Dicas e Toolkit de IA do Akita: ai-jail, ai-memory, ai-usagebar
No post da semana passada, “Terminando a Maratona de IA: Sucesso ou Fracasso?”, eu encerrei a primeira fase da minha maratona. Mais de 600 horas de uso intenso de agentes de código, dezenas de projetos, centenas de milhares de linhas de código e documentação, e uma pilha de conclusões práticas. Não de marketing. Práticas.
Vou repetir uma coisa importante antes que alguém saia clonando todos os meus repositórios achando que virou produto 1.0: a maior parte dos projetos frank-* no meu GitHub são provas de conceito. São experimentos. Alguns funcionam bem pra mim, no meu ambiente, no meu fluxo. Isso não quer dizer que estão prontos pra virar dependência crítica da sua empresa amanhã de manhã. Quer brincar, contribuir, estudar, ótimo. Só não confunda “publiquei no GitHub” com “está production ready”.
Existem exceções. O FrankMD, por exemplo, recebeu uma quantidade decente de contribuições, testes, lapidação, correções de bugs reais, uso real. Hoje ele já é bem mais estável do que era no primeiro post. Ainda assim, o ponto continua: esses projetos nasceram como laboratório de vibe coding, não como plano de produto de 3 anos com roadmap, suporte enterprise e SLA.
Este post é um apanhado do que aprendi nesse laboratório. Algumas ferramentas minhas, alguns hábitos, algumas recomendações. Nada místico. Nenhuma “nova forma revolucionária de programar”. É engenharia velha com ferramenta nova.
Primeiro: pare de colecionar agente
Se você é desenvolvedor normal, você não precisa de 12 agentes, 40 wrappers, 7 orquestradores e um diagrama de Kubernetes pra escolher quem vai escrever um if.
Na prática, foque em Claude Code, Codex ou opencode. Só isso.
Sim, existe Gemini CLI. Sim, existe Cursor. Sim, existe Windsurf, Crush, OpenClaw, Pi, Aider, e amanhã vai aparecer mais meia dúzia. Eu testei um monte. Leia meus posts de benchmark de LLMs, especialmente o “LLM Benchmarks Parte 3: DeepSeek, Kimi, MiMo”. A conclusão é chata e óbvia: hoje, as melhores opções de custo-benefício pra programação pesada são Opus 4.7 e GPT 5.5 nos planos Pro/Plus/Max subsidiados. Nada chega perto quando o assunto é trabalhar várias horas por dia com agente de código de verdade.
Pagar token direto é caro. Pagar plano mensal subsidiado sai muito mais barato. É por isso que eu vivo alternando entre Claude Code e Codex: não porque eu quero “multi-agent architecture”, mas porque os planos têm limites e eu trabalho muitas horas seguidas.
DeepSeek v4 e Kimi 2.6 são mais baratos? Sim. São usáveis? Sim. Eu gosto deles pra vários casos. Mas pra Agile Vibe Coding do jeito que venho defendendo desde o post “Do Zero à Pós-Produção em 1 Semana”, ainda falta. Eles tropeçam mais em continuidade, em refatoração longa, em testes, em entender o projeto inteiro. Dá pra usar? Dá. Mas se o objetivo é produtividade consistente, Opus e GPT ainda são a régua.
Rodar modelo open source local é legal. Eu mesmo brinquei bastante com isso no review do Minisforum MS-S1 Max com AMD AI Max+ 395. Pra one-shot, pra estudar, pra brincar com inferência local, é divertido. Pra Agile Vibe Coding o dia inteiro, todo dia, ainda não é prático. Latência, contexto, qualidade, manutenção do setup, VRAM, tudo cobra imposto.
Também não é prático ficar rodando múltiplos LLMs em paralelo, tipo “planner + executor + reviewer + juiz”. Eu testei isso no post “LLM Benchmarks: Vale a Pena Misturar 2 Modelos?”. A ideia é bonita no papel. Na prática, aumenta custo, aumenta latência, aumenta superfície de erro, e o ganho não paga a complexidade.
O segredo não é ter um monte de agentes. Esquece OpenClaw ou Pi pra programação do dia a dia. O segredo é processo de engenharia. XP. Testes. Clean Code pra agentes de IA. CI. Pair programming. Refatoração constante. Código pequeno. Deploy automatizado. Feedback rápido.
Ferramenta ajuda. Engenharia ganha.
ai-jail: autonomia com cerca
O primeiro projeto que quero destacar é o ai-jail. Ele é um wrapper de sandbox pra rodar agentes de IA com acesso restrito ao sistema. No Linux usa bubblewrap (bwrap) e Landlock. No macOS usa sandbox-exec. A ideia é simples: o agente enxerga o ambiente que precisa pra trabalhar, mas não sai fuçando seu sistema inteiro.
Uso todo dia? Sim. Uso sempre? Não.
Quando sei que não vou fazer nada arriscado, abro claude ou codex direto. Se vou mexer num projeto simples, só rodar testes, editar markdown, refatorar coisa local, muitas vezes nem me preocupo. Em mais de 600 horas de Agile Vibe Coding intenso, mais de meio milhão de linhas de código e documentação, nunca tive um caso desses folclóricos de LLM destruindo meu sistema host de um jeito irrecuperável.
E olha que eu usei agentes explicitamente pra configurar meu Omarchy. ZSH, Hyprland, Waybar, configs de terminal, scripts de login, tudo. Nunca fizeram nada que eu não pedi.
Essas histórias de “o agente deletou meu home inteiro sozinho” eu leio com um pé atrás. Na minha experiência, quando você pede pra deletar algo perigoso, Claude e Codex perguntam confirmação. Você precisa dizer sim. Se você disse sim sem ler, a culpa não é mágica negra do LLM. É usuário no modo zumbi.
Dito isso: nada é garantido. Daí o ai-jail.
Meu uso preferido é combinar ai-jail com o modo sem freio do harness:
ai-jail claude --dangerously-allow-permissions
ai-jail codex --dangerously-bypass-approvals-and-sandboxParece contraditório, mas faz sentido. Eu tiro a fricção de confirmação dentro do agente, mas coloco uma cerca no nível do sistema operacional. O agente pode trabalhar rápido dentro do projeto, mas o filesystem do host fica essencialmente read-only. O diretório atual fica read-write. O que eu mapear explicitamente com --rw-map também fica read-write. O resto não é pra tocar.
O README do ai-jail resume bem: é um sandbox wrapper pra agentes como Claude Code, GPT Codex, OpenCode e Crush. No primeiro run ele cria um .ai-jail no projeto, que pode ser commitado. Suporta --dry-run pra ver os mounts antes de executar, --lockdown pra modo mais restritivo, --private-home pra esconder dotfiles reais, --mask .env pra esconder arquivos sensíveis dentro do próprio projeto, e perfis de navegador isolado pra Chromium/Firefox.
O ponto importante: não venda isso como segurança absoluta. Processo sandbox não é VM. Kernel bug existe. Side channel existe. macOS tem limitações. O próprio README é claro: se você precisa isolar workload hostil de verdade, use uma VM descartável. Eu não uso ai-jail como “blindagem militar”. Uso como mais uma camada, boa o suficiente pro fluxo de desenvolvimento.
E mesmo dentro do projeto, tudo é Git. Eu faço push frequente pro GitHub ou pro meu Gitea privado. Então o pior caso realista é o agente destruir o diretório do projeto. Chato? Sim. Catastrófico? Não. Clono de novo. Volto do remote. Refaço o que estava local. Se o .git corromper, apago tudo e clono de novo.
Secrets também têm cópia fora. .env, tokens, keys, tudo que importa fica no Bitwarden. Self-hosted em Vaultwarden, claro. Então se eu perder o diretório local, não perdi a chave do reino.
O risco mais comum não é o agente deletar tudo. É você vazar segredo no Git. Isso aconteceu comigo mais de uma vez. Você dá git add ., esquece um .env, empurra pro remote, parabéns. Acontece. Por isso tem que olhar git status, git diff --cached, e pensar antes de dar push.
Mesmo quando acontece, os LLMs são muito competentes pra ajudar a reescrever histórico. Peço pra limpar o segredo do Git, forçar push, revisar se sumiu, e depois eu rotaciono a key. Não é bonito, mas é administrável.
Então sim, recomendo usar Claude/Codex com permissões perigosas dentro do ai-jail. Existe a chance de 0,001% de acidente irrecuperável? Existe. Mas se você é bom engenheiro, isso não deveria te matar. Eu tenho camadas: snapshots automáticos em Btrfs, restic pro NAS, NAS arquivando offsite em AWS Glacier, Git remoto, Bitwarden. Ferramenta nenhuma substitui backup.
ai-memory: contexto que sobrevive ao harness
O segundo é o ai-memory, que expliquei em detalhes no post “Criei um Sistema de Memória pra Agentes de Código: ai-memory”.
![]()
A motivação é simples: harnesses perdem contexto. Claude Code compacta. Codex compacta. opencode compacta. Sessão acaba. Você abre outro agente e ele não sabe o que aconteceu nas últimas 4 horas. Se você usa só um harness, talvez isso não incomode tanto. Se você alterna entre Claude e Codex como eu, incomoda rápido.
Eu queria um consolidador de memória de longo prazo que funcionasse atravessando harnesses diferentes. Algo que permitisse handoff entre Claude, Codex e opencode sem eu ficar escrevendo HANDOFF.md manual toda vez. Algo que capturasse prompts, tool calls e eventos de sessão via hooks, consolidasse em páginas markdown, indexasse com SQLite/FTS5, e expusesse tudo via MCP quando o agente precisasse consultar.
Outro motivador foi o que expliquei no post “RAG Está Morto? Contexto Longo, Grep e o Fim do Vector DB Obrigatório”. Pra projeto de código, quase sempre texto simples resolve mais do que arquitetura afetada de vector DB. Markdown, grep, SQLite FTS5, contexto longo e bons arquivos em docs/ já levam você longe. O ai-memory segue essa linha: compila memória em texto, deixa no disco, indexa simples, e só chama LLM quando vale consolidar.
O ai-memory não foi feito pra ser uma knowledge base navegável por usuário final. Ele tem uma UI web read-only, sim, mas isso é pra auditoria e inspeção. A memória é otimizada pra LLM consumir. É um wiki interno que o harness pode consultar quando acha que precisa. É um lugar onde posso pedir explicitamente “salva isso pra próxima sessão” e esperar que sobreviva mais do que a compactação padrão do Claude ou do Codex.
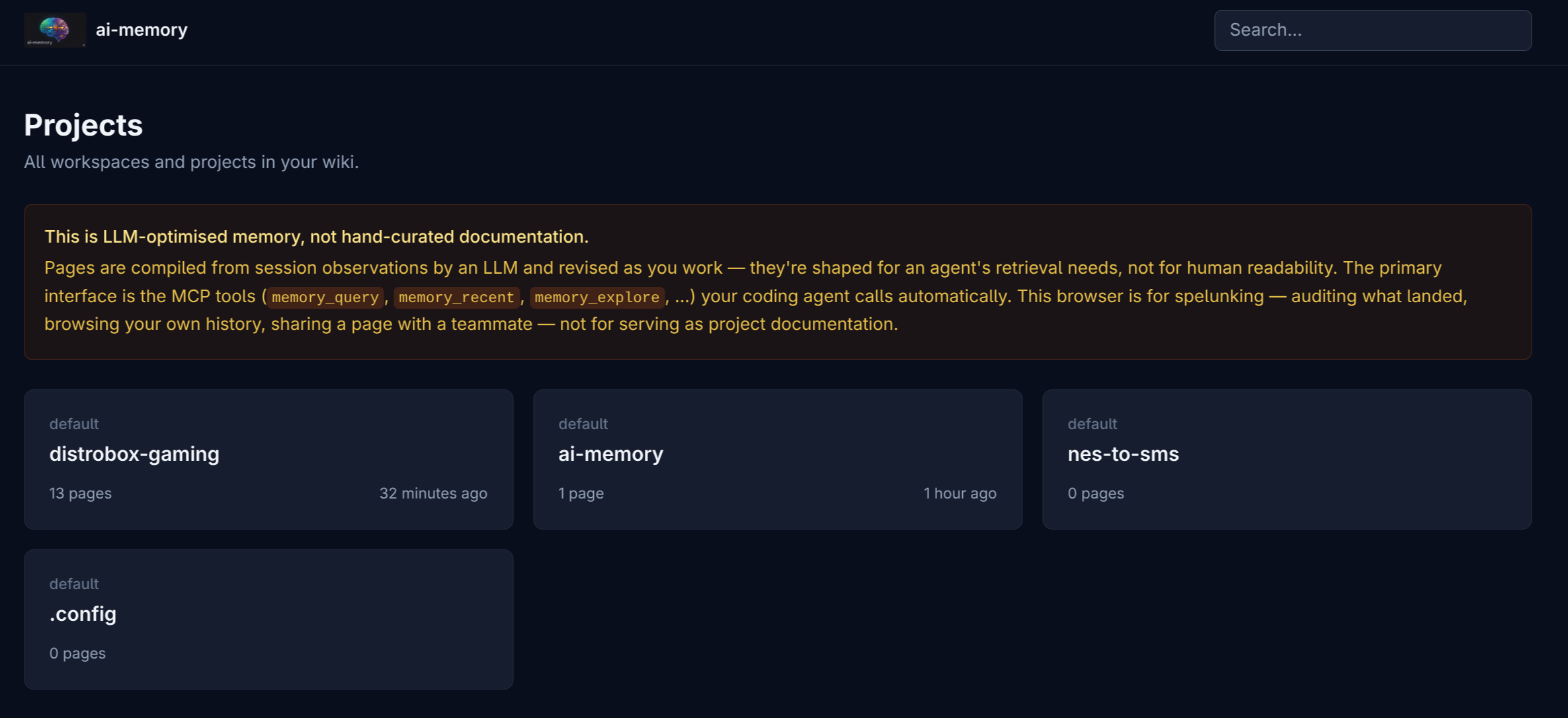
O README resume bem: agentes de código perdem todo contexto quando a sessão termina; o ai-memory dá a eles um wiki persistente compartilhado. Cada prompt, tool call e decisão pode ser capturado automaticamente. No fim da sessão, páginas relevantes são reescritas como narrativa coerente. Na próxima sessão, outro agente pode receber um handoff já prepended no contexto.
Isso é útil quando você fecha Claude às 18h, abre Codex no dia seguinte no mesmo diretório, e quer que ele saiba que você estava testando session cookies porque rotação de JWT tinha dado problema. Ou quando você volta a um projeto seis semanas depois e não lembra por que descartou Redis.
Mas não confunda com documentação canônica. Se você fez uma pesquisa importante que não quer perder, peça pro agente escrever um markdown em docs/ dentro do projeto. Decisão arquitetural, benchmark, análise de biblioteca, runbook de deploy, tudo que precisa sobreviver com garantia deve virar arquivo explícito no repo. Isso é mais simples, auditável e versionado.
O ai-memory cobre a faixa intermediária: informação transitória que talvez importe depois. Um bug estranho que apareceu. Um raciocínio que levou a uma decisão. Um gotcha de ambiente. Um resumo de sessão. Coisas que você não quer transformar em doc oficial ainda, mas também não quer jogar fora.
Ele ainda é beta. Eu uso em produção pessoal, mas precisa de muito mais gente batendo nele. Tem integração com Claude Code, Codex e opencode mais polida. Gemini CLI, OpenClaw e clientes MCP exóticos ainda precisam de mais teste. PRs são bem-vindos. Bug report também. “Instalei e quebrou no meu setup” é exatamente o tipo de feedback que revela suposição errada.
ai-usagebar: saber quando trocar de cavalo
Como falei acima, eu prefiro usar os planos subsidiados da Anthropic e da OpenAI. O problema é que, se você faz Agile Vibe Coding de verdade, você bate limite. Limite diário. Limite semanal. Limite de sessão. Limite que muda. Limite que não aparece direito em lugar nenhum.
Eu usava o claudebar, que é bom, mas só cobre Claude. Eu queria ver os principais vendors num lugar só. Daí nasceu o ai-usagebar, que apresentei no post “Criei um Widget de Waybar pra Omarchy pra Monitorar Uso de Planos de LLM: ai-usagebar”.
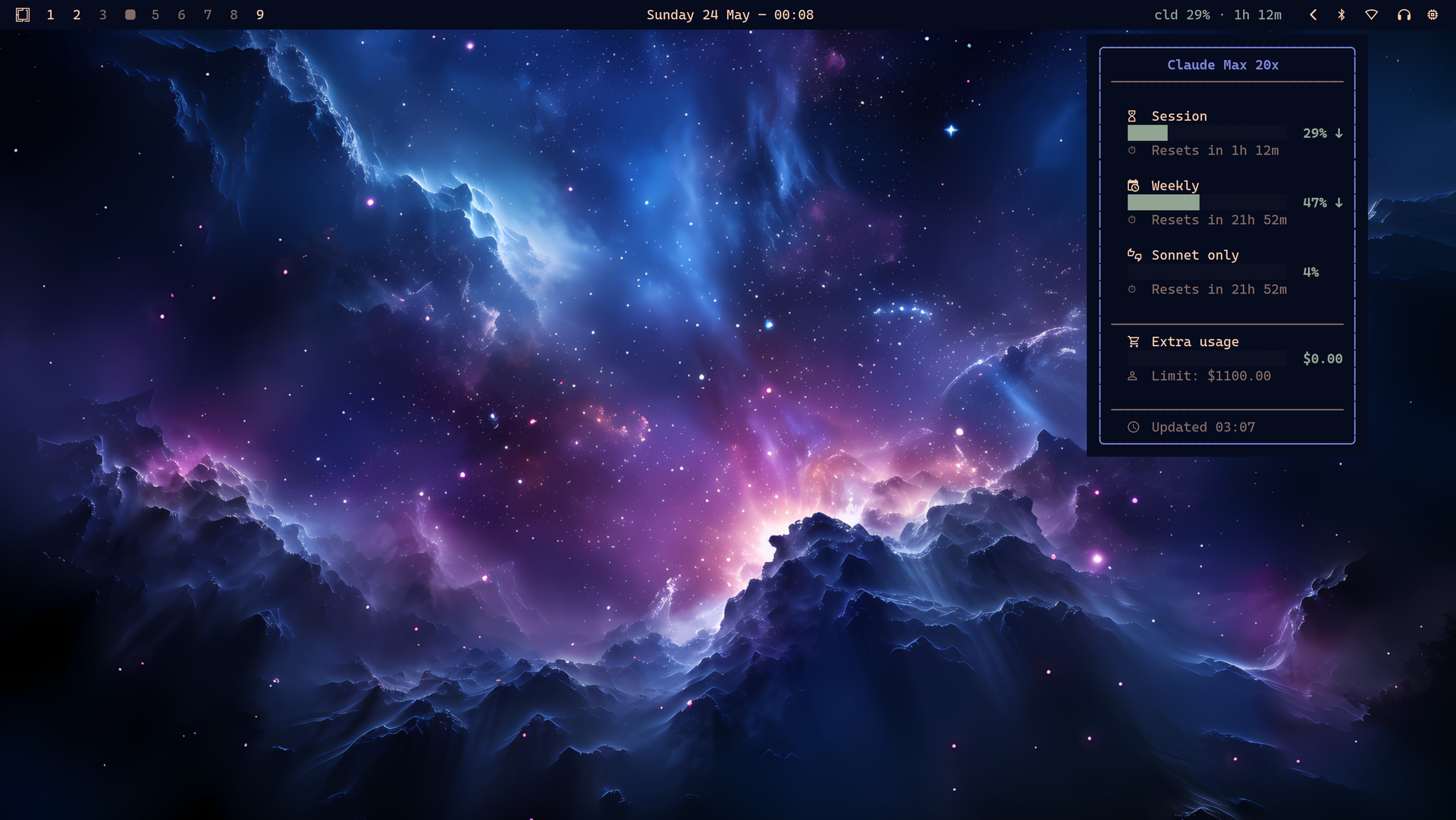
É um widget de Waybar e uma TUI em Rust pra monitorar uso de Anthropic Claude, OpenAI Codex/ChatGPT, Z.AI GLM e OpenRouter. Pra Claude e OpenAI, ele lê as credenciais OAuth que os CLIs oficiais já gravaram. Pra Z.AI e OpenRouter, usa API key. Mostra porcentagem da sessão, reset, limites, saldo, e permite trocar o vendor principal.
O valor disso é banal e por isso mesmo útil: bato o olho na barra e sei se devo continuar no Claude, fazer handoff pro Codex, ou recarregar crédito no OpenRouter. Não quero descobrir que cheguei no limite semanal no meio de uma refatoração grande.
Também tem a TUI standalone:
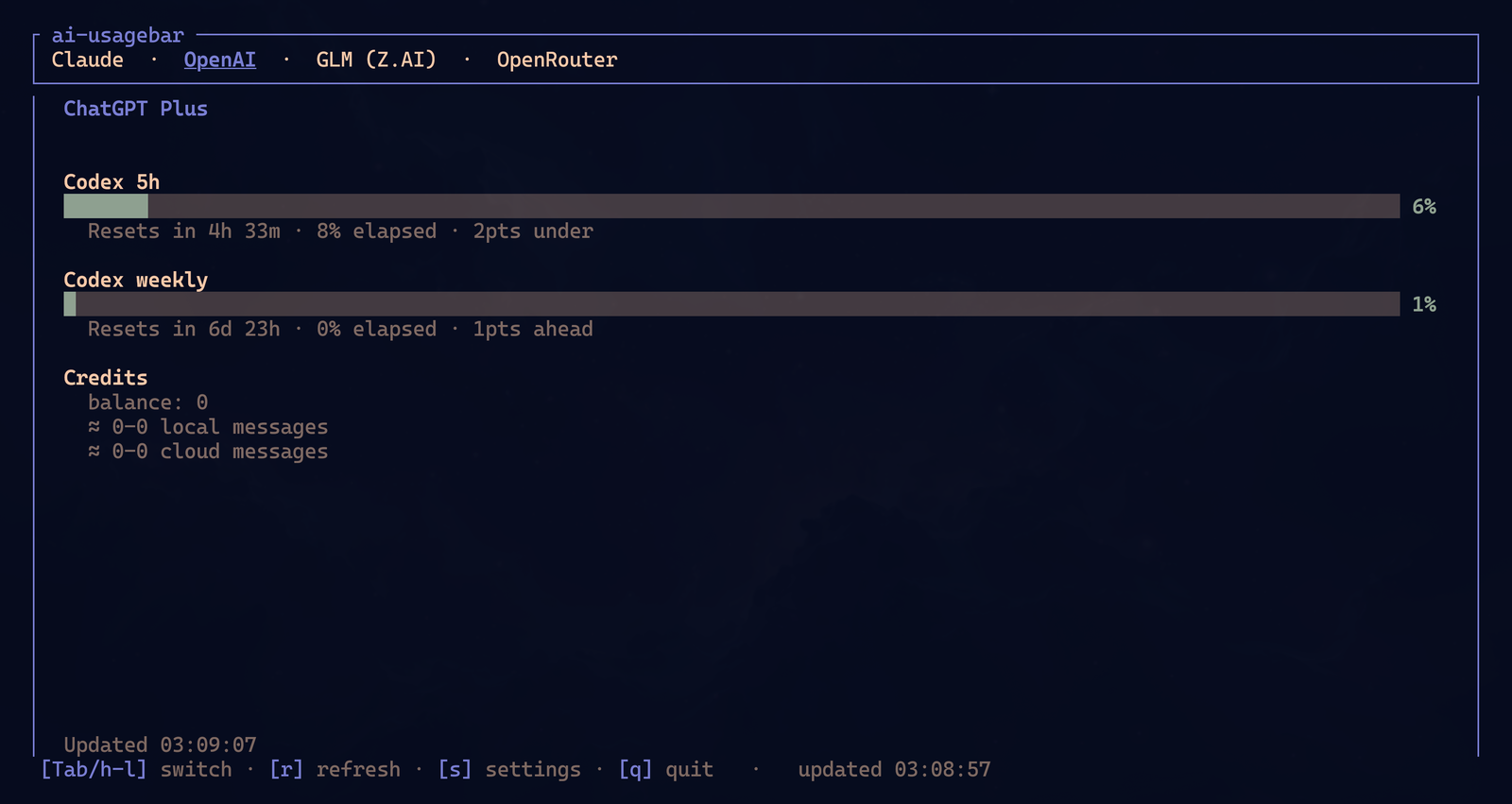
Se você não usa Omarchy, Hyprland ou Waybar, ainda dá pra rodar ai-usagebar-tui em qualquer terminal. SSH, tmux, terminal normal, tanto faz. A barra é conveniência. A TUI é a forma universal.
ghpending: pendência de GitHub sem ritual
Depois da maratona, fiquei com dezenas de ai-* e frank-* no GitHub. Isso cria um problema chato: issues e pull requests começam a aparecer. Contribuidor abre PR. Alguém reporta bug. Outro manda sugestão. Se eu tiver que abrir o navegador, entrar repo por repo, filtrar aba por aba, eu vou adiar. E se eu adiar, fico semanas sem responder.
Sim, eu poderia usar gh, a CLI oficial do GitHub. Aliás, uso. Mas eu queria uma coisa mais burra e mais rápida: um comando curto pra imprimir um digest de tudo que está pendente nos repos que eu escolhi monitorar. Nasceu o ghpending, que descrevi no post “Criei um CLI pra Checar Pendências no Meu GitHub: ghpending”.
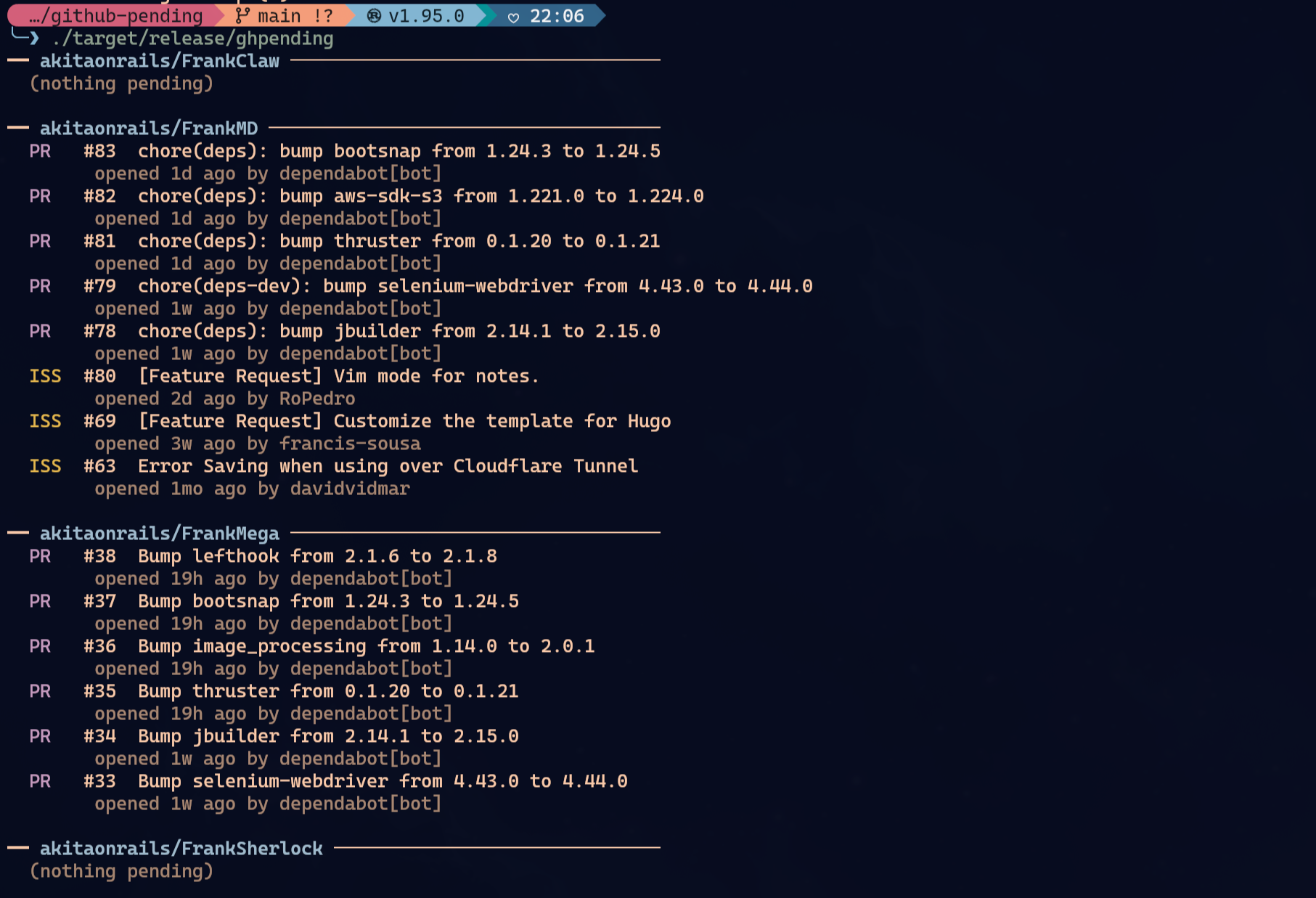
É só isso: ghpending add pra escolher repos, ghpending pra ver o digest, ghpending list, ghpending rm. Sem autenticação funciona com limite de 60 req/h do GitHub. Com GITHUB_TOKEN=$(gh auth token) ghpending, sobe pra 5.000 req/h.
O ponto não é substituir o GitHub. É reduzir atrito. Se eu consigo rodar um comando no terminal e ver “tem 3 PRs e 2 issues pra olhar”, eu olho. Se depende de ritual de navegador, notificações e abas, fica pra depois.
E Claude/Codex são muito bons nesse tipo de trabalho. Dá pra pedir:
“Checa os pull requests abertos, revisa o código, vê se compila, roda os testes, adiciona teste se faltar, faz rebase de master se precisar, mergeia e fecha.”
Ou:
“Checa as issues abertas, avalia se tem bug real, reproduz se der, propõe correção, responde o usuário.”
Eles leem o PR, entendem o diff, rodam teste, fazem rebase, resolvem conflito simples, escrevem resposta pro contribuidor. Não é pra desligar o cérebro. É pra terceirizar o trabalho mecânico que você já sabe fazer.
Refatoração: peça explicitamente, várias vezes
Claude e Codex são muito bons em refatorar, mas não presuma que vão fazer isso automaticamente do jeito que você faria. Eu costumo começar projetos ou features com instruções explícitas:
“Use as melhores práticas de Rust. Evite duplicação desnecessária. Modularize só onde fizer sentido. Adicione unit tests pra toda feature nova. Siga princípios de Clean Code. Não crie abstração antes de precisar.”
Depois de uma feature grande, uma correção grande, ou algumas horas de desenvolvimento, paro e peço:
“Agora que mexemos bastante no código, reavalie com calma. Delete código morto. Refatore duplicações óbvias. Adicione testes faltantes. Remova magic numbers. Veja se tem módulos grandes demais. Não mude comportamento sem teste.”
Antes de release:
“Antes de publicar essa versão, faça uma auditoria de sanidade. Procure vazamento de secrets, permissões perigosas, comandos destrutivos, path traversal, unwraps desnecessários, falta de validação, e qualquer coisa que pareça vulnerabilidade óbvia.”
Isso garante segurança? Claro que não. Nem perto. Mas remove muito erro besta. É mais uma camada. Eu gosto de rodar essa auditoria com Claude e depois com Codex, porque cada um acha coisas diferentes. Mesmo assim, bug passa. Segurança é processo, não ritual mágico.
Experimentos descartáveis: código ficou barato
Antes de escolher biblioteca, framework, arquitetura, modelo ou serviço, eu gosto de criar experiments/.
Exemplo:
“Antes de escolher entre Qwen e DeepSeek, cria um protótipo descartável em
experiments/pra A/B test. Documenta a análise emdocs/com resultado, custo, latência, qualidade e recomendação.”
Isso mudou meu jeito de decidir. Antes, muita decisão de engenharia virava opinião, feeling, fé em benchmark dos outros. Agora código é barato. Peço pro agente fazer duas ou três versões, rodar teste, medir, documentar, jogar fora o que não presta.
Prototipar ficou rápido de verdade. O Frank Karaoke é um bom exemplo: transformar YouTube num app de karaokê era o tipo de ideia que antes eu talvez deixasse numa lista mental por meses, esperando “um fim de semana livre” que nunca chega. Agora dá pra abrir um experiments/, pedir um protótipo tosco, testar o caminho técnico, e decidir se vale virar projeto. Olha meus outros posts de 2026 sobre os projetos frank-* e ai-*: quase todos começaram assim, como código descartável que provou alguma coisa antes de merecer nome.
Mas protótipo barato não significa one-shot. Já escrevi em “Por que as LLMs não te dão o resultado esperado”: prompt bom é conversa iterativa. Você dá contexto, mostra referência, aponta restrição, lê o resultado, corrige direção, manda refazer. Se você joga uma frase vaga e espera produto pronto, o erro é seu.
Também aprendi isso apanhando. No post do Frank Yomik contei meu primeiro fracasso real com vibe coding: quando a direção está errada, insistir no mesmo prompt só cava o buraco. Tem hora que precisa reduzir escopo, isolar o problema, criar teste, trocar estratégia. LLM não transforma plano ruim em engenharia boa.
E tem domínio onde você precisa estudar junto. No post de Driveclub e shadPS4, a IA quase me levou pra todo lado errado porque o problema exigia entender renderização, gamma, shaders, buffers. A ferramenta ajuda a explorar, mas quem decide se a explicação faz sentido ainda é você. Se você não entende o suficiente pra verificar, está só aceitando chute bonito.
Por isso também repito a ideia de “Software Nunca Está Pronto”: deploy não é linha de chegada. O protótipo vira produto quando aguenta bug report, manutenção, refatoração, docs, release, rollback, usuário reclamando. LLM ajuda muito nesse ciclo chato. Mas o ciclo continua existindo.
Se é testável, teste. Se dá pra medir, meça. Se não dá pra medir, pelo menos escreva as premissas. O importante é não escolher só porque “parece melhor”.
Código barato também significa desapego. Faça código pra jogar fora. Faça protótipo feio. Faça benchmark descartável. Peça pro agente documentar o que aprendeu em docs/decision-qwen-vs-deepseek.md, depois apague experiments/ se quiser. O documento fica. O aprendizado fica.
LLMs também são muito bons em documentação. Use isso. Peça pra documentar tudo. Por que escolhemos PostgreSQL em vez de SQLite nesse caso. Por que o deploy usa Docker image multi-stage. Por que o serviço roda atrás de Cloudflare Tunnel. Por que aquele sysctl existe. Mesmo que depois você delete metade, o custo de escrever caiu perto de zero.
Deploy automatizado ou você vai parar de manter
Todo projeto meu que importa tem build automatizado. Muitos rodam no meu homelab, como descrevi em “Migrando meu Home Server com Claude Code”. Quase todo projeto tem um bin/deploy que builda imagem Docker, faz push, rotaciona no servidor, aplica migração se precisar, e valida healthcheck.
Claude e Codex são excelentes em deploy. Eles leem o bin/deploy, entendem Dockerfile, editam GitHub Actions, ajustam release workflow, corrigem assinatura de binário, atualizam Homebrew tap, geram checksum. E sim, eu peço pra Claude/Codex dar SSH no meu homelab e redeployar container Docker. Eles são muito bons nisso. O ai-jail, por exemplo, tem GitHub Actions pra buildar binários assinados pra Linux e macOS.
Se você tem dezenas de projetos, quanto mais automatizado melhor. Eu raramente digito comando administrativo no terminal sozinho. Peço pro LLM fazer, observo, aprovo o que for perigoso, e depois peço:
“Documente o que foi feito e por que foi feito.”
Isso vale pro homelab e pra minha workstation. Meu Omarchy é customizado via Claude: ZSH, Hyprland, Waybar, scripts, atalhos, temas, integrações. Até meus setups de gaming/emulação entram nessa, como mostrei no post dos retrogames de corrida rodando no Distrobox. Esse é um caso onde normalmente não uso ai-jail, porque justamente quero mexer no host. Então olho comandos, leio diffs, aprovo devagar. Mesmo assim, nunca tive o agente quebrando meu sistema de um jeito irrecuperável. Pelo contrário. Meu PC nunca esteve tão estável e documentado.
Dias depois, quando esqueço por que configurei alguma coisa daquele jeito, o contexto está em markdown, Git, ai-memory, ou no próprio histórico do projeto. Eu posso perguntar e o agente tem de onde puxar.
Até este post foi escrito assim
Inclusive, é assim que escrevo estes posts agora. Eu jogo um bloco enorme e bagunçado do meu cérebro no Claude. Peço pra ler posts recentes pra calibrar estilo. Peço pra checar os projetos diretamente e elaborar as partes técnicas. Peço pra usar as screenshots mais recentes, subir pro S3 quando precisa, linkar os posts anteriores, revisar o tom.
Depois eu leio e edito. Corto o que ficou genérico. Troco frase que parece release note. Coloco minhas broncas de volta. O resultado ainda é meu texto, só que agora eu gasto energia no que importa: decidir o que dizer, corrigir nuance, cortar besteira.
“Mas você testou o Pi?”
Toda vez que falo de LLM ou ferramenta de LLM, aparece alguém nos comentários com a mesma pergunta: “mas você testou Pi?”, “mas você testou DeepSeek?”, “mas e o Qwen?”, “mas e o modelo novo que saiu ontem?”. Toda. Santa. Vez.
É irritante pra cacete. E quase sempre vem de três tipos de pessoa: quem não testou nada e quer terceirizar o trabalho, quem já escolheu uma ferramenta e quer que eu valide a escolha dela, ou fanboy que trata vendor de LLM como time de futebol. Todos soam iguais. NPC repetindo diálogo de tutorial.
Engenheiro de software não deveria decidir baseado em opinião dos outros. Nem na minha. Se você escolhe ferramenta porque “o Akita falou”, você entendeu errado. Eu defendo Claude Code e Codex porque usei centenas de horas, em projetos reais, publicando código e post-mortem do que funcionou e do que falhou. E mesmo assim eu não parei em opinião.
Eu criei meu próprio benchmark automatizado: llm-coding-benchmark. Atualizo quando vendor popular solta versão nova. Rodo cenários comparáveis. Publico resultado. Depois ajusto minha opinião baseado nos dados. É por isso que eu tenho segurança pra dizer que, no meu fluxo, Opus e GPT continuam vencendo. Não porque acordei com vontade de defender logo de empresa bilionária.
Se sua primeira reação foi “mas você testou Qwen?”, ótimo. Testa você. Roda o benchmark. Cria cenário melhor. Manda PR. Mostra número. Mostra custo. Mostra latência. Mostra onde falhou. Mostra onde ganhou. Traga dado novo.
Opinião solta é irrelevante. “Pra mim funciona” não escala. “Eu gosto mais” não interessa. “No meu prompt one-shot ele foi melhor” é anedota. Engenharia começa quando dá pra reproduzir, comparar e agir em cima.
Então fica simples: traga dado acionável ou fique quieto. Eu não preciso de torcida organizada de vendor nos comentários. Preciso de gente testando, medindo e contribuindo resultado novo.
Checklist final
Resumo curto, porque este post já ficou grande:
- Foque em Claude Code, Codex ou opencode. Pare de colecionar agente.
- Use Opus 4.7 e GPT 5.5 via planos Pro/Plus/Max quando produtividade diária importa.
- DeepSeek, Kimi e modelos locais são úteis, mas ainda não substituem o fluxo principal.
- Agile Vibe Coding é XP com LLM: testes, Clean Code, CI, pair programming e deploy.
- Use
ai-jailquando quiser autonomia do agente com cerca no filesystem. - Combine
ai-jailcom permissões perigosas do Claude/Codex quando o projeto estiver protegido por Git. - Tenha backup de verdade: Btrfs snapshots, restic, NAS, offsite, Git, Bitwarden.
- Revise
git add,git diff --cachede pushes pra não vazar secrets. - Use
ai-memorypra contexto transitório e handoff entre agentes. - Escreva documentação canônica em
docs/quando a informação precisa sobreviver com garantia. - Use
ai-usagebarpra saber quando trocar de Claude pra Codex, ou quando recarregar OpenRouter. - Use
ghpendingpra não abandonar issues e PRs. - Peça refatoração explicitamente depois de features grandes.
- Rode auditoria de segurança antes de release, de preferência com mais de um modelo.
- Crie protótipos descartáveis em
experiments/antes de decidir por fé. - Se discordar de benchmark, rode o llm-coding-benchmark e traga dado novo.
- Documente decisões em markdown. Código ficou barato. Documentação também.
- Automatize deploy. Se depender de ritual manual, você vai parar de fazer.
No fim, é o mesmo conselho de sempre: ferramenta muda, engenharia não. LLM aumenta a alavanca. Se você já tinha bons hábitos, vai produzir mais. Se não tinha, vai só produzir bagunça mais rápido.
E sim, isso muda a interface do trabalho. Já escrevi sobre isso em “VS Code é o novo Cartão Perfurado”: ficar polindo pixel em editor virou nostalgia de programador velho. A parte difícil agora é escrever intenção direito, revisar execução sem preguiça, medir resultado, jogar fora código barato, e não confundir opinião com dado.