20 Years of Blogging: Translating Everything to English

Four days ago, April 5th 2026, my blog turned 20. Yeah, I’m late on the anniversary post. There’s a reason, and that reason is what this piece is about.
I started in 2006 on Google’s Blogspot, like most people did back then. Later I migrated to a Rails 2.0 CMS that already existed, went through Typo3, and in 2012 I built my own engine from scratch on ActiveAdmin, which I dragged along from Rails 3 all the way to Rails 7. Only recently, in September 2025, I finally abandoned that custom engine and moved to Hugo with the Hextra theme, which is what this post is running on. Twenty years carrying the same posts across Textile, migrating from Less to Sass, trading Liquid for Markdown, and trimming obsolete junk along the way.
Two decades, five eras
Something few programmers stop to think about is how much the tech world changes in 20 years. I talked about this at length on Akitando #37 — The Dimension of Time. When I opened this blog in April 2006, I already had 10 years of experience behind me. I’d watched the dot-com bubble rise and blow up in 2000. And from that point on I saw a few more big ones: the rise of social networks (Orkut, Facebook, Twitter), the smartphone and mobile app revolution in 2008, the 2008 financial crisis, Bitcoin being born in 2009, the cloud and SaaS era, and now the generative AI era.
I watched those waves crash for real. Each one completely changed how we work and who survives professionally. This is the kind of thing you only see from a distance, after you’ve stacked up a few turns of the wheel.
My own career went through some violent pivots. I told the whole story on My First 5 Years (1990-1995), but the short version: I started in multimedia agencies, moved into enterprise consulting working on SAP, dropped all of it in 2006 to jump into Ruby on Rails and open source, spent a decade running events — mainly Rubyconf Brasil from 2007 to 2018 — then shut the conference down and started the Akitando YouTube channel, which grew past 500k subscribers. In the middle of all that there was the pandemic that rearranged everyone’s life. And since the beginning of 2025 I’ve turned into a full-time AI researcher and user, running models locally and breaking things with Claude Code until they work.
Checking the /tags/ai tag, I wrote 51 AI-related posts between 2025 and 2026 alone — 19 in 2025 and 32 more in 2026, which has barely started. Between 2018 and 2024, the blog was mostly the transcript archive for my Akitando videos. I’d record the video, transcribe it, dump it on the blog, and people would read it there. But once I started writing actively again, I noticed there was a loyal audience that never went anywhere, even through the quiet years. That feedback is what made me start The M.Akita Chronicles, a more personal series about the behind-the-scenes of recent projects.
The problem I never solved
For those 20 years, one thing kept nagging at me. Since everything was in Portuguese, it was inaccessible to anyone who didn’t read the language. I’d been getting messages for years from Brazilian readers living abroad (Portugal, US, Japan, Germany, Canada) asking for some English version they could share with their gringo coworkers. Stuff like “look, I’d show this piece to my team, but it’s only in Portuguese.”
I always said “one day I’ll translate it.” And I never did. Why? Because we’re talking hundreds of posts. I spent the last couple of days looking at the numbers: 727 Portuguese index.md files in the repo. Translating by hand, one by one, would take weeks if not months of dedicated work. I was never going to find the stamina for that. And every year that passed, more posts piled onto the queue.
The ironic part is that some blog posts were originally born in English. During 2017 and 2018 I had decided to write English-first, trying to reach an international audience. A whole interview series — the “chatting-with” ones with folks like Hal Fulton, Scott Hanselman, Chris Wanstrath (GitHub), Blaine Cook (former Twitter), Adam Jacob (Chef) — were born in English and stayed there. The missing piece was the reverse: take the Portuguese posts and translate them the other way.
The weekend that paid off 20 years of technical debt
This past Monday I opened Claude Code inside the blog directory. And asked it to translate everything to English. That was literally it.
It kicked off Monday, April 6th, around 6:30pm. I let it run. Went to sleep. Woke up Tuesday, it kept running. Slept again. Wednesday morning it was done. Counting from the first translation commit to the last, it was something like 39 hours of elapsed time. Not continuous, of course — there were nights, lunches, a coffee break or two. In practice, one long working weekend.
The result is sitting in the git repo, in commits anyone can inspect on the public blog repository. Scan the log and you can see the cadence: batch of 2008 QCon posts. Batch of 2009 RailsConf. Batch of 2011 Objective-C. All of 2012. The 2015 Elixir series. All of 2016, 2017, 2018. Batch after batch, organized by year and by series. More than 80 commits tagged i18n: or EN translation: between the night of the 6th and the morning of the 8th. By the time I’m writing this post, 354 index.en.md files are live against the 727 original index.md. Almost half the blog translated in one shot.
And look, ninety percent of it was smooth sailing. The translation came out good, natural, faithful to my voice in the original — I honestly didn’t expect it to work this well. Claude Code respects the tone of the source if you give it solid voice and style guidance, and it respects technical ideas without “correcting” anything you wrote. Worst case, you review a few paragraphs. Best case, you read the English version and it sounds like you wrote it directly in the other language.
A quick aside on the Claude side of the bill. I’m a Max 20x subscriber on Anthropic, which is the heavy-use tier built for people who hammer Claude Code all day. I’d never hit the ceiling of that plan before, not even in my most intense vibe coding sessions. This translation weekend was the first time I genuinely blew past the Max 20x limit and kept going into the “extra usage” mode (Anthropic charges on top when you go over the monthly plan ceiling).
For a sense of the damage, here’s my account dashboard this morning:
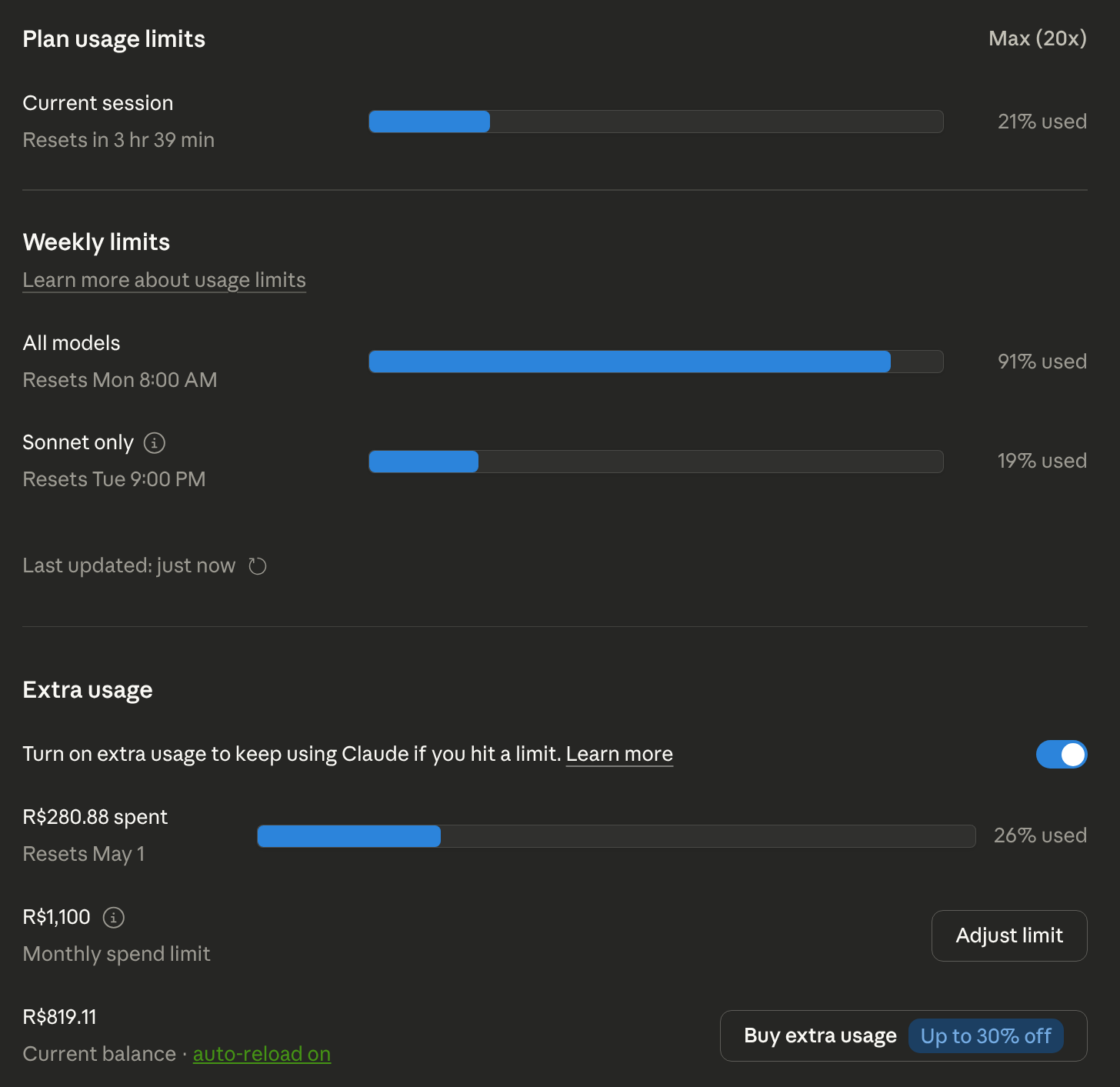
91% of the weekly “all models” quota burned through, already into the extra-usage mode, R$280.88 (about $50 USD) spent on top of the flat monthly subscription, and there’s still a good chunk of the cycle left. It tracks: read the full post, generate the translation, run the humanizer on it, repeat hundreds of times in a row. The token volume is massive. And today, while I’m writing this piece, Claude Code keeps hitting me with API Error: Request rejected (429) · Rate limited more and more often, which also tracks: probably some combo of my own plan quota topping out and Anthropic applying general backpressure, because I can’t be the only one going nuclear with the tool these days. Fine, whatever. That’s the price of using the tool hard when it actually mattered.
The other ten percent was a different story.
When commercial LLMs say “no”
Half a dozen older posts flat out refused to translate. Both Claude and GPT, through their APIs, would bounce with a 400 error and a content policy message. I tried multiple times, fresh sessions, clean context. Nothing.
The hypothesis is simple: those posts touched topics that automated content moderation flagged. A 2009 post about Steve Jobs’s 2005 Stanford commencement speech (which mentions cancer — Jobs was talking about the terminal diagnosis he’d received). A couple of old Ayn Rand chapters I translated years ago about rights of man and argument by intimidation. An anti-Nazi post that ironically got blocked, probably just because the word “nazi” showed up, even though the context was critical. A post about the money speech from Atlas Shrugged. And a democracy-and-ethics essay that systematically broke every attempt.
The ironic part here is that the only way to get those posts translated was using an open source model. I loaded up Qwen 3.5 35B in llama-swap, running locally, no corporate policy filters. The model read them, understood the context, and translated everything without drama. It’s the same model I tested extensively in my last LLM benchmark, and which I rate as one of the best open source models available right now.
So yeah — a Chinese model translated posts that Western models refused. I can’t help finding this slightly hilarious. Oh, and of course, I’m not allowed to speak ill of China (sarcasm). Commercial LLMs will always have the corporate-policy-and-preemptive-censorship problem applied with a fairly thick ruler. It’s a real trade-off for anyone using them in production: you get fluency and reasoning power, you lose control the moment the topic brushes up against whatever the company decided is sensitive.
The reverse case: 2017-2018 translated back into Portuguese
While I was dialing in Claude Code to generate the English content, I figured I might as well solve the symmetric problem. The posts I had originally written in English during 2017 and 2018, plus the whole “chatting-with” interview series from 2008, were sitting there without a Portuguese version. Claude Code ran the reverse: read the English, wrote the Portuguese. So if you never read the English originals (since most of my audience is Brazilian anyway), now you have access too. Take a look at the Off-Topic section to see what showed up that’s new.
On top of that, Claude Code also updated my generate_index.rb script so it understands the blog’s bilingual structure and generates two separate indexes, one in Portuguese and one in English. The PT/EN toggle in each post’s footer shows up automatically whenever an index.en.md sibling exists. All nicely plugged into Hugo, using its native multilingual pattern.
The bigger point
Here’s the takeaway I wanted to leave in this anniversary post. Translation at scale, hundreds of articles, your content, in your voice, respecting the tone of the original, used to be an expensive and miserable problem. Now it’s a weekend problem. This is already live — you’re reading the result. The barrier that existed to reaching audiences outside Brazil became cheap enough that I don’t have an excuse anymore.
Alright, so let’s wrap the anniversary recap. 20 years. 727 Portuguese posts, built across five different eras of technology. 354 new English posts generated over a weekend. Half the blog is now bilingual. And the rest will follow. What’s missing is mostly old ActiveAdmin posts, Rails 2 stuff, and obsolete tips that honestly deserve to be deleted or left untranslated on purpose.
If you’ve got a gringo friend who’s tired of seeing you post Portuguese links and needs an excuse to send them something of mine — send it. The main AI posts, the Chronicles, benchmarks, rants, and a good chunk of the historical archive are already available in English at the same domain, just flip the toggle in the footer. Thank you to everyone who’s followed this blog for these twenty years. There are readers here who’ve known me since the Blogspot days. You know who you are.
Here’s to another year.