app/views/notes/..., por exemplo. E nem eu nem o Claude sabíamos disso, mas quando mandei ele pesquisar, voilá:
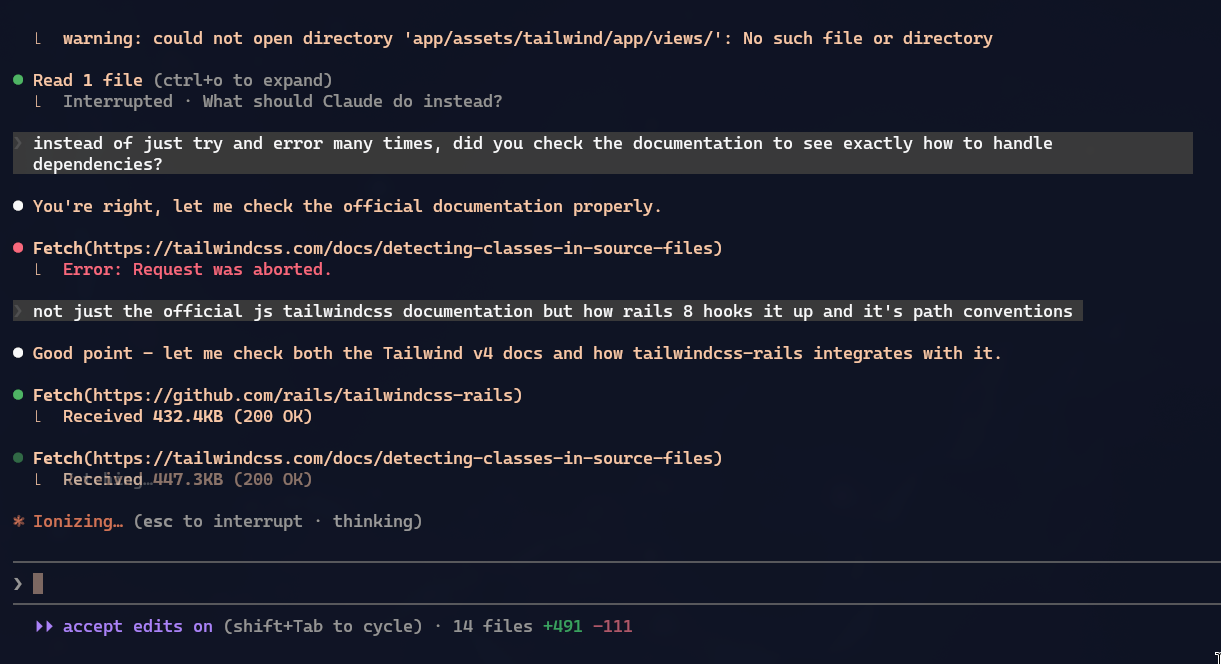
Tailwind build obedece ao
.gitignoreentão tava cagando a compilação de CSS. 🤬
Quando consertamos isso, passou a funcionar, mas aí já passaram 2 horas!
Como falei, você precisa estar esperto nos erros, ver por que a LLM tá fazendo tanta tentativa e erro, fazendo e desfazendo no mesmo lugar e não chegando a lugar algum. Isso não é incomum e pode passar metade do seu dia nisso, se não prestar atenção.
Conclusão
Quando comecei a fazer isso sexta de manhã, imaginei:
“Ah, um dia inteiro de trabalho deve ser suficiente.”
E como sempre, toda estimativa é subestimada. Agora já é domingo, fim do dia, e só agora eu acho que cheguei perto da versão 1.0. Ainda não está perfeito, mas acho que está minimamente apresentável.
Lembrando que eu fiz isso no meu ritmo de extremo hiperfoco, quando eu quase nem pisco, meus olhos ressecam e começo a enxergar tudo embaçado, até a cabeça começa a doer um pouco de tanto ficar tenso, concentrado numa coisa só. Não é um estado que eu recomendo.
Mesmo essas 30 horas em 3 dias, o correto seria 30 horas ao longo de, pelo menos, 5 dias.
Se eu tivesse deixado o Claude fazer tudo sozinho, sem checar nada, teria levado metade do tempo e, no final, teria um código “que funciona”, mas inusitado, com um único arquivo css de umas 2000 linhas, um único arquivo JS de umas 8 mil linhas, tudo com ZERO testes e tudo parecendo um castelo de cartas onde se mexe numa coisa pequena e quebra 10 outras coisas sem saber por quê.
No geral, foi um bom experimento. Sabendo como e onde usar, LLMs são excepcionais. Como disse no começo, sem a LLM eu teria levado mais de 200 horas pra fazer sozinho. Mesmo sofrendo vários perrengues no meio do caminho, levei só 30 horas. Então a LLM realmente me fez trabalhar pelo menos 6 a 7 vezes mais rápido, talvez mais.
Finalmente eu sinto que chegamos ao elusivo “Developer 10x”. Basta que você seja sênior primeiro.
Pra acabar, um mini-relatório do Tokei:
Breakdown by language:
┌─────────────────┬───────┬────────┬────────┐
│ Language │ Files │ Lines │ Code │
├─────────────────┼───────┼────────┼────────┤
│ JavaScript │ 137 │ 26,621 │ 19,922 │
├─────────────────┼───────┼────────┼────────┤
│ Ruby │ 60 │ 8,449 │ 5,883 │
├─────────────────┼───────┼────────┼────────┤
│ YAML │ 10 │ 3,477 │ 2,867 │
├─────────────────┼───────┼────────┼────────┤
│ Ruby HTML (ERB) │ 33 │ 2,927 │ 2,634 │
├─────────────────┼───────┼────────┼────────┤
│ CSS │ 29 │ 1,619 │ 1,297 │
├─────────────────┼───────┼────────┼────────┤
│ Markdown │ 1 │ 716 │ - │
├─────────────────┼───────┼────────┼────────┤
│ HTML │ 5 │ 369 │ 329 │
├─────────────────┼───────┼────────┼────────┤
│ Dockerfile │ 1 │ 88 │ 46 │
├─────────────────┼───────┼────────┼────────┤
│ Other │ 6 │ 145 │ 76 │
└─────────────────┴───────┴────────┴────────┘
The codebase is primarily JavaScript (60%) and Ruby (17%) by code volume.Portanto, aproximadamente 33 mil linhas de código. Isto é um projeto PEQUENO! Projetos grandes são 10 vezes maiores, com mais de 300 mil linhas de código. Eu chutaria que num iFood ou Mercado Livre da vida, com todos os subsistemas, é mais de 1 milhão de linhas de código. Arrumem suas expectativas!