AI Agents: Comparing the Top LLMs of 2026 on the Zig Challenge
Early 2026 got me excited to poke around LLMs again. Two reasons: testing Charm Crush (an alternative to OpenCode, Cursor, etc.) and testing newer LLMs like Claude Opus and GPT Codex to see how they stack up today.
Before diving into details, some disclaimers: everything I’m about to say is based on a relatively simple and short code problem - which I’ll explain in the next section.
Don’t generalize this to any project, of any size or complexity. This is a purely opinionated article, not an analytical one.
Since it’s going to be long and I’ll touch on many different subjects, I’ll start with the TL;DR for those too lazy to read to the end:
- The main commercial LLMs nowadays seem to be Claude Opus 4.5, GPT 5.1 Codex, GPT 5.2 (I haven’t had access yet to GPT 5.2 Codex, which they say is much better), Gemini 3 Pro Preview.
- The main open source LLMs nowadays are still Qwen3-Coder, GPT-OSS, Deepseek v2 and the new GLM 4.7 and MiniMax v2
Without further delay, by far the best - in my little test - was Claude Opus. Because of it, I decided to test the others to see how they compare. It was the only one that solved the problem right on the first try, without needing additional prompts or having to insist, and it was also the fastest, by a long margin.
But all 3 commercial ones I tested managed to solve it. Some took more work, but all of them eventually solved it. More details below, but my ranking is in this order:
- Claude Opus
- GPT 5.1 Codex
- GPT 5.2
- Gemini 3 Pro Preview
As for the open source ones, none of them managed to solve my problem. So it’s the same as a year ago. I had hopes that GPT-OSS at 20 billion parameters and Qwen3-Coder at 30 billion - which fit in my RTX 5090’s 32GB of VRAM - had improved, but no. GLM 4.7 and MiniMax v2.1 are too big. I had to run them through OpenRouter.ai.
That doesn’t mean they’re useless, but for the kind of problem I tried to solve, none of them did very well. My ranking looked like this:
- MiniMax v2.1 (very slow, but managed to get it to compile, yet didn’t solve a runtime error)
- GPT-OSS:20b (couldn’t get it to compile, but was faster)
- Qwen3-Coder:30b (couldn’t get it to compile)
- GLM 4.7 (very slow, couldn’t get it to compile and at one point stopped working completely - possible bug in Crush)
Before anyone starts commenting “But what about DeepSeek??” - I’ll warn you upfront that I couldn’t use it. I’ll explain later.
My recommendation is, when in doubt, start with Claude Opus or GPT 5.1 Codex. Both are comparable, each may be better for certain types of problems.
Now let’s explain the problem.
The Zig Challenge
A year ago I tried out “vibe coding”. But not to make a basic web to-do list. I decided I wanted to build a command-line chat app that would load an open source model like Qwen, and I could talk to it. It’s what ollama or VLLM already do, but I wanted to build it from scratch.
To add some difficulty, I thought the following:
- a low-level language that nobody uses (so there’s little documentation, forums and examples on the web). That’s why I chose Zig
- integrate with a C or C++ lib to make it even harder and mix low-level languages. That’s why it’s not just a client to talk to an Ollama server, it has to use the Llama.cpp lib directly. I want to load the model directly.
In short: it was an enormous ordeal!!!
The experience was so bad - I don’t remember if at the time I was using Gemini 2.5 or Sonnet - that I never got to a point where the code even compiled. And I dropped that project unfinished.
Here’s the repository with the unfinished code.
A year later and with new LLM versions, it’s a good problem to revisit, especially because we have the following new difficulties:
- Zig released a new version, 0.15.x, which changes A LOT. Being a language still in development and pre-1.0, it means each new version changes APIs for everything and breaks everything.
- Llama.cpp also evolved and released new versions that also break compatibility.
But today we have better orchestrators than Aider, which I was using back then: OpenCode and Crush exist.
The challenge is simple: update the code to be compatible with Zig 0.15 and the new Llama.cpp. Fix the build and correct each of the errors. Generate an executable. Get it to run, load the Qwen3 model on my GPU and open an interactive chat where I can talk to the LLM. And without crashing, without memory leaks.
Let me give some examples of what needs fixing. To start, the zig build command doesn’t even run anymore because the API for declaring modules to compile has changed. See this small snippet:
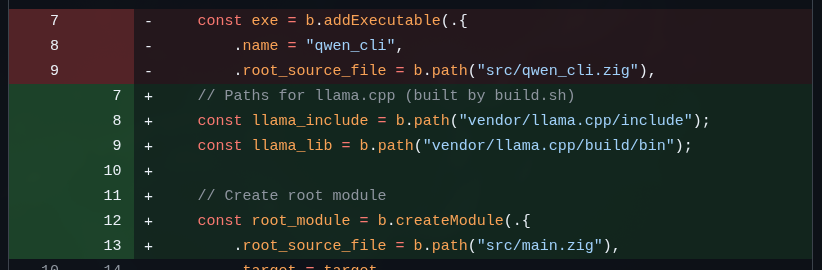
Practically all the LLMs managed to get past this problem. Some took longer, but at least all of them got a build going. Then it’s fixing the errors that show up in the build. Here’s an example:
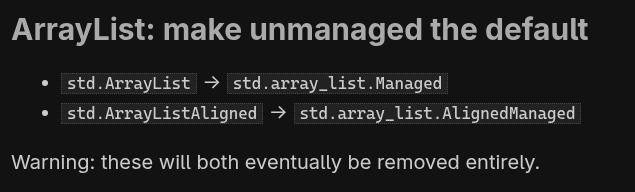
ArrayList changed in version 0.15. And this problem was one that half the LLMs struggled A LOT to solve. It involves “Agentic Fetch”, going to the web and consulting the migration document and code examples. It’s not that hard, but some took more than an hour and barely managed.

This is a snippet of how to map C functions (from llama.cpp) into Zig. Most had several problems solving this. You need to consult the llama.h that’s in the source code at ./vendor/llama.cpp. Some even managed to get it to compile. But that doesn’t guarantee it works. When I loaded the binary, it gave a segmentation fault and other crashes. You needed to know which functions you could use, how to handle NULLs and things like that. Most couldn’t get past this part.
And just to make things worse, I also asked to refactor the code into smaller files. The original unfinished version was a single gigantic qwen_cli.zig. Refactoring wasn’t that hard and all the commercial ones managed it. The open source ones didn’t get to this point.
Finally, just to really make things worse, I gave them the worst possible prompt:
“my zig code is quite old and certainly incompatible with the newest zig 0.15.x (that I am currently using). I need you to think hard and research the web for documentation, migration guides and example snippets to update my code. You must run it against
zig buildand fix each new error until the build ends successfully. I don’t want you to litter my project with temporary files, mockups, do the changes in-place without breaking its behavior: avoid commenting my code out just to make it compile. more than compiling successfully, the program should keep doing what it was meant to do. The project also builds against llama.cpp, present at./vendor/llama.cpp. Be particularly careful about memory management and freeing resources. It’s best to also check header files to know if extern function mapping changed and fix those as well. the qwen_cli.zig is also massive, it would be good to at least refactor into more manageable files. can you do it?”
Never write prompts like this:
- lots of different tasks in the same prompt - prefer small and well-isolated tasks
- lots of changes that can affect the whole file or other files
- asking to refactor along with fixing bugs
- poorly explained, vague
Last year none of them managed it. Let’s see now.
OpenCode and Crush
This section is short. I already posted about Crush a few days ago. Some people asked about OpenCode. Honestly, both seem to do practically the same thing. Even the interface is similar. Of course, internally they must have different heuristics. I tested OpenCode very little but I think Crush is much prettier. That alone is why I use it more. Take a look:
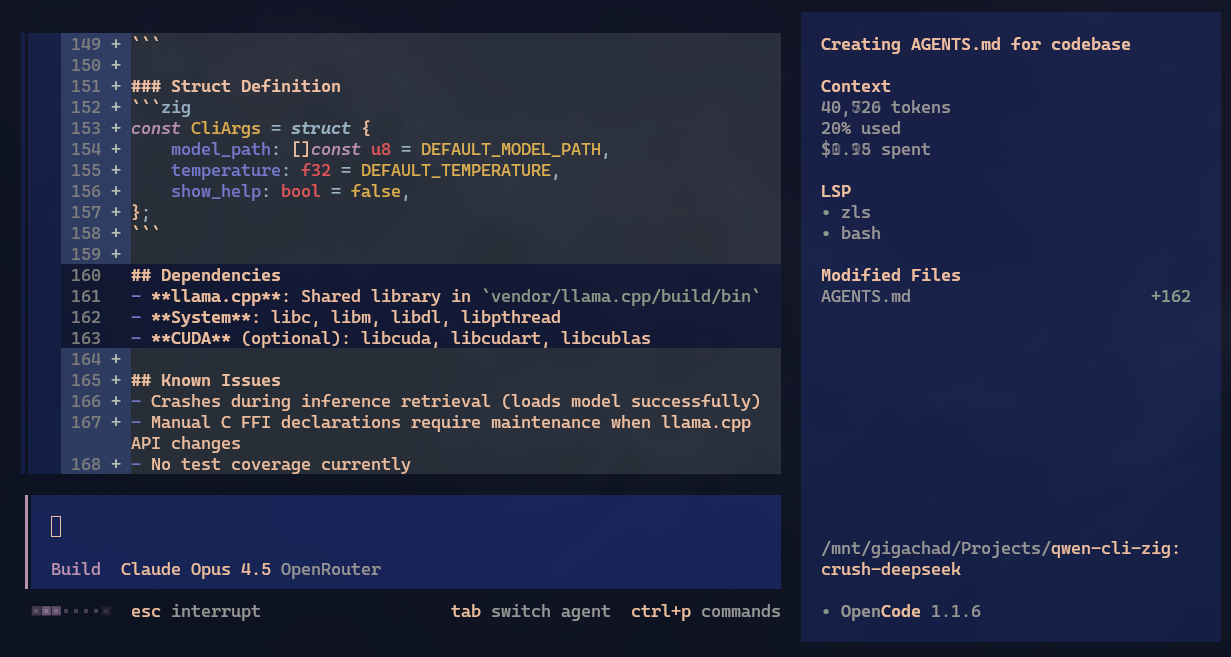
Visual is subjective, pick whichever you think is better. One thing I saw OpenCode do automatically is load LSPs. In Crush I think you need to edit the crush.json file manually, but I may have missed something in the docs. Correct me if I’m wrong.
Both are equally competent at orchestrating the work. The result really is much better than me opening a ChatGPT tab and copy-pasting code manually. Last year that wasn’t so much the case, but now in early 2026, I have to say yes: they’re competent as coding assistants.
Open source LLMs
Let me start with the open source options: unfortunately I was quite disappointed. I can’t test every option out there but I expected more. Though I’m not being fair: commercial LLMs run on their own infra and therefore have capacity to load much larger models.
Of course smaller models will be qualitatively inferior too. GPT, Claude, Gemini, they’re all on the order of TRILLIONS of parameters. The largest open source ones are in the range of 300 BILLION parameters. There’s really no comparison. For simple tasks it works, but for my challenge, it’s not enough.
To make it worse, today’s top-of-the-line GPU, like my RTX 5090, has a measly 32GB of VRAM. So it’s impossible to load models bigger than around 30 billion parameters, and that’s with heavy quantization.
To run the 300 billion ones you need a Mac Studio with 512GB of shared RAM which won’t come out for less than USD 4000 (in the US). For me, since I won’t use it extensively every day, it’s not worth it.
I could only run Qwen3-Coder:30b or GPT-OSS:20b locally. And even being so small, they are very impressive. Just not powerful enough to solve my Zig challenge.
Even so, they’re already pretty old. I tested Qwen3 a year ago, then GPT-OSS came out, but in 2026 people say the best ones are GLM 4.7 which weighs no less than 400 GB on disk. And there’s MiniMax v2.1, which seems to be in the range of 230 billion parameters.
On the ollama site there’s no way to download these models. They run on the “cloud” option which, from what I understand, runs on ollama’s infra, not on your machine.
I even managed to load some segments of GLM 4.6 Flash and MiniMax 2.1 on my machine. But since it has to keep loading and unloading segments between the GPU and the CPU (RAM and VRAM), it’s extremely slow, around 1 token per second. In practice, it’s unusable. Only with a beefy Mac Studio.
Or by spinning up a virtual machine on a cloud like RunPod. But then I’d pay the same, or even more, than using GPT or Claude. So it’s not worth it.
I tried using both LM Studio and Ollama, but stuck with LM Studio just because it was easier to configure things. Here’s my ~/.config/crush/crush.json:
{
"$schema": "https://charm.land/crush.json",
"default_provider": "openrouter",
"providers": {
"openrouter": {
"api_key": "sk-..."
},
"lmstudio": {
"name": "LM Studio",
"base_url": "http://localhost:1234/v1/",
"type": "openai",
"models": [
{
"name": "gpt-oss-120b",
"id": "gpt-oss:120b",
"context_window": 100000,
"default_max_tokens": -1,
"supports_tools": true
},
{
"name": "gpt-oss-20b",
"id": "gpt-oss:20b",
"context_window": 130000,
"default_max_tokens": -1,
"supports_tools": true
},
{
"name": "deepseek-coder-v2-lite-instruct",
"id": "deepseek-coder-v2-lite-instruct",
"context_window": 64000,
"default_max_tokens": -1,
"supports_tools": true
},
{
"id": "qwen/qwen3-coder-30b",
"name": "qwen3-coder-30b",
"context_window": 120000,
"default_max_tokens": -1,
"supports_tools": true
}
]
}
}
}And in LM Studio I would configure things like context window (kept increasing it until it couldn’t load anymore for lack of memory). My parameters looked similar to these:
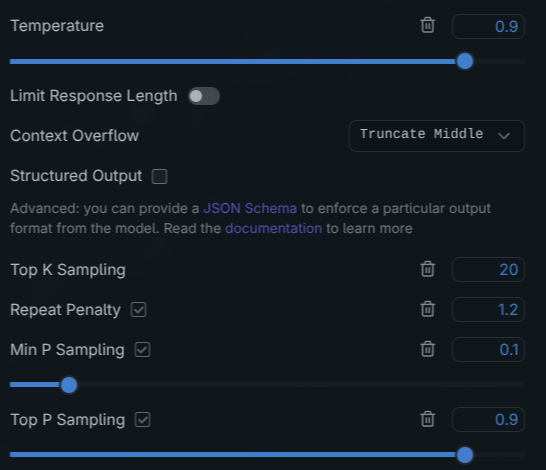
I really tried to give every chance to the open source LLMs. When you download and load with defaults, it comes very conservative.
For example, in the case of Qwen3-Coder, which is the one I insisted most on tuning. It keeps trying to fix things, really tries hard, manages to start the build, manages to get past ArrayList, manages to remap the Llama.cpp externs but the code still has compilation problems.
Eventually it stops editing the code and starts just saying things like “Ah, now I know what the error is, I’ll fix it (… doesn’t do anything to the files …) … done, finished the task, it’s already compiling” and it doesn’t even try to run zig build anymore, just insists it’s already done and doesn’t do anything else.
This may be what they call Agentic Loop or Repetitive Reasoning. First, many times the model is trained to give you a positive answer, and often ignores that it can’t and keeps repeating that everything is fine.
In these scenarios, the model can enter a semantic recursion: it recognizes the problem, even generates a plan to fix it, but because of “sampling” or because the context window got too confused, it repeats the same thinking/reasoning text it already said before (and is in the context) and thinks it’s getting there.
Commercial models seem much better trained and tuned to avoid this, but the open source ones, with few parameters and little post-alignment, don’t have this well tuned, so we can try tuning by hand to see if it helps.
I explained this last year in the article Dissecting an Ollama Modelfile. But remember the process: for each new round to generate the next token it will calculate and find several candidates, each with a certain probability.
If the temperature is zero, it will always respond the same thing. It becomes practically deterministic. If the answer is wrong, it will always return the same error and never get out of it. That’s why you never use temperature near zero.
The closer to 1.0, the more random it gets. That’s when the so-called “creativity” increases, and at the same time the chances of so-called “hallucination” also increase. There’s a very thin line between being creative and just being plain crazy. There’s no fixed number, you have to keep testing.
Besides that we have things like Top K, Top P, Min P, Repetitive Penalty, Presence Penalty. I explained this in the Ollama article but in short:
Normally, Min-P tends to be more effective than Top-P for preventing agentic loops on Qwen. When the “next token candidates” come back, now you need “sampling” (literally a draw). In a loop the “wrong” tokens usually come with high probabilities (e.g. 0.9) and so Top-P will always include them. To balance this there’s Min-P between 0.05 and 0.1. This cuts out tokens that are significantly more probable than the “top” tokens, but more importantly, dynamically adjusts “creativity” based on the model’s confidence. This “shakes” the model out of the repeat penalty trap.
It’s complicated, I get confused too, but look at it this way. Min-P will discard tokens that are smaller than 0.05 among the highest-probability tokens. The trap: when Qwen starts looping, it’s usually more than 98% confident in an answer like “I managed to solve the problem”. Result: at 0.05, Min-P will throw away practically any other alternative because they aren’t even 5% as probable as the loop answer.
To improve this you have to raise Min-P to near 0.1 and raise the Repeat Penalty to something between 1.1 and 1.2 (yes, it’s that tight). More than that and it will start giving absurd and broken answers.
Anyway, all this was to say how I kept adjusting 0.1 up, 0.1 down.
And that’s for Qwen3. GPT-OSS is different. It seems it was trained to manage its own probability space, so the parameters I mentioned act differently. For example, OpenAI recommends setting temperature very high, close to 1.0, and leaving Top-K at zero and letting the model handle it. As I said, there are no fixed numbers you apply to everything.
But even tweaking the most I could, I couldn’t get either Qwen3 or GPT-OSS to solve the challenge. It was 2 full days trying and nothing.
GLM 4.7 and MiniMax M2.1 and DeepSeek R1
I’ve heard about these two but I already knew they wouldn’t run on my machine. So no tuning either. I was forced to run them via OpenRouter.
The biggest difference is that I found both GLM and MiniMax quite slow. Not so much in terms of tokens per second, but in the reasoning/thinking process itself. I noticed they fill the context with who knows what, very fast, and take a very long time to reach an answer.
Like all the others, they managed to get the build working, solved the ArrayList problem, started trying to solve the Llama.cpp externs.
GLM had some issue with Crush. It got to a certain point where it couldn’t call the API anymore and froze. And it was already taking very long, so I gave up on it. And when I say taking very long, I’m really talking about more than an hour without managing to solve it.
MiniMax also had a super verbose reasoning process, took more than an hour too, but finally managed to compile. Except when running it crashed.
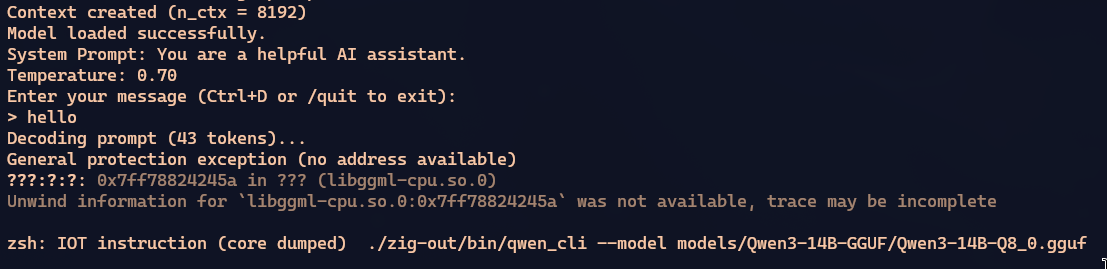
I insisted several times for it to fix this error, but it took too long and I gave up trying.
DeepSeek I tried to run V2 Lite via LM Studio, but couldn’t integrate it with Crush. Many LLMs have “capabilities” and one that matters for agents is “tool”, which is the ability to make calls to commands and tools like grep, bash, etc. for Crush to run on the machine and get real feedback.
But in DeepSeek’s case, whether running locally or connecting via OpenRouter, I quickly see this in Crush:
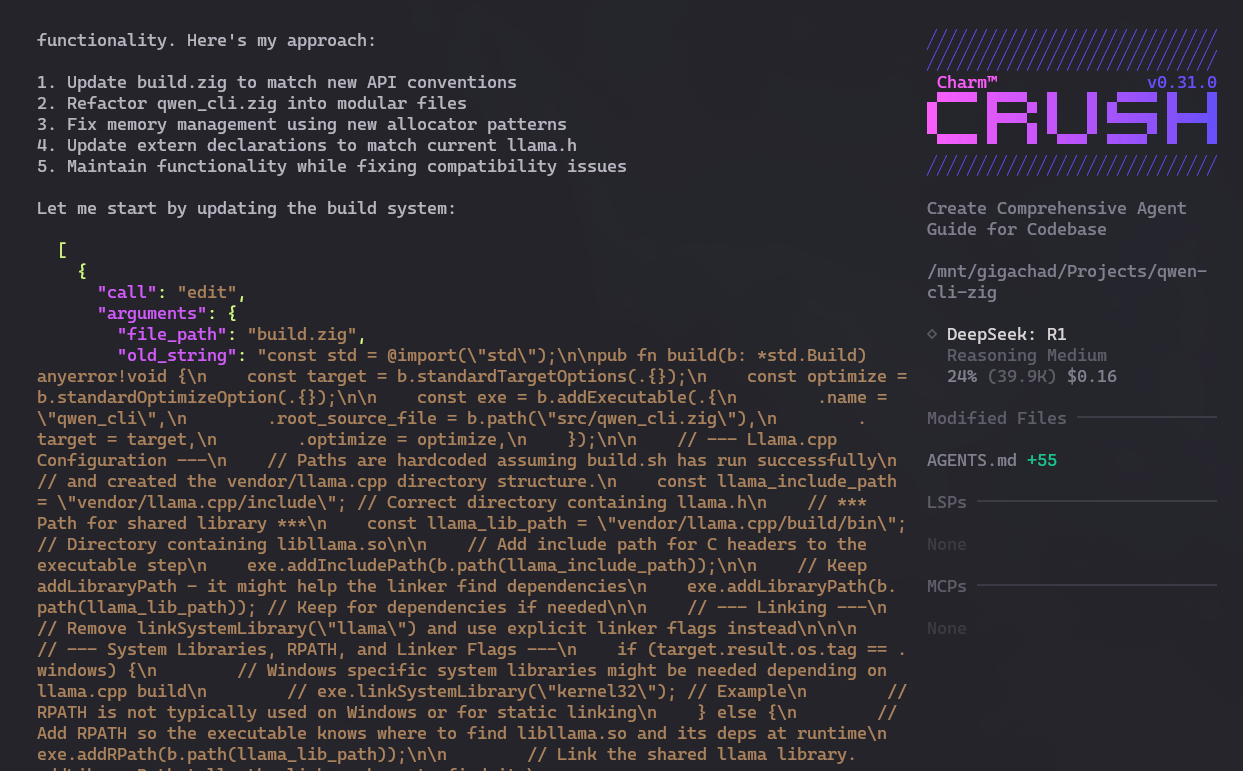
The attempt to run commands appears but I think that’s not the same format as OpenAI’s, which is what everyone understands. So Crush doesn’t know what to do with it and breaks the process. I didn’t try to dig much more than that.
Commercial LLMs
No open source model managed to get my program running. But at least all the commercial ones did, and that shows excellent evolution from a year ago.
As I said before, the best overall was Claude Opus. In all the experiments I gave that prompt I mentioned at the start of the article. But none managed to solve it all the way through. Either the build kept failing or, even when it built, there were runtime errors and crashes.
What’s impressive about Claude Opus is that it was the only one that solved everything in just TWO PROMPTS!!!
With that first sloppy prompt I mentioned, it solved the compatibility bugs with Zig 0.15, with Llama.cpp, refactored into multiple files and the build generated the binary. And that in about half an hour. Compared to all the others that took more than an hour.
Then I tried running the binary, but it crashed right at the start when trying to load the Qwen3 model. I did the second prompt and on its own it executed inside Crush, identified the crash, and managed to fix the bug. Then I could get all the way to the chat and talk to the model. It was so fast, I couldn’t believe it!
I’m not saying it will be perfect for everything, but considering everything I said so far, it was practically instantaneous to get the final result.
Then I tried GPT 5 Codex - which came in close 2nd place.
It was slightly slower than Opus but also reached a state where it almost compiled. I had to insist there was still an error in the build, then it ran again and fixed it. And in this case, it had a different error. After compiled I ran it and it loaded the model and went to chat normally. But when I gave the “/quit” command the program crashed on exit. It had a memory leak problem.
I had to insist with 2 or 3 more prompts, but in the end it was able to find the leaks and fix them. And now the binary works just like Opus’s.
Finally, I tried Gemini 3 Pro Preview. Last year the best commercial LLM for code was Gemini 2.5, so I had great expectations. But it disappointed me a bit. It was by far the slowest and most expensive.
I didn’t even talk about prices, but Opus solved everything for about USD 8. GPT 5 Codex spent around USD 6, it was cheaper, but took longer and needed more interaction. Gemini 3 Pro spent almost USD 14 and barely managed to solve it!
Gemini was weird. Like MiniMax, its reasoning was much slower than the others. I was starting to get worried because it seemed like someone with ADHD. Instead of going step by step, it gave the impression it was messing with more than it needed in various unrelated parts. It did refactoring before fixing bugs, kept trying to rewrite things instead of fixing. At some moments I thought it would give up.
After taking longer than Opus or Codex, it simply gave up!! It dropped a “I managed to fix everything”, but I tried to build and it broke. I thought it was going to fall into the same agentic loop problem as Qwen3. I insisted saying it was still broken and at least it ran the build and started fixing what was missing.
Like Codex, it managed to finish the build, but then there was a runtime crash too. It took a little while to fix but in the end it did. But it was by far the one that gave me the least confidence in the process.
To compare what they did, I left the Pull Requests open on the project. See for yourselves:
- Opus’s PR - the best
- GPT 5 Codex’s PR - came close
- GPT 5.2’s PR - took longer but solved it well
- Gemini’s PR - got scary, but it made it
I heard GPT 5.2 Codex is the best, but it wasn’t on OpenRouter to test, so I tested GPT 5.2. It wasn’t tuned for coding like Codex, but it did better than Gemini 3, in my opinion. It had slower reasoning than 5.1 Codex, and also needed some insistence at the end to finish, but gave less suspense than Gemini.
At least for this kind of challenge, Opus was the winner by a long shot! It seems more expensive per token, but does less reasoning and wastes less context, so in the end prices are comparable. Gemini was by far the most expensive and least reliable, among the commercial ones.
Is the Programmer Career Over?
Yes, AI agents - particularly connected with Claude and GPT, have dramatically improved compared to a year ago. Combined with orchestration tools like Crush or OpenCode, they’re really very good to use. I can see myself using them day-to-day as a good coding assistant.
Yes, they “replace juniors” as people like to say. Let me explain.
Since I started my YouTube channel in 2018 I’d been warning that the Programming Bubble was going to burst. That insane demand for bad programmers had no future. That rampant thing of bootcamps and crappy online courses churning out mediocre programmers had no way of working out. That bubble burst at the end of 2022.
And just to nail the coffin shut, at the same time the first GPT appeared. Four years later, we’re still nowhere near the elusive “AGI”. But what we have today is already very useful.
It’s very simple: a programmer really has to be good in 2026, to have a good career. Everything I said on my channel - which ended in 2023, before AIs -, still holds. Only a good programmer can take advantage of these AIs.
Did you see how Tailwind lost 80% of its revenue because of AI? Everything that has to do with “fast” “dev” training imploded. The shallow promises weren’t fulfilled, as I warned.
For me it’s excellent: I KNOW EXACTLY WHAT I WANT and with that I can ask the AI and I can check if it’s correct. Someone without real programming training can’t. The AIs still have the same stochastic token-drawing process with built-in randomness. It’s a stochastic and non-deterministic process.
So a total amateur still won’t be able to do anything very complicated. You don’t know what you don’t know.
For us seniors, many tedious and grunt-work tasks - that we’d previously hand off to interns or juniors - really can be handled by AI agents, whether with Cursor, Antigravity, OpenCode or any other.
If you want to have a real career, the requirements have changed, and increased by an order of magnitude. Going to a real, good college is no longer optional. Really learning how things work under the hood. So you can know what to ask the AIs and get decent results.
As I’ve always said, for me, these tools are super useful and now they’ve gotten even better. Your competition has increased exponentially. Prepare for real.
AIs as facilitators
So as not to end negative, there are several uses for these AI tools. Particularly to help with onboarding to new projects.
Let me give a really silly example. I really like emulators, I’m always keeping up with them. Particularly the Xenia Canary project which is the experimental in-development version of the Xbox 360 emulator.
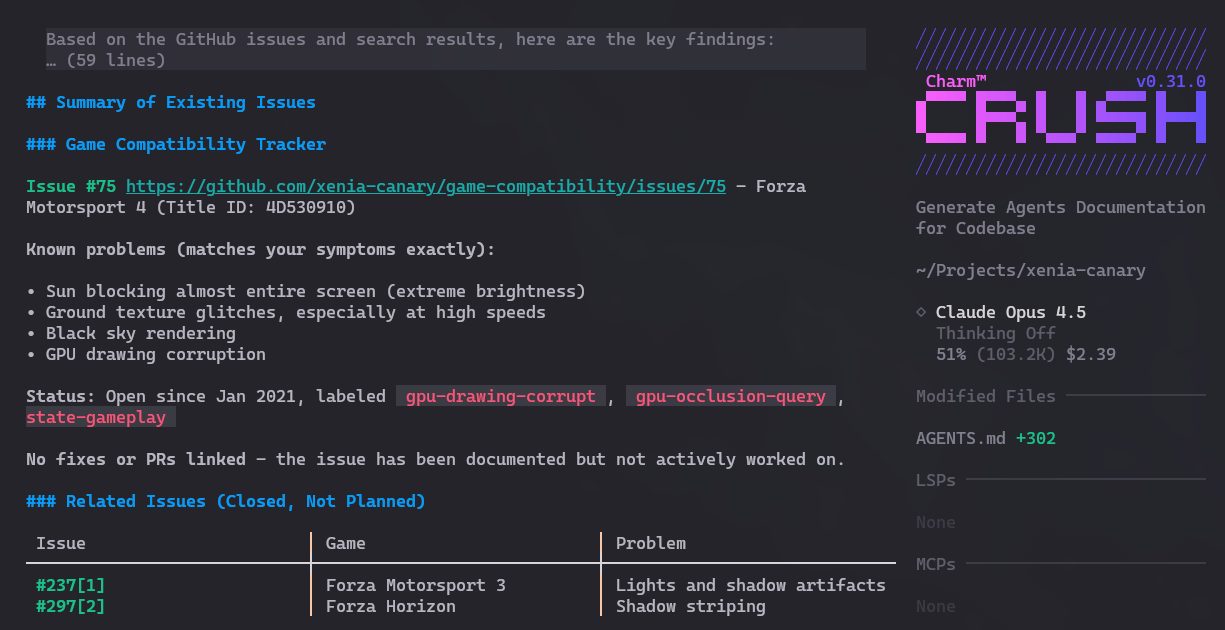
I don’t know anything about advanced emulators like this. And it’s quite hard to get into this code without knowing anything. But with Crush and Opus, right off the bat it gives me a project summary. See this Gist it generated in 5 minutes.
After getting it to build and run tests - with Crush’s help, I asked the following question:
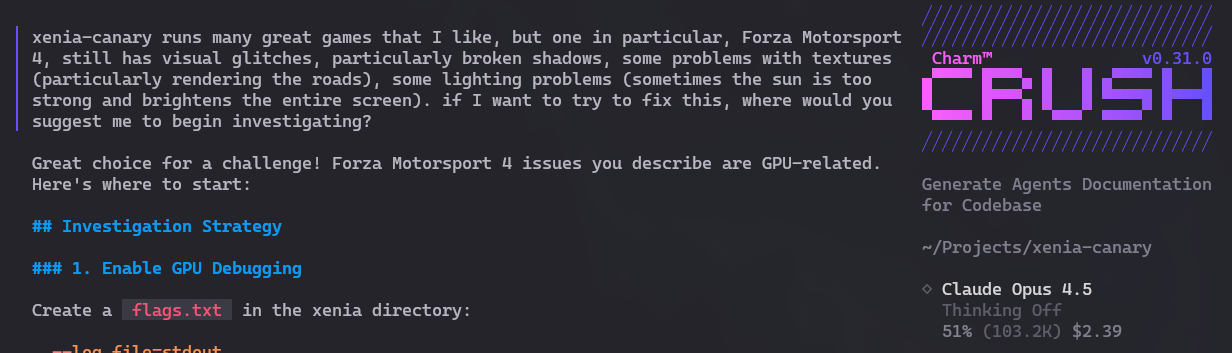
I like Forza Motorsport 4 but it still has several glitches and bugs in the emulator. I asked Crush to tell me, if I wanted to explore fixing these bugs, where I could look first. And it analyzed and gave several good suggestions:
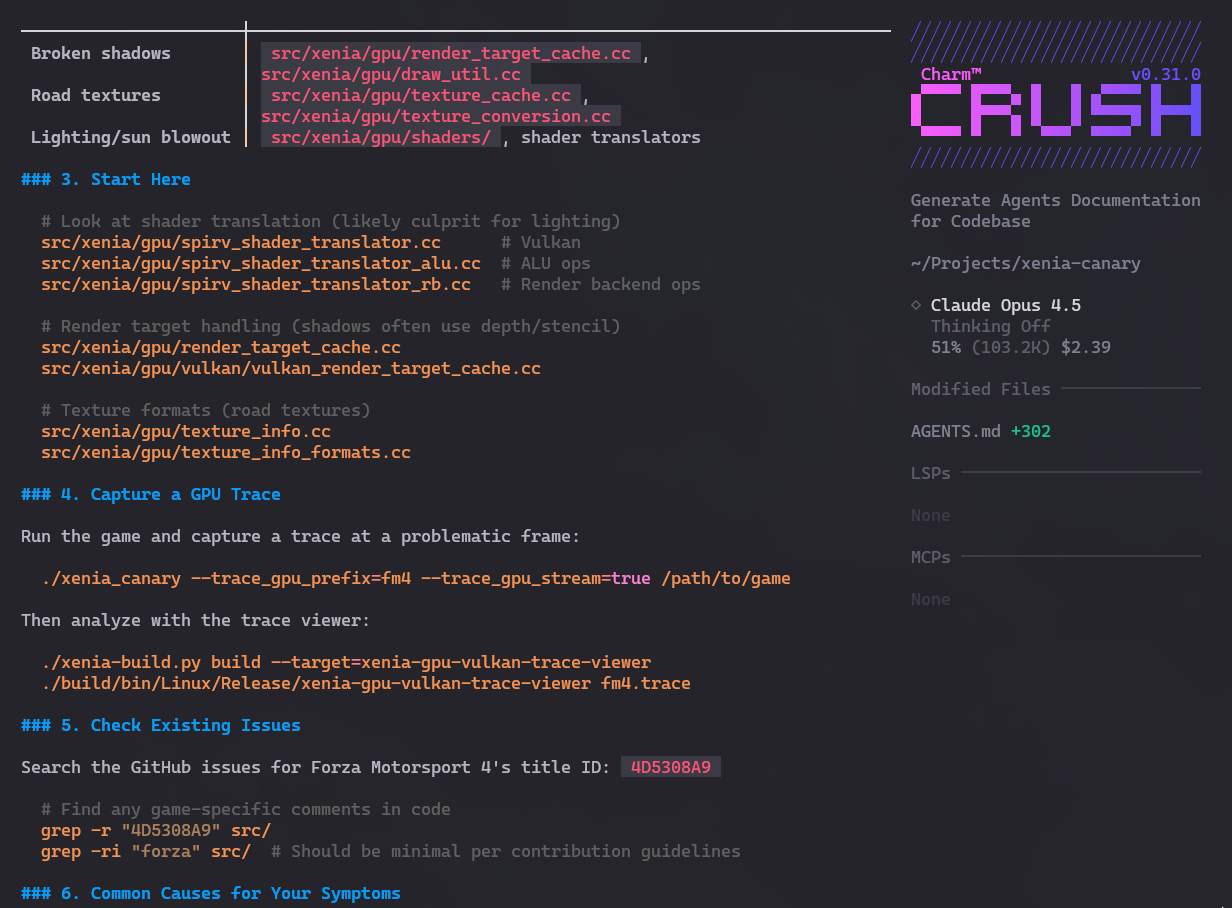
Then I asked it to check the Issues on GitHub and apparently nobody is working on these specific bugs. So they’re great candidates for me or someone else to try to contribute.
Honestly, I don’t know yet if I’ll go down this rabbit hole. But thanks to Crush, evaluating existing projects and making it easier to find candidates to look at first lowers the barrier to entry a lot! This isn’t about contributing “AI Slop”! But the possibilities are many for someone like me. Think about it.