Why LLMs Aren't Giving You the Result You Expect | Why I Prefer Claude Code Today

Every time I get pulled into an online thread about LLMs I hear the same chorus, in slightly different keys. “Claude didn’t perform as well as GPT for me.” “GPT did a way better job than Claude, I’m canceling my sub.” “Honestly, Kimi or MiniMax does the job for me just fine, I’m not paying for anything.” Anecdote piled on anecdote, each one a variation of “works on my machine” vs. “doesn’t work on my machine.” It sounds off to me.
I’ve already benchmarked most of the relevant open source and commercial models in my LLM testing post, so I’m not pulling this out of thin air. And beyond the benchmarks, I’ve got 500+ hours in Claude Code and Codex on real projects. 16 hours a day, two and a half months straight, something in the neighborhood of 400,000 effective lines of code generated.
And look: on neither of them, Claude or Codex, did I ever see the model wander off, do something I didn’t ask for, or flat-out fail to deliver what I wanted. Not once. When the model really couldn’t do something, it told me so upfront instead of inventing. So when someone tells me “Claude blew it,” my first question is always the same: what did you ask it for, exactly?
The fake problem
The ecosystem’s answer to this supposed “wandering off” problem is to pile on more layers. Spec Driven Development showed up, 15-section prompt templates showed up, whole frameworks to force the LLM to ask more questions before it starts. I respect the effort, but I think they’re treating the symptom, not the cause.
I practice what I call Agile Vibe Coding: applying XP techniques (pair programming, test-driven, short feedback loops, continuous refactor) on top of normal prompting. I don’t need a framework. I don’t need a three-page template. I need the same things that have always been needed to work on software in a team: know what I want, know what I don’t want, know how to validate it when it lands.
The real problem is one thing: nobody knows how to communicate
I’ve got an old post from 2013 called Programmers are terrible communicators (UDP vs TCP). Go read it if you haven’t, because the problem I described there in 2013 is exactly the thing blowing up now that everyone’s flying an LLM. Nothing changed. The tech got more powerful, but the people are the same people.
Here’s how it works. You’ve got a pile of information in your head. Project context, history, stack constraints, personal preference, things that went sideways in the past, decisions that got made in a meeting two months back. And then you walk into a conversation, whether it’s with a human coworker or an LLM, and fire off your request assuming everything in your head is also in the head of whoever is on the other side. “It’s obvious, everybody knows that.” So you write “do what I’m telling you,” except what you’re telling them is really “do what I’m thinking.” And you don’t even notice they’re not the same thing.
Developers are terrible communicators. Managers are terrible communicators too, and that’s exactly why most of the useful hours in a corporate week get burned in pointless meetings. Nobody gets to the point on time, nobody aligns expectations, the result comes in below the bar, and the default managerial answer to that is “more of the same.” More meetings, more spreadsheets, more reports. Except if your communication was bad at volume 1, it’s going to stay bad at volume 5. The problem is quality. Volume doesn’t fix bad quality.
How I actually talk to Claude or Codex
I treat any LLM exactly how I’d treat a human during a pair programming session. No ceremony, no form to fill out, no 10-page spec. But with communication discipline. Let me walk you through a real example, from last week.
I’ve got about 12 TB of ROMs piled up on my NAS, under /mnt/terachad/Emulators, split across two trees (ROMS/ and ROMS2/) that accumulated across different collections over the last 10-plus years. More than 400,000 files total. Uncompressed romsets, .7z, .rar, giant CDI/GDI bundles, inconsistent file naming, duplicates everywhere. I wanted to consolidate all of it, by platform, into a new ROMS_FINAL/ tree, using standardized naming (No-Intro / Redump / TOSEC) so that when I run Screenscraper later the match is automatic. That’s the goal, stated up front.
But I don’t stop there. I tell it what I DON’T want, too. “Never dedup by filename, only by sha1 + size, filenames lie way too much in this world.” “A Neo Geo romset depends on which emulator is going to consume it, so the MAME zip, the FBNeo bundle, and the Darksoft MVS cart are three mutually incompatible things, keep one canonical copy of each.” “Same idea for NAOMI: the MAME romset is not the same file as the GDI.” “Saturn has USA, Japan, and Europe versions, I want to keep a copy of each region, region is not duplicate.” If I leave that out, the model has no way to know, because that knowledge is in my head and not in the code. If I don’t give it, it’ll assume its own most-reasonable default, which might be the opposite of what I need.
Then I get into method detail. “Create a docs/ directory to serve as living knowledge base, and docs/scripts/ with the steps broken into numbered files (01_walk_and_hash.py, 02_classify.py, etc.). Each step has to be idempotent so I can re-run it if it crashes or if I need to resume halfway through. Progress state lives in a SQLite catalog, not in-memory variables.” This isn’t micromanaging the model, this is aligning the way I work. I know an operation this size is going to hit problems, and I want to be able to come back without losing the previous hours of hashing and classification.
Then, even after it hands me its plan, I keep thinking about what could go wrong. “Zero deletions under ROMS/ and ROMS2/. Whatever doesn’t get forwarded to ROMS_FINAL/ just stays where it was. The only thing the whole pipeline is allowed to delete is temporary files from an extraction that bailed halfway through. Also, the phase that actually executes the moves can only run after I manually approve the planning phase, create a flag file docs/.phase4-approved, and make phase 5 refuse to start without it.” This is the equivalent of making a commit before a big refactor, plus a human gate between planning and applying. I’m protecting against my own mistakes, its mistakes, or both at once.
When the model gets going, I don’t leave the room. I keep asking for status. I notice the hash ETA is way longer than the problem warrants, so I interrupt: “I think we can parallelize, I’ve got spare CPU and 10GbE talking to the NAS, and the Synology over NFS can handle it. Bump up the concurrency, test, check that it’s still stable and that the SQLite transaction ordering doesn’t break.” That’s real pair programming, not blind automation.
The structure behind it
Notice the pattern. I don’t say “solve this problem.” I say “solve this problem, this way and that way, and not this way or that way, and when you’re done, validate X and Y.” In other words, I’m communicating four things, not one:
First, what I want. The end goal in plain language. Second, how I want it done, in broad strokes, leaving room for it to suggest a better solution if it has one, because it usually does. Third, what I don’t want. This is the part most people skip, and it’s the most critical, because it’s where all the unspoken assumptions live, the ones that turn into bugs later. Fourth, how we validate it landed. What’s the expected result, what’s the test, what’s the “done” signal.
And that fourth part is a killer. Most of the clients I’ve worked with over the past 20 years couldn’t tell me what the expected result was. Because it’s easy to want something, and hard to say how you’d measure whether it showed up. Without a success metric, expectations break by definition, because there was no concrete expectation to begin with. That’s one of the main reasons consulting projects go sideways, and it’s identical in the world of AI agents.
When I hand the model all four blocks, it almost never fails. And when it actually can’t do the thing, because the task is impossible given my constraints or because there’s information I forgot to pass along, it doesn’t try to guess. It tells me: “given your constraints, I can’t proceed because of X or Y.” Then I adjust, or I loosen a constraint, or I realize I didn’t actually know what I wanted. It all works.
Once the context is solid, ask instead of prescribe
There’s a shift I make after the first few well-loaded prompts. In the opening turns I pour in a ton: goal, constraints, method, validation, all the context the model needs to understand the terrain. It’s a lot of detail, it’s my job to front-load it, and I already explained why there’s no way around that.
But once that ground is solid, I stop prescribing solutions and start asking for suggestions. Instead of saying “implement it this way, with that library, following this pattern,” I switch to “given everything we’ve already covered, what’s the best approach here? Research online if you need to, compare the options, and come back with the solution you’d pick for this goal.”
That’s the step most people skip, and it’s exactly where the LLM earns useful autonomy. It’s got way more vocabulary than I do across a pile of topics. It read the whole internet; I read whatever I had time for. If I prescribe line by line, I’m throwing that edge away. If I set the context and then ask, it comes back with options I hadn’t considered, with trade-offs laid out, sometimes better than my original idea, and I get to pick.
The trick is simple: asking well requires having set the context well first. A dry question with no ground gets back a generic answer, or the first idea that seemed to fit. A question resting on ground you already laid comes back with a real proposal, alternatives compared, references cited. The model is ready for that kind of contribution, it just won’t give it to you until you’ve spent the time setting the stage.
And look: this method wasn’t invented for LLMs. It’s the same way I’d work with any human developer, senior or not. Give them the context, give them the goal, explain what I care about, then ask “what’s the best way to do this?” instead of dictating the solution. The only difference is the LLM gives it back in seconds when a human would take days. The way you run the conversation is the same.
It’s not a 10-page spec
And here’s the important bit: what I’m describing is not a formalism. It’s not a long spec, it’s not a Confluence doc, it’s not a template. It’s just how I talk to anyone who has to deliver something to me. I picked it up running projects, managing contractors, integrating teams that weren’t mine, and getting knocked around every time my communication was bad. After a while it becomes second nature.
If I don’t really care about the final result, say a quick experiment, a weekend toy, something disposable, I cut way back. I know my expectations might break, and that’s fine, the cost of a bug here is cheap. But if the result actually matters, I invest the time needed to give the other side (human or AI) the best shot at delivering what I want. Output is proportional to the time you spend on input. If you’re not willing to explain what you want properly, don’t complain when what comes back is wrong.
To illustrate: this very post you’re reading was written by Claude, off a prompt I gave it. Below is the screenshot of what I typed. Notice: no hidden assumptions, clear goal, references to earlier posts baked in, constraints stated explicitly, enough detail that it didn’t have to guess.
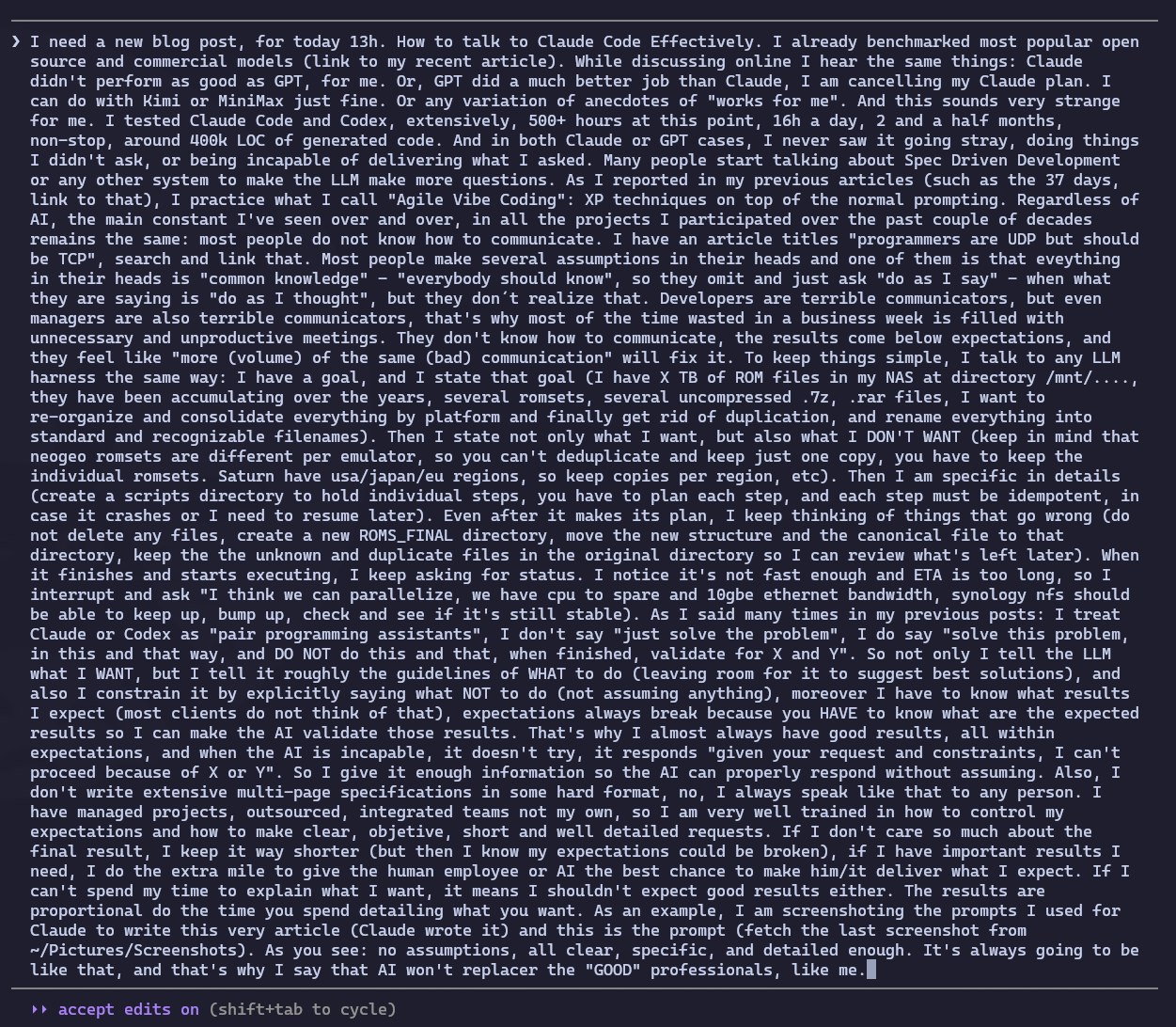
But look, that’s just the first prompt. It wasn’t the only one. While Claude was writing, I kept tracking, sending corrections, adding points I forgot to put in the first prompt, flagging factual errors I caught in the generated text, and fine-tuning tone. “Hey, I also forgot to tell you we need to cover X.” “No, that reference is out of date, OpenAI’s Sora got shut down, fix that.” “Go read what we already documented over at /mnt/terachad/Emulators/docs/ and see if you can sharpen up the ROMs example.” This very observation you’re reading right now started as a mid-flight prompt:
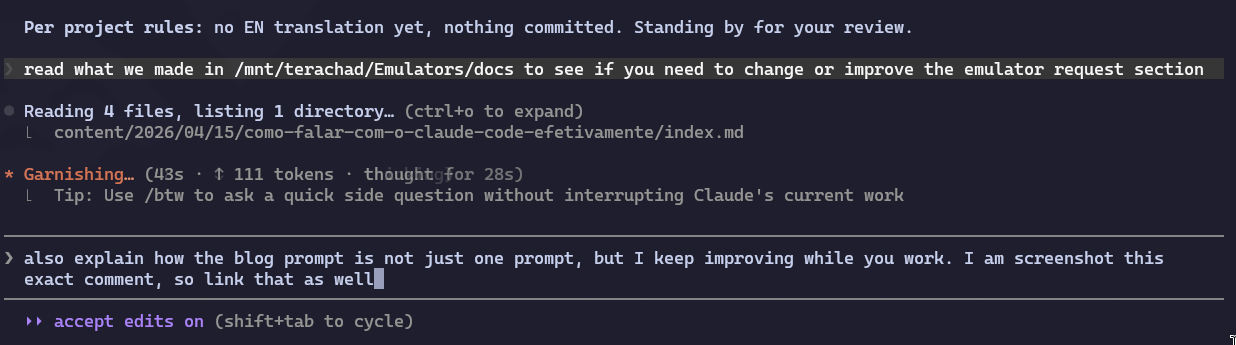
And the conversation kept going all the way to the commit. I had already told it to humanize, translate to English, and push, and I still interrupted at the last second because I spotted an unnecessary English loanword I wanted to fix before it went up. Here’s that moment:
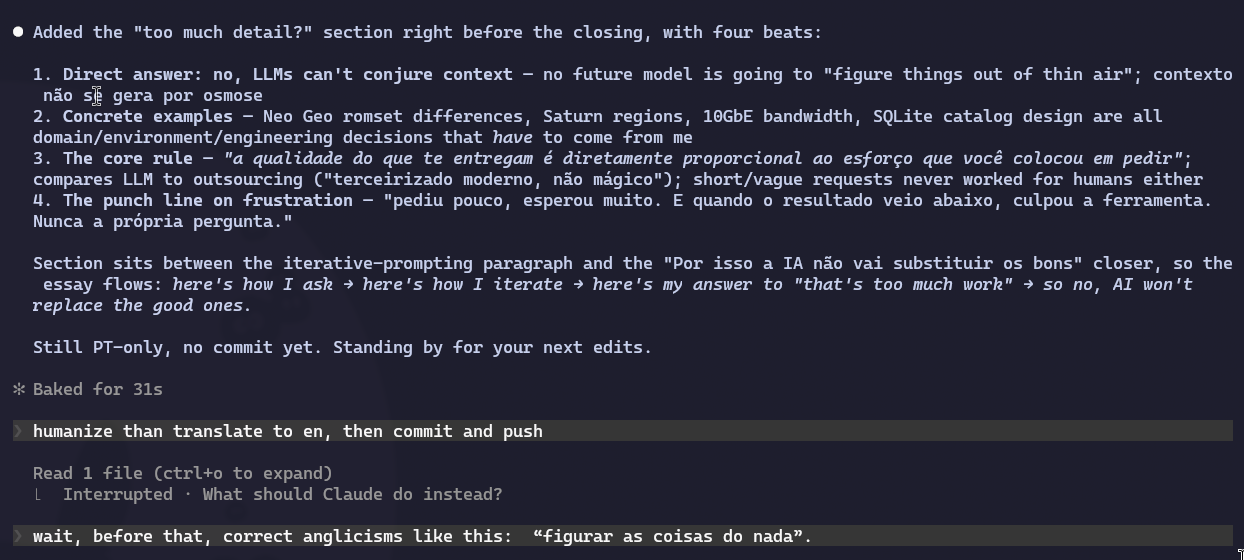
That’s real pair programming. Nobody sits down with a colleague, drops a 15-line task, stands up, and walks away expecting magic. You stay there, you watch the execution, you see the code come together, you suggest adjustments, you catch errors while they’re still cheap to fix, you add context you just remembered. The initial prompt is the starting point, not the final contract. Agile Vibe Coding in action: short cycles, fast feedback, continuous correction.
This isn’t a formal spec. It’s a conversation that keeps going during the work, not before it. And that’s how it’s always going to be, with me and with any good professional.
“Akita, you write too much detail, shouldn’t the AI figure this out on its own?”
That’s the question I know is coming, so let me answer it upfront. No, the AI is not going to figure it out on its own. There is no future version of Claude, GPT, Gemini, whatever, that’s going to guess what’s in your head. Context doesn’t generate itself by osmosis. If the information isn’t in the code, in the docs, or in my prompt, it simply doesn’t exist for the model. Full stop.
Neo Geo romsets being different per emulator? That’s domain knowledge. Saturn having separate regions? Domain knowledge. My NAS having 10GbE to handle aggressive parallelism? Environment context. Having docs/ with a SQLite catalog to survive crashes? An engineering decision I made. The model has no way to “discover” any of this. All of it is my job to bring to the conversation. And if I’m not willing to spend my own time understanding these details, why would anyone, or anything, do it for me for free?
The rule is simple: the quality of what you get back is directly proportional to the effort you put into asking. It has always been this way. Anybody who’s hired a contractor knows it: vague requests, ill-defined scope, “the client knows what they want, they just can’t explain it,” that’s a guaranteed recipe for a project to go off the rails. Always was. The LLM is the same thing, just faster and more patient. Think of it as modern outsourcing, not magic. A magician solves the problem without you saying anything. A contractor solves exactly what you asked for, exactly the way you asked, with the information you provided. If you didn’t ask properly, you don’t get it properly.
The frustration of people showing up here burned out on Claude or Codex is almost always the same: they asked for little, expected a lot. And when the result came back short, they blamed the tool. Never the question.
That’s why AI won’t replace the good ones
That’s exactly why I say, with full conviction, that AI agents aren’t going to replace good professionals. They’re going to replace people who can’t frame their own question properly, who don’t know what they want, who don’t know how to validate a result, who need somebody to think for them. And look, those people were always replaceable, it’s just that now the replacement is cheaper. The market is doing the math.
The good professional, meanwhile, got more productive. Uses the LLM as a pair programming partner at 2 a.m., no complaints, no union, no ego clash. Ships in a week what used to take a month. And is still the same good professional they were, because the skill that mattered, knowing what to ask for, what not to accept, and how to measure, is still 100% theirs. The tool just executes.
Stark + Jarvis = Iron Man
Let me drop a metaphor that I think wraps the whole thing up. Think about Tony Stark, in the MCU. He’s got Jarvis, probably the most advanced fictional AI pop culture has produced in the last two decades. Voice control, context awareness, planning, parallel execution, even a sharp personality. Technologically, Jarvis would easily be the best AI agent you could imagine today.
And even so, Jarvis on his own doesn’t build an Iron Man suit. Doesn’t build the Arc reactor. Doesn’t build any of the gear that makes Stark be Stark. All that advanced tech, with no Stark to guide it, just sits there. It’s Stark’s genius, his vision, his stubbornness, his engineer’s intuition about where to push next, that makes any of it real. Jarvis executes. Stark thinks.

There’s another detail in that story almost nobody remembers: not even Stark, with all his genius and with Jarvis riding shotgun, nails the perfect suit on the first try. He spends movie after movie iterating. The Mark I was literally bolted together in a cave out of scrap. The Mark II could fly, but iced over at altitude. The Mark III fixed the ice but weighed too much. And on it goes, each iteration fixing a specific flaw in the last, all the way to the Mark LXXXV in Endgame, his 85th suit. Eighty-five. The whole MCU Iron Man arc is basically a ten-year campaign of iterative development on one extremely complicated product.
That’s exactly the mental model I think we should be using when we work with AI today. You don’t fire off a prompt and wait for the definitive solution to pop out. You, sitting in the Stark chair, use the AI (your own Jarvis) as an accelerator on each lap of the cycle: propose, test, see what broke, fix it, propose again. The AI speeds up every lap, it doesn’t erase the laps. If someone swapped iteration for “one magic final answer,” they never understood that engineering was never like that, human or no human.
Put Stark and Jarvis together and now you’ve got Iron Man. Take either one away and the half that actually matters is missing.
Claude Code vs. Codex: my pick today (April 2026)
A quick aside so this doesn’t go unsaid: these days I’m alternating between Claude Code and Codex, but I’ve been leaning into Claude Code. Let me spell out why, because it’s not about the LLM itself.
Claude Opus and GPT-5.4 xHigh, to me, are basically tied as models. On the hard tasks, when one of them can’t pull it off, I swap over to the other and the other usually does. Head to head, both are strong. What separates them today is the harness, not the model.
And the Claude Code harness, right now, is flat-out better. Two concrete reasons: planning and parallel execution.
Planning. Claude Code breaks a long task into subtasks, keeps a visible to-do list I can actually watch on screen, tries to run things in parallel when it can, and doesn’t drop items. When it tells me “done,” I know the full list got executed, because it’s right there for me to check. That detail changes the whole game: I trust the “done” without having to chase every single item with “hey, did you actually do that other one?”.
Parallel execution. This one is clean-cut. If Claude Code is mid-task and I hit ESC to throw in something else, it typically keeps the first task running and kicks off the second in parallel, unless the new request actually requires cancelling the first. Codex, same situation, stops the first to deal with the second, and doesn’t always know how to resume the first from where it left off without me prodding it manually. With Claude Code I get to actually flow, opening new fronts while the old ones keep running. With Codex I have to go serial, be patient, and be more deliberate about every request, because interrupting is expensive.
None of which means Codex is bad. It’s good. Plenty of times when Claude Code gets jammed on a hairy task I pop over to Codex and it unjams it immediately. But then my way of working shifts: smaller requests, more focused, one at a time, wait for it, move on. Works fine, it’s just not the flow I prefer.
Codex is probably going to catch up on the harness side over the next few months, and the conversation will shift. But today, April 15th, 2026, if I have to pick one as my daily driver, it’s Claude Code, and the reason is the harness, not because OpenAI’s LLM is somehow inferior. Writing this down so that six months from now I can reread it and laugh.
Which is why my company is called Codeminer 42
To close with a reference I’ve been carrying around for years: my company is called Codeminer 42. The 42 isn’t a random number. It’s a direct nod to Douglas Adams, from The Hitchhiker’s Guide to the Galaxy.
If you don’t know the bit, here’s how it goes. An entire civilization builds a planet-sized supercomputer to calculate the Answer to Life, the Universe, and Everything. After millions of years of processing, the machine finally spits out the final answer: 42. And then there’s that awkward silence, because nobody there could remember what the original question had been. 42 is a technically correct answer to a question no one bothered to formulate properly. Which is to say, it means absolutely nothing. Plenty of people seem to think 42 has some deep meaning baked into it. It doesn’t. It’s the wrong answer to the wrong question.
That’s the sharpest lesson about engineering I’ve ever read in fiction. Every expectation that breaks, breaks because the question was wrong, not because the answer was badly executed. That’s what Codeminer 42 exists for, and it’s exactly what I practice day to day, whether the other side is a human client or an LLM. Before I deliver what you asked for, my job is to make you discover that what you think you want is probably wrong, to force you to rethink the assumptions you walked in with, and only once the question is sharpened do I get to hand you the best possible result. Skip that step and anything I deliver is going to be a 42.
So next time you read somebody saying “I canceled Claude because it doesn’t deliver,” or “GPT is way better,” or the other way around, take a closer look at the question the person was asking. Nine times out of ten, the problem isn’t the model. It’s the question. And nine times out of ten, the answer that person got back was 42.