Is RAG Dead? Long Context, Grep, and the End of the Mandatory Vector DB
This is one of those itches I can’t scratch. Back in the early LLM days, around 2022/2023, we had 4k of context on GPT 3.5, 8k if you were lucky, 32k was a luxury. To do anything with a real document you had no choice: chop the text into pieces, generate embeddings, throw them in a vector database, do similarity search, grab the top-5 chunks, and pray the right ones came back.
Then it became an industry. Pinecone, Weaviate, Qdrant, Chroma, Milvus, pgvector, LangChain, LlamaIndex, Haystack. Tutorials everywhere, “build your chatbot with your PDFs,” entire consultancies feeding off this. It became the “hello world” of applied LLMs: document → chunk → embed → vector DB → query.
Today, in April 2026, Claude Opus 4.6 has 1 million tokens of context. Sonnet 4.6 too. Gemini 3.1 Pro too. GPT 5.4 has a smaller window but still in the comfortable range, in the hundreds of thousands. And some models already have experimental 2M token modes. The question that keeps nagging at me: what on earth do I need a vector stack for, to solve a problem that fits inside the model’s window?
And there’s more: vector databases have real problems nobody wants to talk about. False neighbors. Arbitrary chunking that splits a definition from its usage. Embeddings that age badly. Not to mention that when the result is wrong, you have absolutely no idea why.
The thesis I’ve been chewing on is simple: in most cases, a well-aimed grep plus a generous context window beats a full RAG stack. It’s cheaper, it’s easier to maintain, and when it breaks you can actually debug it. Let’s break this down.
What the Claude Code leak showed
Before we get into the theory, let me bring up something that happened a few days ago that backs this whole argument up. On March 31, 2026, Anthropic, by accident, published version 2.1.88 of the @anthropic-ai/claude-code package on npm with a nearly 60 MB source map attached, and roughly 512,000 lines of TypeScript from their internal tool leaked into the wild. I already wrote about the incident last week, with more detail on what showed up in the code.
The part that matters for this discussion is Claude Code’s memory system. Instead of dumping everything into a vector DB, the architecture has three layers. There’s a MEMORY.md that stays permanently loaded in context, but it doesn’t hold any actual data: it’s just an index of pointers, around 150 characters per line, kept under 200 lines and about 25 KB. The real facts live in “topic files” that get pulled on demand when the agent needs them. And the raw transcripts from previous sessions are never reloaded whole, only searched with grep, hunting for specific identifiers. No embedding. No Pinecone. Just write discipline (topic file first, index after) and lexical search. That’s it.
Claude Code’s main loop also has a tiered system for handling a context that’s filling up. As I detailed in the previous post, there are five different context compaction strategies, with names like microcompact (clears old tool results based on age), context collapse (summarizes long stretches of conversation), and autocompact (which fires when the context gets close to the limit). The CLAUDE.md file, which a lot of people thought was just a convention, is first-class in the architecture: the system re-reads it at every iteration of the query.
What this tells me: the best coding agent on the market right now, built by the company selling the most expensive model out there, does not use a vector DB. It uses files on disk, a markdown index, lexical search, and smart compaction strategies for when the context overflows. They could’ve slapped embeddings on top, they have the money to run whatever they wanted, and they chose not to. The reason, in my reading, is exactly what this post is arguing: to retrieve text from files you control, with generous context available, a vector DB is dead weight. Better to invest in compacting the window you already have than indexing everything into an external store.
There’s a curious security detail that came along with the leak: people noticed the compaction pipeline has a vulnerability they’re calling “context poisoning.” Content that looks like an instruction, coming from a file the model reads (say, a CLAUDE.md from a cloned repo), can end up being preserved by the compaction model as if it were “user feedback,” and the next model takes that as a real user instruction. It’s a new attack vector. But that’s a topic for another post.
The “Dream” system and memory consolidation
But what really caught my eye for the RAG debate, which I unpacked in detail last week, is the system called autoDream. It’s a forked subagent, with read-only bash access to the project, that runs in the background while you’re not using the tool. Its job is literally to dream: to consolidate memory. The name isn’t accidental, and the obvious analogy (which I couldn’t resist) is the human brain consolidating memory during sleep, turning short-term experience into something more stable.
For a dream to actually run, three gates have to open at once: 24 hours since the last dream, at least 5 sessions since the last dream, and a consolidation lock that prevents concurrent dreams. When it fires, it goes through four phases. Orient (does an ls on the memory directory, reads the index). Gather (looks for new signals in logs, stale memories, transcripts). Consolidate (writes or updates the topic files, converts relative dates into absolute ones, deletes facts that have been contradicted). And Prune, the final cleanup that keeps the index under 200 lines.
The decision to make autoDream a forked subagent is the detail that matters here. It does not run in the same loop as the main agent. Why? Because memory consolidation is a noisy process. The model has to re-read old transcripts, compare them against what’s in MEMORY.md, decide what stays and what goes, form hypotheses about things it saw in earlier sessions. If that ran in the main context, it would pollute the “train of thought” of the agent that’s trying to help you with your current task. By forking, you keep the two separate. The main agent stays focused on what you asked for, and autoDream does the housekeeping in parallel, with no write permission on the project.
And the way it figures out what needs to be consolidated is plain old lexical search. The transcripts live as JSONL files on disk, and autoDream uses grep to look for new signals. Just grep, on text logs. Stop and think about that for a second. The memory consolidation of the most advanced agent in the world, built by one of the richest AI companies out there, is a forked subagent running grep on text logs. If a vector DB were the right answer for this kind of problem, Anthropic would’ve put a vector DB in there. They didn’t.
And there’s a detail that, to me, is the buried gold of the entire leak, and it fits this argument like a glove. In autoDream, memory is treated as a hint. The system assumes that what’s stored may be stale, wrong, contradicted by something that happened later, and the model has to verify before it trusts it. The vector DB pitch is the opposite of that: index everything, search by similarity, return the top-k, trust the result. Claude Code went the conservative route. Index little, search by word, return a hint, and stay skeptical until you’ve laid eyes on the actual fact.
The whole strategy works in two layers. Inside a single session: generous context plus grep plus smart compaction (microcompact, context collapse, autocompact). Between sessions: a subagent that consolidates memory asynchronously, using grep on the transcripts and treating the result as a tip, not as truth. Embeddings and vector DBs don’t show up in either layer. The deliberate choice was a smart reader chewing on raw text, not a dumb reader being spoonfed the top-k of an embedding.
The practical lesson for our debate is simple. The most advanced agents on the market are heading toward generous context, lexical search, and smart compaction, not toward classic RAG pipelines. If Anthropic, with all the infrastructure and talent they’ve got, picked this path for Claude Code, those of us building internal applications on a fraction of that budget should at least think about going the same way.
Where the story started turning
When the ceiling was 32k of context, retrieval was the bottleneck of the entire problem. You had to pre-filter aggressively, because anything that made it into the window was sacred space. A vector DB was the only halfway-decent way to do that semantic pre-filtering. The logic was: “the reader (LLM) is expensive and dumb, so the retriever has to be smart and selective.”
Today the equation has flipped. The reader is now the smartest one at the table, and the window grew big enough to hold an entire document. So the retriever can (and maybe should) go back to being dumb. The dumber, the better. You want high recall and low precision, and you let the model do the fine work. Grep does exactly that. So does BM25. And ripgrep flies through millions of lines without breaking a sweat.
And this isn’t just my hunch. The BEIR benchmarks have shown for a while now that BM25 matches or beats a lot of dense retrievers when the domain drifts away from where the embeddings were trained. Anthropic itself published a post on Contextual Retrieval that basically says the same thing: a lexical signal plus an LLM’s judgment beats pure embeddings on most knowledge tasks. And take a look at Claude Code, the tool I’ve been using every day for 500 hours: it navigates the repo with Glob and Grep. No vector DB, no embedding, no LangChain. It works ridiculously well.
The real problems with vector databases nobody advertises
The vector DB marketing sells the dream of perfect semantic search. Reality is messier.
False neighbors come first. Cosine similarity rewards topical similarity, not relevance. You ask “how do we handle authentication errors” and the DB returns every chunk that mentions authentication. The chunk that actually answers the question may be in tenth place, or may not have been retrieved at all because the doc author wrote “login” instead of “auth.”
Chunking is the second one, and it’s a disguised disaster. A 512-token window with a 64-token overlap sounds reasonable, until you realize your important table got cut in half, the function definition ended up separated from its usage, and the piece of documentation with the exact command got orphaned without the context of its section. The chunk boundary tends to land exactly where the answer was living.
When it fails, it fails without leaving a trace. When BM25 misses, you know why: the word isn’t there. When a vector DB returns garbage, you get a plausible-looking wrong chunk, with no diagnostic signal at all. Good luck debugging that in production at two in the morning.
The index gets stale. Every document update calls for re-embedding. If you have 10,000 docs and 200 of them change per day, that turns into a batch process, monitoring, a queue, retries, embedding API costs, and an unavoidable inconsistency window between what’s on disk and what’s in the index. Grep has none of that. File changed? The next query already sees it.
And there’s the operating cost nobody adds up. Pinecone charges per vector. Weaviate wants a cluster to maintain. pgvector saves you a new server but you still own a schema, an index, and a re-embedding pipeline. Each of those things wants engineer time, monitoring, tests, deploys. All of that to do a search that rg would often crack in 200ms.
Comparing the complexity
Look at the diagram:
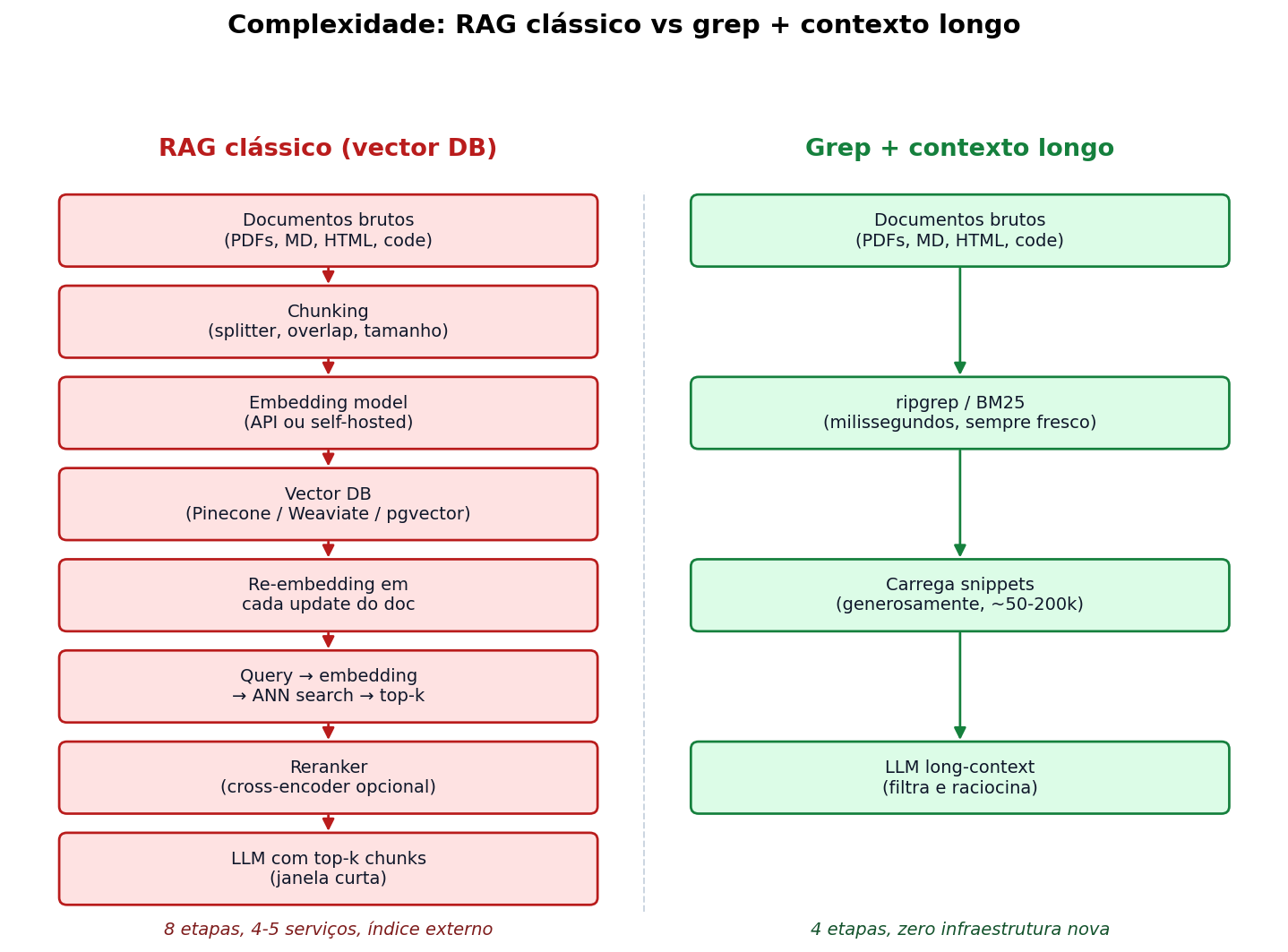
On one side, eight steps, four or five services, an external index that needs to be maintained and kept up to date. On the other, four steps, zero new infrastructure. This isn’t a caricature: it is literally what you have to set up for each case.
The honest question: does the left column pay off? In 2023, yes, because the right column didn’t exist (no LLM had a 200k window). In 2026, in most cases, it doesn’t.
Pros and cons of each side
Classic RAG (vector DB)
For:
- Works for huge document bases, on the order of hundreds of GB, where even
rgwon’t cut it without prior indexing - Handles heavy paraphrase and cross-lingual queries (“how do I cancel” vs. “subscription termination process”) where the user’s vocabulary doesn’t match the document’s
- Works for non-textual modalities (image, audio) where grep has nothing to look at
- Saves input tokens if you’re tight on budget or absolute latency
Against:
- Complex stack: embedding, vector DB, chunking, reranker, re-indexing pipeline
- Opaque failures, hard to debug
- Chunking destroys the context of tables, code, long definitions
- Operational overhead (index, queue, monitoring, re-embedding cost)
- The semantic search the marketing is selling rarely works the way the marketing promises
Grep + long context
For:
- Practically zero new infrastructure: ripgrep, sqlite, or a plain
LIKEin Postgres - Always fresh: file changes, the next query sees them
- Transparent failures: the word is either there or it isn’t
- Loads the document in generous chunks, the model does the fine filtering with actual semantics
- Cheaper in dev and ops, cheaper to pivot domains
Against:
- Doesn’t scale to terabytes of raw text without some kind of indexing
- Suffers when the user’s vocabulary is very different from the document’s
- Doesn’t work for non-textual modalities
- Per-query latency is higher in absolute terms (loading 100k tokens always costs more than loading 5k)
- Per-query input cost is higher if you don’t have prompt caching
But what about cost?
This is the argument I get hit with the most when I defend the “load everything into context” thesis. “It’ll get crazy expensive, 200k tokens of input per query is absurd.” Let’s actually run the numbers.
In yesterday’s LLM benchmark post I mapped out the per-token price of every model. Take Claude Sonnet 4.6: $3 per million input tokens, $15 per million output. Take GLM 5 (which I proved actually works): $0.60 input, $2.20 output. Take GPT 5.4 Pro at the top of the heap: $15 input, $180 output (yeah, that one stings, I know).
Before we turn “200k tokens” into dollars, let’s land that number on something tangible, because “100k tokens” doesn’t mean anything to anyone. A token, on average, is roughly 0.75 of a word in English (Portuguese is similar, maybe a touch heavier because of longer words). So, translating:
- 100k tokens ≈ 75,000 words ≈ a whole short novel like Hemingway’s The Old Man and the Sea with room to spare, or about three long Wikipedia articles glued together.
- 200k tokens ≈ 150,000 words ≈ a big novel, like Crime and Punishment in full, or half of the first Game of Thrones book (which clocks in around 298k words, so roughly 400k tokens).
- 400k tokens ≈ 300,000 words ≈ A Game of Thrones in full, the entire first book of the series in your window.
- 1M tokens ≈ 750,000 words ≈ the entire Lord of the Rings trilogy plus The Hobbit, or the whole Bible (King James is around 783k words, roughly 1M tokens), or about two and a half Game of Thrones books stacked on top of each other.
So when I say “throw 200k tokens of input at the model,” what that actually means in the real world is “throw the entire Crime and Punishment in as the context for your question.” That’s a lot. And that’s exactly what makes the argument of this post viable: today’s models can read an entire novel in one go and still answer a specific question about it. In 2023, this was science fiction. In 2026, it’s the base case.
So picture a query that throws 200k tokens of input at the model (there goes Crime and Punishment again) and produces 2k tokens of output (about three pages of response):
| Model | Input ($) | Output ($) | Total per query |
|---|---|---|---|
| Claude Sonnet 4.6 | $0.60 | $0.03 | $0.63 |
| Claude Opus 4.6 | $3.00 | $0.15 | $3.15 |
| GLM 5 | $0.12 | $0.0044 | $0.12 |
| Gemini 3.1 Pro | $0.40 | $0.024 | $0.42 |
| GPT 5.4 Pro | $3.00 | $0.36 | $3.36 |
Now throw prompt caching into the mix. Claude has a cache that drops cached input to a fraction of the full price (in the ballpark of 10%, depending on the model). Gemini has a similar mechanism. When you fire a sequence of queries against the same 200k-token dump, the cost of subsequent queries plummets to pennies. With Sonnet cached, you can fairly call it about $0.10 per follow-up query without making things up.
Now compare that to the cost of running a Pinecone, or a Weaviate, or a pgvector. Setting aside the price of the subscription itself (which varies a lot), you need an engineer to wire up the pipeline, maintain it, monitor it, deal with embedding failures, redo the chunking when the domain shifts. Conservatively, you’re looking at somewhere between 40 and 80 hours of engineering to make the thing stable. At R$ 200/hour, that’s between R$ 8,000 and R$ 16,000. In USD, somewhere between $1,600 and $3,200 just to stand it up.
With $3,200, on Sonnet 4.6 with prompt caching, you can run something on the order of 30,000 queries of 200k tokens each. Thirty thousand queries, depending on the scale of the project, gives you several months or even an entire year of an average internal tool. And you didn’t pay an engineer to wire up a pipeline. There’s no vector DB server to maintain. And if the document changes, the system already sees it on the next query.
The “RAG is cheaper in tokens” argument ignores that tokens are the cheapest thing in the entire equation. Engineers cost a lot, servers cost a lot, bugs in production cost a whole lot more. Tokens have become a commodity, and they’re getting cheaper with every new model release.
The classic RAG argument was “the model is expensive, retrieval is cheap.” Today it’s the opposite: the model is the cheap part of the stack, smart retrieval is what costs a fortune to build and maintain.
Where the thesis doesn’t hold
I don’t want to come off as a fanboy. There are cases where classic RAG still wins:
- Massive corpora. If you have 500 GB of raw text, even
rgwon’t solve it in acceptable time. You need some kind of indexing. It can be indexed BM25 (Tantivy, Elasticsearch), it can be a vector DB. But notice: the first option is still lexical, not vector. - Wildly scattered vocabulary. Customer support, where the user types “my wifi’s down” and the documentation says “loss of connectivity at the physical layer.” BM25 won’t catch that. Embedding will. Vector DB scores a point here.
- Non-textual modalities. Image-by-image search, audio-by-audio. Embedding is mandatory.
- Critical absolute latency. If you have to answer in 100ms with a 5k input budget, a generous dump won’t fit. Pre-filtering is necessary.
- Compliance and audit. If you have to prove that a specific document was consulted to answer a specific query, having indexed and trackable chunks helps. A 200k-token context dump is more opaque from an audit standpoint.
For those cases, classic RAG still makes sense. But notice the size of the list. These are specific cases. The general case, things like “chat with our internal docs” or “ask the product manual,” almost all of it falls into the “grep + long context handles it better” bucket.
Lazy retrieval: the recipe I’d defend
If I were building a “chat with docs” tool today, from scratch, it would look more or less like this:
- Keep the documents raw. Markdown, converted PDF, code, whatever. On disk, organized in folders that make sense for the domain.
- Fast lexical filter.
ripgrepwith regex, or BM25 with Tantivy/SQLite FTS5, or aLIKEin Postgres if you already have one. Returns 100-300 hits. - Load generously. Grab not just the matching snippet, but the entire file, or a wide window around it. Throw all of it into the context.
- Let the LLM do the fine work. Pass the original question, tell the model to find what matters, drop the rest, and answer with citations.
- (Optional) Add embeddings only for the query classes where lexical fails, after you have real data showing that it fails.
This is the opposite of the old advice (“start with vectors, fall back to keyword”). It’s: start with keyword, and add vector only if you feel the gap. In most projects, you never will.
A toy implementation in Ruby
To make it concrete. Here’s a Ruby script using the ruby_llm gem (the same one from yesterday’s benchmark) that does exactly this flow: grep through the files, load the snippets with context, send to Claude, get the answer back. No vector DB, no chunking, no embedding, no LangChain.
#!/usr/bin/env ruby
require "ruby_llm"
require "open3"
DOCS_DIR = ARGV[0] || "./docs"
QUERY = ARGV[1] or abort "uso: ./ask.rb <pasta> <pergunta>"
# 1. Fast lexical filter with ripgrep.
# -i case insensitive, -l file names only, --type-add covers md/txt/extracted-pdf.
def lexical_search(dir, query)
terms = query.downcase.scan(/\w{4,}/).uniq.first(8) # words with 4+ letters
pattern = terms.join("|")
cmd = ["rg", "-l", "-i", "-e", pattern, dir]
files, _ = Open3.capture2(*cmd)
files.split("\n").reject(&:empty?)
end
# 2. Load entire files (up to a reasonable cap).
def load_context(files, max_chars: 600_000)
total = 0
files.map do |path|
body = File.read(path)
next if total + body.size > max_chars
total += body.size
"## #{path}\n\n#{body}\n"
end.compact.join("\n---\n")
end
# 3. Send to Claude with the question and the documents.
def ask(query, context)
chat = RubyLLM.chat(model: "anthropic/claude-sonnet-4-6")
prompt = <<~PROMPT
Você tem acesso aos documentos abaixo. Responda a pergunta do usuário
usando apenas o que está nos documentos. Cite o nome do arquivo nas
referências. Se a resposta não estiver nos documentos, diga isso.
--- DOCUMENTOS ---
#{context}
--- FIM DOS DOCUMENTOS ---
Pergunta: #{query}
PROMPT
chat.ask(prompt).content
end
files = lexical_search(DOCS_DIR, QUERY)
abort "nenhum arquivo bateu" if files.empty?
puts "Encontrei #{files.size} arquivos. Carregando contexto..."
context = load_context(files)
puts ask(QUERY, context)About 40 lines. No Pinecone dependency, no vector schema, no re-indexing pipeline. You run it as ./ask.rb ./docs "how do I configure the payment webhook" and that’s it.
That example is one-shot. You run it, it answers, done. For a real chat, with multiple questions in a row over the same documents, the design changes. Instead of running lexical_search upfront and shoving everything into the context at once, you expose the search as a tool to the model. Then it’s the agent that decides when it needs to pull more docs, what term to look for, which file is worth opening in full. That’s how Claude Code actually works: Glob, Grep and Read are tools, and the model picks the sequence. ruby_llm supports tool calling, so you can do the same thing in Ruby. It looks something like this:
require "ruby_llm"
require "open3"
DOCS_DIR = "./docs"
class SearchFiles < RubyLLM::Tool
description "Procura arquivos cujo conteúdo casa com o padrão dado (regex). Retorna lista de paths."
param :pattern, desc: "Padrão regex pra busca lexical (case-insensitive)"
def execute(pattern:)
out, _ = Open3.capture2("rg", "-l", "-i", "-e", pattern, DOCS_DIR)
out.split("\n").reject(&:empty?)
end
end
class ReadFile < RubyLLM::Tool
description "Lê o conteúdo completo de um arquivo do projeto."
param :path, desc: "Caminho relativo do arquivo"
def execute(path:)
File.read(path)
rescue => e
"erro: #{e.message}"
end
end
chat = RubyLLM.chat(model: "anthropic/claude-sonnet-4-6")
.with_tools(SearchFiles, ReadFile)
.with_instructions(<<~SYS)
Você responde perguntas sobre os documentos em #{DOCS_DIR}.
Use search_files pra encontrar arquivos relevantes e read_file
pra ler o conteúdo. Sempre cite o arquivo na resposta.
SYS
loop do
print "> "
msg = gets&.chomp
break if msg.nil? || msg.empty?
puts chat.ask(msg).content
endThe model gets the question, decides whether it needs to search, calls search_files, sees what came back, decides whether it needs to open any file, calls read_file, and only then answers. On the next question it already has the previous context in the session and can ask for more if it needs to. The context only receives what the model asked for, not the whole grep dump from the earlier example.
The same idea works for databases: swap rg for a SQL query with LIKE or tsvector (Postgres full-text), load the relevant rows, throw them in the context. If you have 10k records in an internal database, this handles it. If you have 10 million, you start needing smarter pagination or a more serious pre-filtering layer. But the mental model is the same: dumb filter + smart reader.
The point that matters
The most interesting thing in all of this isn’t even the Pinecone savings. It’s that the nature of the bottleneck has changed. In 2023, the bottleneck was retrieval: the reader was small, slow, expensive, and you needed a clever retriever to fill the window with the bare minimum. In 2026, the bottleneck is reasoning over messy context: the reader is big, relatively fast, and cheap. So it makes more sense to have a dumb retriever with high recall and let the model do the heavy lifting.
Anyone still designing systems with the 2023 mindset is paying a premium to solve a problem whose shape has changed. RAG didn’t die, the “R” got dumber and cheaper, and that’s an upgrade. The vector DB vendors aren’t going to tell you this, but it’s the path the more experienced folks have been quietly walking.
The next wave of LLM applications, in my bet, is going to be dominated by the people who got this inversion. Smaller stacks, simpler infrastructure, generous context, and a whole lot less LangChain.
What the recent literature says
Before I close out, I went and checked what the research crowd published on this. Blog hot takes age in three months in this field, so it’s better to look at the papers.
Retrieval Augmented Generation or Long-Context LLMs?, out of Google DeepMind, published at EMNLP 2024, is probably the most cited piece in the debate. Their conclusion: when the model has enough resources, long context beats RAG on average quality, but RAG is still much cheaper in tokens. They propose Self-Route, an approach where the model itself decides whether it needs retrieval or whether it can just go straight through context. The token savings are big and the quality loss is small.
Then LaRA, presented at ICML 2025, is more measured. The authors built 2326 test cases across four QA task types and three long-context types, ran them across 11 different LLMs, and the conclusion was: there is no silver bullet. The choice between RAG and long context depends on the model, the context size, the task type, and the retrieval characteristics. RAG wins on dialogue and generic queries, long context wins on Wikipedia-style QA.
Long Context vs. RAG for LLMs: An Evaluation and Revisits, from January 2025, is the one that most reinforces this post’s thesis. Long context tends to beat RAG on QA benchmarks, especially when the base document is stable. Summarization-based retrieval comes close, and chunk-based retrieval lags behind. In other words: the old way, chunk plus embed plus top-k, is the one that comes out worst.
Worth keeping on the radar too is the original Lost in the Middle (Liu et al., 2023, published in TACL in 2024). That’s the paper that showed even models with big windows have performance that depends on the position of the relevant information. Stuff at the beginning or end of the context is found easily; stuff in the middle degrades. For a long time this got used as the argument against long context, but the paper is from 2023, with 2023 models. Today’s models, the Claude 4.x and Gemini 3.x line, handle the middle a lot better. It’s not a solved problem, but it’s much smaller than it was.
On the lexical retrieval side, BEIR is still the canonical reference. The classic result is that BM25, all the way from the 90s, is still ridiculously competitive in out-of-domain scenarios. Dense models only win consistently when you have in-domain data to fine-tune the embeddings. In zero-shot scenarios, which is where most projects live, BM25 is hard to beat without serious work.
To wrap up, the Anthropic post on Contextual Retrieval, from September 2024, is the most practical piece on the list. They show that combining contextual embedding with contextual BM25 drops the top-20 failure rate from 5.7% to 2.9%. Add a reranker and it drops to 1.9%. Important detail: BM25 is the centerpiece of their result, not a sidekick. The right reading is “lexical plus vector plus reranker is the combination that works.” Anyone who can only pick one picks BM25 and still gets pretty far.
To sum up what we can actually nail down: the literature isn’t claiming “RAG is dead.” It’s saying that long context, when you can use it, tends to win on quality. It’s saying RAG’s cost is still its main argument. It’s saying lexical BM25 is much stronger than the vector DB marketing makes it sound. And it’s saying that when you really do need heavy retrieval, the robust combination is hybrid (lexical plus vector plus reranker), not pure vector. All of that lines up with what I’ve been defending in practice.
Sources
- Li, Z. et al. (2024). Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach. EMNLP 2024 Industry Track.
- Yuan, K. et al. (2025). LaRA: Benchmarking Retrieval-Augmented Generation and Long-Context LLMs – No Silver Bullet for LC or RAG Routing. ICML 2025.
- Yu, T. et al. (2025). Long Context vs. RAG for LLMs: An Evaluation and Revisits. arXiv:2501.01880.
- Liu, N. F. et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. TACL 2024.
- Thakur, N. et al. (2021). BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models. NeurIPS Datasets and Benchmarks 2021.
- Anthropic (2024). Introducing Contextual Retrieval. Blog post.
- Akita, F. (2026). Claude Code’s Source Code Leaked. Here’s What We Found Inside. — my coverage of the leak, with more detail on the memory architecture, KAIROS and
autoDream.