RANT: Did AI Kill Programmers?
Anyone who only watched clips and hot takes, without watching my videos about AI on my channel, or at least the podcast on Flow, thinks I said the following:
“AIs will NEVER replace ANY programmer”
And that’s wrong. Watch the video with the explanation (or look for the transcript). But in short, what I said was:
“AIs will never replace programmers LIKE ME — I will never be replaced”
Another thing I stated and keep stating is:
“AGIs are not possible in the current architecture: it’s not going to happen. A new discovery needs to show up — one we obviously don’t know yet — to break past the current barrier, which is insurmountable.
And that’s where I derived this line from:
“Your excitement about AI is inversely proportional to your knowledge about AI” — and it still holds just as well.

The Programming Bubble Already Popped
My channel started in 2018 and ran until early 2024, with a single purpose:
Helping to prepare real programmers to survive the imminent popping of the bubble (which started around 2014).
I have a whole playlist titled I TOLD YOU SO.
In short, in recent years, “programming” became the “profession of the future”, and it seemed easy. It got obvious when all you saw was ads for every kind of course and bootcamp, with promises like: “become a programmer in 2 months, earn a Google salary, and you barely even have to work.”
I called this kind of programmer the “instant noodle chef”. Just because you know how to boil water and make instant noodles doesn’t make you a chef. It should be obvious, but that’s how programming was sold. None of those courses produced any “programmer”, let alone a “software engineer”.
But “software engineer” is not real engineering. There’s no CREA, CRM, OAB, or any equivalent body that certifies anyone as a “software engineer”. It’s a made-up title anyone can slap on their LinkedIn.
The Black Swan of the Pandemic was something I didn’t predict, but it only helped inflate the final phase of the bubble even further, which popped at the end of 2022 when mass layoffs began across every big tech. And that was BEFORE the advent of LLMs for programming. Coincidentally, ChatGPT showed up around the same time in 2022, but it was not the cause; it was just the last nail in the coffin. The popping of that bubble and the layoffs would have happened anyway.
That’s why my channel must be the only one that, to this day, offers the content someone who actually wants to be a programmer needs. Imagine the other channels that only pushed the narrative that becoming a programmer was easy — they aged VERY badly.
So yes, I agree with Anthropic’s CEO: those “software engineers” will become completely obsolete. Nobody becomes an “engineer” in a 1-month bootcamp. That was bullshit and you had to be really dumb to believe it. Notice how all those snake-oil sellers VANISHED. Where are they?
Don’t know where to start on my channel? Two suggestions:
- Playlist “What courses should I take?”
- Playlist “Career”
The AI “Ceiling”
I finished recording videos for my channel exactly when the AI wave started. I considered that everything I wanted to say had already been said and it all remains available on the channel. My goal was accomplished.
During 2024 and 2025 I took part in podcasts like Flow and Inteligência Ltda talking a lot about AIs and things like quantum computing (and how it too is just hype that won’t amount to anything practical in our day-to-day).
The main point: since the transformers paper Attention is all you need, no other “breakthrough” has appeared that surpasses that milestone. Everything we have today, from OpenAI to Anthropic, and from open sources like DeepSeek, Qwen3, GLM, MiniMax, etc., is based on exactly the same foundation, the same “architecture”.
And I theorized — correctly — that the evolution of this architecture would follow an S-curve:
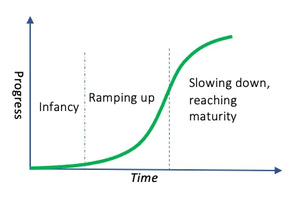
GPT-1 to 2 was a quantum leap. GPT-2 to 3 was a gigantic leap. GPT-3 to 4 was excellent, but, notably, not in the same proportion. GPT-4 to 5, most regular people barely noticed the difference.
Of course, nobody stood still; every computer scientist, mathematician, engineer kept doing what we always do: optimizing. Better training methods showed up, the idea of “reasoning”, the idea of agents working together (one giving feedback to another), new forms of alignment and instruction. But none of that changes the foundational architecture.
The problem: training each new generation of LLMs gets considerably more expensive (in hardware and, mainly, in energy consumption) to produce a version that isn’t much better than the previous one. That’s the ceiling of the curve. And I reaffirm: until a NEW ARCHITECTURE appears, we’ll only get closer and closer to that ceiling, without crossing it, while spending absurd levels of more memory and more energy.
That’s why there’s an energy shortage: with the increase in usage demand (inference), they have to split between spending energy on training new versions and serving demand. They can’t do both.
Worse, that’s why RAM prices exploded and your PC will get much more expensive too. There are no more resources to train models so big that, proportionally, deliver less and less result (the definition of “diminishing returns”). It’s the fate of every innovation: hitting the ceiling of the S-curve until another one comes along to replace it.
The focus now is on using the versions we already have better. In the programming case, you get GPT Codex or Claude Code, which are strategies for using agents, MCPs, skills, and other tools and forms of orchestration to squeeze the maximum out of what we already have today.
LLM Strategies
Everyone already knows it’s impossible to just write a prompt and have any LLM spit out a perfect system in the end. It will come out very bad; it stays that way and will stay that way in this architecture.
Every LLM has a context (memory) limit. It’s impossible to load the entire source code of a giant ERP like Totvs’s or SAP’s. It doesn’t fit, and even if it did, it wouldn’t be possible to give “attention” to all of it. There are limits: the more memory you load, the worse inference gets; the result gets worse. Like everything in software, it’s a “trade-off”.
Instead, the best thing is to create scripts that walk through your code and extract specific chunks on each run. If you’re working on the shopping cart, you don’t need to load the code that handles the store’s landing page, for example. It’s similar to what a human programmer would do: divide and conquer (as Napoleon would say).
Every LLM specialized in code, like Codex or Opus, was trained to do “tool calling”, which is sending a request to the “chat” so it can fetch information (such as code) and load snippets into the context. For that, it has it run tools like “rg” ripgrep (in Codex’s case) or “grep” (in OpenCode’s case).
If, by chance, the model wasn’t trained on information that only recently came out on the Web, it can do “agentic fetch”, which is executing commands like “curl” to literally go to Google, Stack Overflow, etc., and pull web pages in to use as part of the context (the trade-off is that this will use up the limited context space).
When the context is about to run out (the 200k token range, in Claude’s case, or 1 million, in Gemini’s case), the “chat” that orchestrates (Claude Code, OpenCode, etc.) triggers a summary of the current context, to “compact” the understanding and restart with a new context based on that summary.
To make sure the generated code “works”, tool calling asks it to run local tools like linters, compilers, or LSPs (like an IDE, like VSCode, would). This produces feedback (and burns more context). If it errors, the “chat” can automatically ask it to redo the work, taking this new information into account.
Also, to go “faster”, the “chat” can fire off multiple agents in parallel. Each agent is a new context — and none of this is free, remember: tokens per second. So, it could send one agent to comb through all the code relevant to the database and, at the end, produce a summary. Another agent combs through all the payment code and, at the end, generates a summary. Another agent combs through the cart front-end code and produces a summary. Then the “chat” takes those summaries and goes back to the previous context to execute some task.
What I call “chat” is just to make it easier to visualize. Think of the simple chat interface everyone uses day to day, but with additional features. That’s what a Codex or a Claude Code does. There’s no secret, every tool like this, as well as open source ones like OpenCode or Crush, do the same thing: they set up a “Harness”:
- They start with a system prompt detailing exactly how they want the LLM to respond. This GitHub has several examples of these prompts the tool sends without you knowing.
- LLMs are trained with tool calling and the tool knows how to respond to those calls (executing bash, curl, ripgrep, sed, diff, git, etc.)
- The tool is capable of running multiple agents in parallel (think multiple “chats” in parallel)
- The tool asks the LLM to produce a “plan” first and enumerate tasks. Then it can orchestrate the sequential execution of those tasks, each in a different agent, for example.
- The tool is capable of managing context limits and knowing when to trigger a summary, and how to start a new context and continue executing the remaining tasks
- The tool is responsible for creating a container and preventing badly formed commands from affecting your system (this is optional; not all of them do it or care by default. Watch out!)
I’ve documented this in several posts on this blog:
- LLM Hello World: building your own AI chat that runs locally
- Rant — Will LLMs evolve forever? Demystifying LLMs in programming
- When Don’t LLMs Work for Programming? A more realistic use case.
- AI Agents: Locking Down Your System
- AI Agents: Comparing the main 2026 LLMs on the Zig Challenge
- AI Agents: Installing LSPs for Crush
- AI Agents: Which one is best? OpenCode, Crush, Claude Code, GPT Codex, GoPilot, Cursor, WindSurf, AntiGravity?
- Vibe Code: I built a little app 100% with GLM 4.7 (TV Clipboard)
- Vibe Code: Which LLM is the BEST?? Let’s talk for REAL
- Vibe Code: I built a Markdown Editor from scratch with Claude Code (FrankMD) PART 1
- Vibe Code: I built a Markdown Editor from scratch with Claude Code (FrankMD) PART 2
The End of Stack Overflow
Back in the GPT-3 and GPT-4 days, I was already writing code using LLMs and it worked well. But they still had lots of annoyances. Hallucinations were very frequent. There was a lot of “agentic loop” (when the LLM “thinks” it already fixed something, but it didn’t, and it stays in a loop, not knowing what to do). Attention to context was easily lost (it improved a lot with Flash attention). Basically, several “rougher” issues have been ironed out to the point that they don’t show up as often. It’s not “solved”; it still happens, but it keeps getting better.
The more training data and alignment improved, the more those problems disappeared. The problem is we’ve already reached the point where the training data in the world has run out. Everything that could be used has already been used. It’s not just the lack of energy and hardware. The information to train on is gone.
The solution was to massage existing data to squeeze the maximum possible out of it and add lots of synthetic data (generated by the AI itself). Again, this already hits a “diminishing returns” ceiling.
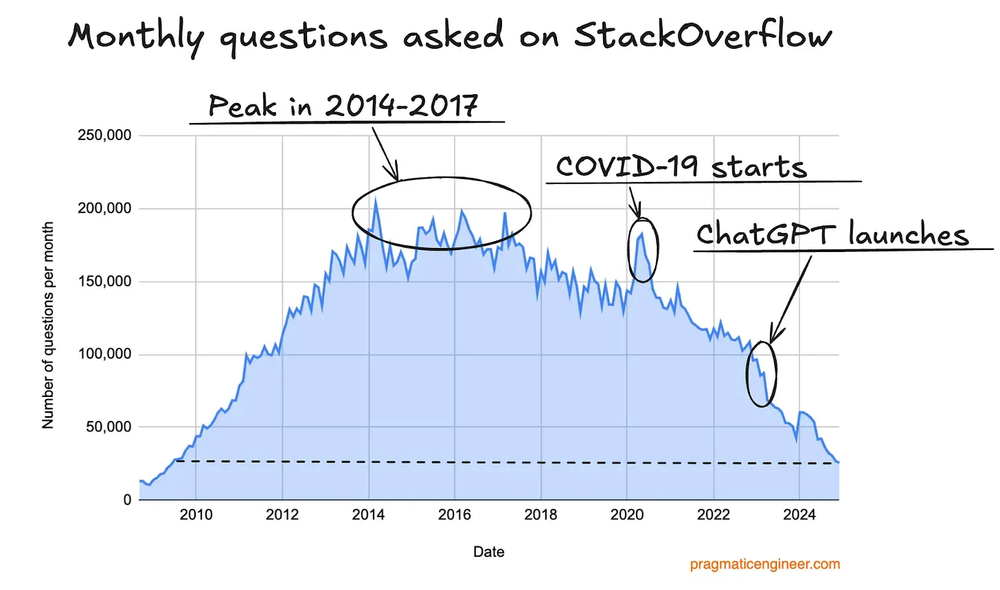
On top of that, several sites used to extract LLM training data are falling into disuse. The most notable example is the venerable Stack Overflow. Look at how its traffic has dropped.
Some clueless people might just think: “ah, it’s fine, people started asking dumb questions to LLMs instead, no more piles of people posting basic questions in forums.”
It’s true, it seems like progress. But even a “dumb question” is relevant training data. If the LLM “sees” that certain topics have higher probability, when it gets the same question, it “tends” to give the most popular answer. If this data disappears, so does the relevance of lots of new topics. Now, each LLM will depend on using the questions asked in its own chat as new training data, except OpenAI will only have questions asked to it, and it won’t know which are the most popular questions asked in Claude, which shrinks the sources of relevant information more and more.
What every platform must be doing now is collecting every question you ask it, every answer the LLM produced, every bit of feedback you or your tools give on whether it was a success or an error, and stacking it up to train the next version, GPT-6 or Sonnet-5. Let’s see how much you can evolve with just that — remembering that “volume” of information doesn’t equal “quality” for training. That’s still the Achilles heel.
The point is: at least temporarily, most of the relevant data on the Web has run out, and we’re producing less than before.
Constraint == Innovation
Yes, I also believe an entire category, which called itself “software engineer”, is going to stop existing because of AIs.
That weird “specialization” of “front-end who doesn’t touch any back-end” or “back-end who doesn’t touch any infra” will no longer exist. Front-end, in particular, is the easiest to replace, because it was a huge volume of low-value-added code with lots of duplication. It wasn’t hard to automate, but nobody wanted to: it was “cooler” to keep inventing new frameworks every week that do the same thing in slightly different ways. That circus is finally over.
I lectured for years on Constraint == Innovation and how innovation doesn’t happen when you have money to burn, which is what happened in the last Programming Bubble: why automate things, be efficient, if there’s money to spare? Just hire more and more people to do simpler and simpler grunt work.
In the Internet Bubble, there was so much money to burn that a “website cataloguer” profession existed: people who spent all day manually typing in every new site that appeared on the newly launched Web. It took years for an Altavista and then a Google to show up and figure out how to automate this. Back then, there were no “web admins” to publish new products in an e-commerce site: someone edited the HTML of Submarino.com’s homepage every day, with new deals. All high-volume, low-value-added work. We automated all of that, and now, with LLMs, we’ve just gone one step further.
Even before LLMs, it made no sense to need people exclusively to churn out disposable HTML/CSS all day. The slightly more automatic tools, like a SquareSpace.com of the world, weren’t all that good.
The thing is: something simple, like a “Web Admin” to edit content without needing to know HTML, didn’t exist in the 90s. Someone had to build the first versions of that kind of software so we could understand what works and what doesn’t. Anyone from the 90s will remember expensive commercial software like the famous Vignette Story Server. Today, any open source Wordpress does the same thing better.
Nobody remembers software and companies that no longer exist. Especially young people think the world showed up with the Web ready-made, with social networks ready-made and e-commerce platforms ready-made. The feeling must be that, in Ancient Egypt, people already shopped on Amazon, ordered delivery on iFood, and everyone chatted on WhatsApp. I made a video called The Dimension of Time, My Time Machine and My First Five Years to try to give some perspective on this.
The point is: everything LLMs know how to do either already exists or already existed.
They’re not capable of inventing whatever it is, be it the “Vignette of the 2030s” or the “Instagram of the 2030s”. And I don’t mean that in the sense of the “next content manager” or “next social network”. I mean in the sense that “social network” was a term that didn’t exist in the 2000s and “content manager” didn’t exist in the 80s, for example. What’s the new category that will show up in the 2030s?
I don’t know; if I did, I’d obviously be building it to launch and become a billionaire. Nobody knows, much less LLMs. They can derive a lot of things from training, but what’s not in the model’s probabilities won’t “spontaneously” appear. That’s not how AIs work.
We can stay forever just redoing everything that’s already been done the same way it exists today. But not much more than that. But the whole point of my talks was exactly that innovations are not born from just having tons of money and tons of brute force.
Programmers in the LLM Era
The conclusion is very simple: programmers like me will always exist. What always stops existing are professions that only have volume but low added value. That’s the concept.
As I said in my videos, during my career I’ve already survived the end of the microcomputer bubble in the early to mid 90s, the internet bubble from the mid 90s to the early 2000s, the 2001-2008 programming recession, the financial housing bubble that popped in 2008 but gave birth to the programming bubble, especially from 2014 to 2022, and now the AI bubble.
Don’t fool yourself: it’s always like this, and this is nothing more than another episode.
Who’s the programmer that survives all these bubbles? This one:
The ceiling of LLMs is already here and what they’re delivering now isn’t going to change much: the process is going to be the same. It’ll get a bit faster. It’ll generate a few less errors and small tweaks like that. But the process will keep being the same until some new architecture or some new discovery we don’t know about yet shows up.
No AI-generated code will be automatically perfect to be put into production without any kind of review or human intervention. — Anyone who thinks otherwise either has never tested an LLM in practice or has never worked on real projects.
As I said on Flow, this is the SECOND AI Bubble. The first was in the 60s because of the inventor of neural networks, Frank Rosenblatt. Just like Sam Altman or Dario Amodei, he also hyped neural networks and computers that were going to get much smarter than human beings “very soon”, and every newspaper at the time wrote about it. The promises died as promises and that generated the “AI Winter” in the 70s, where tons of investment was made, the result was not proportional, and AI research stagnated for the following decades, crawling at a turtle’s pace.
That only really started to change with the advent and popularization of the Web, the rise of social networks, the emergence of Big Data, and now, with huge volumes of data to kick off a new era of research on neural networks, with a lot more training material. And now with the existence of GPUs to accelerate processing. That’s when AlexNet showed up, from Geoffrey Hinton, Yann LeCun, and Ilya Sutskever, the “breakthrough” of convolutional neural networks (CNNs) and parallel processing via GPUs.
Without that, we wouldn’t have moved on to transformers, diffusers, and things like Nano Banana and Sora. This is a type of area where LLMs won’t contribute: cutting-edge research and new discoveries. In that field, we’ll still need computer scientists, mathematicians, theoretical physicists, etc. If you have a calling for research, it’ll still be a fertile area for many years. The bar only went up, which is a good thing.
About the Claude that managed to build a C compiler:
A C compiler is the easiest to build; it’s literally college material, because C is one of the “simplest” languages (it started as Assembly macros).

As Anthropic’s own article — which nobody read, of course — says, they used GCC for comparison.
Of course, GCC exists; it’s the main compiler used to compile the Linux kernel. If you copy GCC, you’ll arrive at another GCC, no matter what other language you write it in — that’s not the hard part, because every language can do everything another language can (they’re all Turing Complete: it can be slower, it can be less safe, it can be more work, but I can write a C compiler in Visual Basic if I want, that’s not impressive).
No LLM has replaced Linus Torvalds, nor Richard Stallman, nor any of the great programmers whose names you’ve heard. They can copy what’s already been done, and that’s it. Yes, they are “stochastic parrots”, regardless of what a Geoffrey Hinton tries to propagandize in his own favor (everyone has biases). By the way, as I’ve already said on podcasts: fuck Geoffrey Hinton. Stop falling for the Appeal to Authority Fallacy.
A Word to Companies
This should be obvious, but I’m going to put it on the record just so I can say “I TOLD YOU SO” later.
- No LLM is going to write code on its own. It needs a senior to spec it out.
- Every LLM-generated piece of code needs review. It needs a senior to review it.
- Part of the generated code needs to be rewritten. It needs a senior to know that.
- Another part of the code will have bugs the LLM will miss. It needs a senior to know that.
- Knowing what these bugs are, you can have the LLM fix them.
With that said, some things LLMs do very well:
- Exploratory analysis of legacy code
- Refactoring parts of legacy code
- Adding unit tests to parts of legacy code
- Suggesting improvements to parts of legacy code
- Finding some security or performance holes in legacy code
Notice how I say “parts” or “some”. There’s no guarantee it can do this on any legacy codebase or any part. Again, it needs a good senior evaluating each step.
Everything is done STEP BY STEP. An attempt, a check, an adjustment, repeat. It’s the famous PDCA cycle: Plan, Do, Check, Act. That’s the process that works. Every new tested adjustment becomes a “git commit” and we move on to the next step. Always one step at a time, systematically, in an organized manner. Never something generic like “Fix everything in this legacy system”.
Another thing LLMs are very good at is rewriting code from one language to another (translations in general). But I don’t recommend it, and not just because it’s an LLM:
I never recommend rewriting from scratch as a first option.
There’s no guarantee a newer language is “better” than an older one. “Better” always “depends” on your definition of “better”.
It’s trendy now to rewrite everything in Rust because supposedly it has fewer security problems. That’s incorrect. Rust is good for certain categories of security, not all of them. And there’s a whole category of functional problems that don’t show up in any compiler. Rewriting something complex, like a Linux kernel, in Rust is a gigantic illusion and a waste. If it “seems easy” to have an LLM rewrite it in Rust, it’s equally easy for it to fix a small bug in C precisely, without touching the rest that already works.
Rewriting is indeed a guarantee that several new bugs will appear and you won’t detect them right away; it’ll be a new time bomb. To fix one known bug, you ended up creating several other unknown bugs. Rewriting, by definition, always adds new bugs.
And no, when you ask the LLM: “find all the security bugs in this code”, it’s going to find some, but never all of them.
Understand Portuguese: it’ll always say something like “Here are all the bugs I found…” Even today’s LLM won’t try to say “Here are all the bugs that exist” anymore.
No AI is built to give 100% correct, unambiguous answers. On the contrary, it’s always a probabilistic machine that will give the answer based on the probabilities of the model generated by training. What’s not in that model, it doesn’t know. And even giving it context, there are no guarantees of “complete understanding”, only of “some understanding”. Always work with probabilities below 100%.
Programming languages, by their very nature, are not deterministic. There’s no way to write a mathematical equation where I can feed it the program and it guarantees the absence of bugs. This is a mathematical impossibility; it’s not “a matter of time”. Time is not relevant to that definition.
Bug detection (functional, security, performance, etc.) is always a stochastic process, a heuristic, never an algorithm. This is something every computer scientist or mathematician understands, but nobody who’s never studied can understand. For regular people, heuristic is the same as algorithm. That’s a mistake that can be fatal.
So, every LLM, by its very foundation and architecture, will always have these and other limitations built in. But that’s not a problem, that’s just the nature of the tool. Hammers aren’t meant to turn screws, and that’s not a flaw. It should be obvious, but hitting a hammer on a nail and not turning it is a natural characteristic. It’s neither an advantage nor a defect. It depends on what problem you want to solve.
Overall, LLMs will be very good at handling grunt work: adding tests, refactoring code, tweaking front-end, creating new screens from old screens, creating new reports from old reports. Creating Portuguese-to-Spanish translations of your system’s screens. For that kind of nail, LLMs are the perfect hammer.
Now, precise interpretation of laws, business rules, individual cases and exceptions to the rule, relaxing certain rules — everything that’s part of decision-making in a company. Never fully trust any LLM: you’ll need an experienced human to approve or reject. No matter how much it has memorized all the country’s laws, there’s no guarantee it knows when to use or not use them, and how that can vary in the most diverse cases, especially in the exceptions.
Never ask a hammer how you should run your company.
“How do you get seniors if there won’t be juniors anymore?”
Notice that the premise is that, at minimum, you’ll always need a senior instructing and reviewing the LLM’s work.
But if LLMs can perform all the grunt tasks that used to go to interns and juniors, how are they going to grow into seniors?
It’s the billion-dollar question and I’ll say upfront I don’t know the full answer. Nobody does.
The start is easy. It’s what I said in every video on the channel: it’s how I made my entire career: having a solid education and “learning to learn” for real. Easier said than done; that’s why I spent 5 years of videos trying to explain it in every way I could, to see if anyone would get it.
The next part is the hard one: how do you learn if LLMs already do everything?
This question starts from a false premise: LLMs don’t do everything. They do what they’re asked to do. If the request is well specified, it’ll come out like a gourmet dish from a 3-Michelin-star restaurant. If the request is lame, from someone clearly inexperienced, it’ll come out as instant noodles. It’s that simple.
The LLM’s result is directly proportional to the work of instruction, evaluation, and follow-up from the human in control.

“How is someone going to be a programmer if they don’t even know how to punch a card?” — It’s a fair question to ask someone in the 60s.
“How is someone going to be a programmer if they don’t even know how to save to a cassette tape?” — Another fair question, if it’s someone from the 80s.
“How is someone going to be a programmer if they don’t even know how to edit code in a text editor like Emacs and needs Eclipse?” — Another fair question, if it’s someone from the 90s.
“How is someone going to be a programmer if they don’t even know how to code for the Web?” — A good question for someone in the early 2000s.
“How is someone going to be a programmer if they can’t even build a mobile app?” — If it’s someone in the 2010s.
“How is someone going to be a programmer if they have LLMs?” — The question of the 2020s. Good luck.
Every generation has similar questions. None of them have an exact solution. Look at the facts: we’re still here. In 2026, I know things about programming I never dreamed I’d know when I entered college in 1995. Everything has changed. Everyone who “learned how to learn” knew how to ADAPT and use the knowledge they already had to learn new ways of working.
It’s all about adaptation: those who don’t adapt go extinct. That’s the law.
There’s not much more to say about this. But in practice:
If you’re a programmer, use LLMs. Learn their strengths and weaknesses, the different results they produce depending on your own knowledge, and never stop studying and training.
If you’re a senior/company, keep hiring juniors. Your seniors aren’t immortal. At the very least, eventually they’ll retire. More realistically: eventually they’ll change jobs. The second most important task of any senior is mentoring juniors and creating replacements. A senior incapable of creating their own replacement isn’t a senior, they’re a liability.
Mentoring is the same thing as always: training with follow-up and feedback, continuous improvement, with the difference that, besides operating system, text editor and IDEs, CI systems, etc., now there’s LLMs in the toolbox. That’s it. Don’t try to complicate what doesn’t need to be complicated and don’t suffer in advance.
Conclusion
“Ugh, but you said the AI bubble is going to burst.”
Yes, and I still say so. But you’re misunderstanding again. From 1994 to 2001 there was the Internet Bubble, and it burst!
Understand: the “Internet Bubble” burst. But the “Internet” still exists to this day. Is that clear?
Same thing: the “AI Bubble” is going to burst, many companies are going to go bankrupt, many people in the field are going to lose their jobs, etc. But AIs will keep existing. The AI bubble of the 60s burst, but AIs kept existing and even formed a new bubble now. Economic cycles have nothing to do with technological cycles.
It just means: “don’t bet all your chips on the same horse, especially if your life/career depends on it.”
LLMs will keep existing, roughly in the same form, a bit faster and more efficient, but with the same process behind them and the same way of working. Just like the Web of 2026 isn’t much different from the technology of the 90s, but is more refined and optimized.
I was never an AI “hater”; on the contrary, I’m someone who was already risking writing code with GPT-2. And it’s always improving. It’s now at a point where it’s easy to recommend even to non-programmers playing with systems that aren’t going to production and aren’t mission-critical.
Since I started with programming, at the end of the 80s, thankfully I’ve never had a single moment when I thought our field was “boring” or “monotonous”. For me, this is just another chapter in this story, and I’m expecting new chapters.
What I say that “sounds like hate” is just arguing and explaining the current limitations and the unrealistic expectations, illusions, or even blind bets I know aren’t going to pan out. I’m warning about what’s real. But I’m always saying: “there needs to be a new discovery”. With the expectation that something more is coming in the future, and not that “nothing’s going to work out”.
At the end of the day, the Java of the 90s didn’t replace the Cobol and Fortran of the world, as was intended. The Web didn’t turn into a peaceful utopia of pure knowledge as people wanted. Mobile didn’t replace other forms of computing as people wanted. VR didn’t become the new wave. None of that invalidates the qualities of Java, the Web, Mobile, or even VR.
The last Programming Bubble was a boring period for me in terms of innovation: because everything was being replaced by cheap programmers. For me, the bursting of that bubble was expected and makes me very happy. Because we finally came out of the drudgery of idiotic courses to talk about cutting-edge technology again. Programmers going back to being real programmers.
I only see good things in this.