Criei um Sistema de Memória pra Agentes de Código: ai-memory
![]()
Há cinco dias eu escrevi um post longo sobre memória de agentes de código onde recomendei o agentmemory como solução. Depois de uma semana rodando ele em produção pessoal, voltei atrás. Esse post explica o que deu errado, e o projeto open source que comecei a construir pra resolver: o ai-memory.
Por que o agentmemory não rolou
O agentmemory tem as ideias certas (LLM Wiki do Karpathy, consolidação em tiers, hooks de captura automática, MCP) mas a implementação tem problemas estruturais que doem em uso diário. Os principais que peguei na prática:
- Reindexação do BM25 a cada restart. O índice persiste num arquivo (
mem:index:bm25.bin) através de um KV remoto chamado iii-engine. Com poucas observações isso voa, mas passa de 10K observações e ostate::setcomeça a dar timeout, o arquivo fica em ~96 bytes vazio, e cada restart paga ~5 minutos reconstruindo do zero (issue #309, aberta). - Janela de perda de dados de 5 segundos. Toda persistência passa por um debounce de 5s do
IndexPersistence. Quando o timeout de 30s dostate::setestoura, o processo Node morre levando junto tudo que tava em memória (#204). - Dois caminhos de leitura de config no mesmo código.
process.envdireto num lugar,getMergedEnv()em outro. O famoso “setei a variável e nada mudou” (#456). - Hook errado em ~47% das tool calls do Claude Code. O hook leu
data.tool_output, mas o Claude Code mandatool_response. Seis semanas com observações sumindo silenciosamente (#539). - Engine roda no diretório de trabalho do chamador. Usuários de Windows acharam que perderam memórias porque cada terminal abria o state store num path diferente (#303, aberta).
Tem mais. Documentei aqui no meu repo de pesquisa. O autor é responsivo, o repo tem 15.7K estrelas, e mesmo assim a arquitetura escolhida (TypeScript MCP + iii-engine Rust separado + 4 portas, 3 processos, índices em memória persistidos via KV remoto) acumula uma classe de bug que não tem como fechar sem reescrever metade do sistema. A forma do problema é estrutural, não falta de esforço do mantenedor.
Foi a mesma história com toda outra solução que testei: ou é incompleta, ou focada demais em alguma tecnologia específica (vector DB proprietário, knowledge graph que precisa de Neo4j, pipeline LLM elaborado), ou exige que o usuário grite write_note toda vez que quer salvar algo. Nenhuma “sai do caminho” o bastante pra eu confiar em sessões longas.
O que eu queria desde o começo
Quando comecei minha maratona de 37 dias de vibe coding lá em fevereiro, sabia que precisava de algum organizador de conhecimento. Levei mais de 500 horas de experimentação pra cristalizar o que eu queria de verdade.
Pra quem usa só um dos três (Claude Code, ou Codex, ou opencode) e fica nele, você provavelmente não precisa de nada extra. Os três já fazem um trabalho razoável de gerenciar memória dentro da sessão. Claude Code tem três níveis de compaction (microcompact por gap temporal, autocompact por threshold de token, sessionMemoryCompact experimental). Codex tem auto_compact_token_limit por modelo. opencode tem compaction ancorada com buffer de 20K. Cobri isso em detalhe no post anterior.
A única disciplina extra que vale a pena adotar nesse caso é manter um diretório docs/ no projeto com arquivos markdown organizados por tópico, e pedir pro agente salvar lá quando algo importante acontece. Pesquisas que não devem ser refeitas, pegadinhas conhecidas, justificativa de por que escolheu opção A em vez de B. Funciona. Exige disciplina.
O problema aparece pra quem é como eu, que pula entre agentes no mesmo projeto. Eu uso Claude Code como padrão (acho o harness, o orquestrador de subagentes, e o planning de tarefas longas superior). Mas quando o Claude empaca num problema, eu disparo o Codex no mesmo diretório só pra “agitar”. O Codex pensa mais “fora da caixa” e às vezes encontra uma solução que o Claude não enxergou. Aí volto pro Claude pra implementar com mais cuidado.
Esse vai-e-volta entre agentes é o cenário onde a memória externa importa muito. Sem ela:
- Você fecha o Claude Code, abre o Codex no mesmo diretório, e o Codex não sabe nada do que foi discutido nas últimas 4 horas.
- Você precisa pedir manualmente pro Claude escrever uma nota de handoff em
./HANDOFF.md, depois pedir pro Codex ler. Toda vez. - Projetos que você deixou parados por semanas: você abre, esqueceu por que decidiu não usar Redis, esqueceu qual era o bug que tinha na biblioteca X.
Karpathy resolveu o conceito da coisa no LLM Wiki dele, que detalhei no post anterior. Mas tem uma frase específica do gist que ficou na minha cabeça:
O
index.mdé “surpreendentemente bom — em ~100 fontes e algumas centenas de páginas, sem precisar de embeddings”.
Aquela linha resume o que eu queria. Não precisa de tecnologia complicada. Storage simples (markdown em git), índice simples (SQLite com FTS5 e links), instalação simples (um binário ou container), uso automático (hooks que disparam sozinhos), zero manutenção (memória decai sem o usuário mexer).
Foi por isso que comecei o ai-memory.
A pesquisa antes do código
Em vez de só sair codando, pesquisamos o código-fonte e issues dos projetos relevantes pra entender o que cada um acertou e errou. Salvei a pesquisa no próprio repo:
- research-karpathy-llm-wiki.md — o que Karpathy escreveu literal, separado do que a comunidade atribui (parafraseando) a ele. Três princípios fundamentais: compilação em vez de retrieval, três camadas (raw / wiki / schema), três operações (ingest / query / lint). Foi o blueprint conceitual.
- research-agentmemory.md — análise técnica do agentmemory: quatro níveis de consolidação (working → episodic → semantic → procedural), supersessão com
is_latest=falseem vez de delete, decaimento exponencial, reflexão por cluster. Mantive as ideias do agentmemory, mudei a implementação. - research-basic-memory.md — Python, MCP-native, markdown puro no disco. O modelo é explicitamente manual: o agente chama
write_notequando ele decide salvar. Bom modelo de storage, péssimo modelo de captura (depende do agente lembrar de chamar). - research-cognee.md — pipeline de cognify (extract → chunk → graph + summarize → embed → persist) com knowledge graph + vector + relational triplo. Excelente pra agente de empresa rica que quer relação semântica entre entidades. Pesado demais pra “memória de sessão de coding”.
A síntese que tirei: agentmemory tem as ideias certas. O resto é execução.
A ideia que eu mais gosto do agentmemory, e que ele herdou parcialmente do LLM Wiki v2, é a consolidação tipo sono: memória curta retém detalhes brutos, memória longa vai consolidando e resumindo, e memória de longo prazo não acessada vai sendo esquecida. Não acumula lixo. Tem accessCount, decaimento exponencial geométrico, reforço por repetição espaçada. É similar e inspirado no que um humano faz dormindo.
No ai-memory eu mantive essa estrutura mas troquei a engenharia por baixo:
- TypeScript → Rust em binário único. Sem KV remoto separado. Sem 3 processos. Um binário escrito em Rust, com um diretório de dados e um servidor Axum.
- Índice persistente em SQLite + FTS5. Nativo. Sem reindex a cada restart. WAL mode, busy_timeout 5s.
- Writer único em thread dedicada via mpsc. Sem janela de perda de 5s, sem timeout de 30s estourando.
- Markdown puro no disco como source of truth. SQLite é só índice derivado. Você pode abrir o wiki no Obsidian. Pode dar
grep. Pode versionar com git (e ele versiona automaticamente). - Isolamento por projeto na estrutura física do disco.
<wiki_root>/<workspace_id>/<project_id>/...chaveado por UUIDs estáveis. Renomear projeto é update de uma coluna. Apagar projeto érm -rfde um subdir. Mesmo nome de página em dois projetos não colide. - Embedding e LLM são opcionais. Sem chave de provedor, o sistema ainda funciona com FTS5, expansão por links e fallback nas observações brutas. Adicione embeddings quando quiser re-ranking vetorial, e Claude Haiku ou GPT-5.4-mini quando quiser páginas consolidadas com qualidade.
Como funciona no dia a dia
A interação com os agentes é por dois mecanismos: hooks/extensões (captura automática) e MCP (consulta sob demanda).
Claude Code e Codex usam shell hooks. OpenCode usa plugin TypeScript. OMP/Pi usa extensão TypeScript. Cursor e Gemini CLI usam configurações JSON de lifecycle. Todos mandam eventos equivalentes (SessionStart, UserPromptSubmit, PreToolUse, PostToolUse, PreCompact, Stop, SessionEnd) como POST fire-and-forget pro servidor HTTP do ai-memory (rodando em 127.0.0.1:49374 por padrão). O agente nunca espera. Se o ai-memory tiver fora do ar, a sessão continua normal, só sem captura. Claude Desktop e OpenClaw entram como MCP-only: consultam memória, mas não capturam ciclo de vida automaticamente.
Do lado do agente, o MCP server expõe ferramentas que o LLM pode chamar quando achar útil:
| Você diz… | Agente chama… | O que acontece |
|---|---|---|
| “Já discutimos X antes?” | memory_query | FTS5 + vizinhos por link/graph RRF sobre páginas compiladas, re-ranking vetorial opcional e fallback em observações brutas quando o wiki não acha nada |
| (antes de propor arquitetura) implícito | memory_query | Snippet de routing instrui o agente a checar decisões anteriores antes de propor algo novo |
| “Me coloca a par” / “fiquei fora um tempo” | memory_explore | Digest em prosa. Verbosidade escala com tempo desde última atividade |
| “Onde paramos?” | (handoff já no contexto) | Hook SessionStart já adicionou o handoff antes do primeiro prompt |
| “Salva contexto pra próxima sessão” | memory_handoff_begin | Escreve um handoff terso com open_questions + next_steps |
| “Consolida essa sessão” | memory_consolidate | Trigger manual do que o SessionEnd faz automaticamente |
| “Audita o wiki” | memory_lint | Detecta páginas obsoletas, contradições, sugere regras |
| “Quais são os stats?” | memory_status / memory_briefing | Conta páginas, sessões, observações e atividade recente |
O snippet de routing que vai no CLAUDE.md (ou AGENTS.md pra Codex/OpenCode/Cursor/Gemini/OMP) é o que faz o agente saber quando chamar qual ferramenta. Ele se instala com um comando: peça pro agente “instala o routing do ai-memory neste projeto” e ele invoca a tool MCP memory_install_self_routing, recebe o snippet canônico, e escreve no arquivo certo. Idempotente.
Exemplo de handoff entre agentes
Eis o cenário concreto que motivou o projeto:
$ claude
> "Tô refatorando autenticação. A rotação de JWT tá quebrada, vou
testar session cookies como alternativa."
[trabalha por uma hora]
> /exit
$ codex # mesmo diretório, horas ou dias depois
[SessionStart hook do ai-memory busca o handoff e prepende ao contexto]
> "Continuando: você estava investigando session cookies como
alternativa à rotação de JWT quebrada. Posso seguir?"Você não fez nada especial. No SessionEnd do Claude Code, o ai-memory consolidou as observações da sessão numa página sessions/<uuid>.md, criou um handoff tipado com open_questions + next_steps, e marcou como “pending”. No SessionStart do Codex, o servidor viu o handoff pending, recuperou e injetou no contexto inicial. O agente lê e continua.
Mesmo cenário se você abandona o projeto por dois meses e volta. O memory_explore calibra a verbosidade automaticamente: faz menos de uma hora desde a última sessão, retorna uma linha. Faz mais de 30 dias, retorna um resumo completo do que rolou.
Adotando ai-memory num projeto que já existe
Se você instalar o ai-memory num projeto que já tem meses de história, o wiki começa vazio e as primeiras sessões são saldo zero. Você tá populando, não recuperando. O comando ai-memory bootstrap resolve isso. Ele coleta seu git log, README, docs/, cabeçalhos de módulo e arquivos de regras do projeto (CLAUDE.md / AGENTS.md), e manda pro servidor que usa o LLM pra gerar páginas-semente do wiki:
cd ~/Projects/meu-projeto
ai-memory bootstrapCusta cerca de $0.05 com Claude Haiku 4.5 (orçamento capado em 50K input tokens). Rode com --dry-run primeiro pra ver o que seria mandado sem pagar. A partir daí o wiki começa com contexto real, e cada sessão adiciona em cima.
Instalação: três comandos
Eu reduzi a instalação ao essencial. O caminho recomendado é Docker, porque o servidor fica isolado e a atualização é uma linha. Não precisa de mais nada:
# 1. Wrapper script (~3KB) que chama o binário dentro do container
mkdir -p ~/.local/bin
curl -fsSL https://raw.githubusercontent.com/akitaonrails/ai-memory/main/bin/ai-memory \
-o ~/.local/bin/ai-memory
chmod +x ~/.local/bin/ai-memory
# 2. Sobe o servidor (loopback-only, sem auth — single-user laptop)
docker run -d --name ai-memory \
--restart unless-stopped \
-p 127.0.0.1:49374:49374 \
-v ai-memory-data:/data \
-e AI_MEMORY_LLM_PROVIDER=anthropic \
-e ANTHROPIC_API_KEY=sk-ant-... \
akitaonrails/ai-memory:latest
# 3. Configura seu agente
ai-memory install-mcp --client claude-code --apply
ai-memory install-hooks --agent claude-code --applyPronto. Abra o Claude Code como sempre. Cada prompt e tool call agora aterrissam no ai-memory, e a próxima sessão que você abrir no projeto vai ver um handoff com onde você parou.
Repita o passo 3 com --agent codex, --agent opencode, --agent omp/pi, --client cursor, --client gemini-cli, --client pi/omp, etc. pra outros agentes. Claude Desktop e OpenClaw são MCP-only. Idempotente: re-rodar substitui só a entrada do ai-memory, preserva qualquer outro hook/MCP que você tenha. Faz backup .bak-<timestamp> antes de cada escrita.
O README do projeto cobre as variações (Docker compose, homelab no LAN com bearer token, instalação sem Docker, build do fonte). Recomendo seguir o docs/install.md se seu setup foge do caminho padrão.
Comandos úteis que vale conhecer
Depois de instalado, o dia a dia normal é só usar os agentes. Mas vale conhecer alguns comandos pra quando precisar:
ai-memory upgrade— auto-atualização do wrapper +docker pullda imagem nova + re-instalação dos hook scripts/plugins/extensões. Idempotente. Se você tem servidor remoto separado, refresca só o cliente local; o servidor você atualiza separadamente.ai-memory bootstrap— semeia o wiki a partir de git log + README + docs/ + regras do projeto. Pra projetos que já existem antes do ai-memory entrar.ai-memory purge-project --project <nome> --confirm— apaga um projeto inteiro. Atômico: linhas do SQLite, subdir do wiki, sem tocar nos vizinhos.ai-memory rename-project --from <nome> --to <novo>— renomeia. Uma coluna no DB, sem mover arquivo no disco. Sem efeito colateral.ai-memory backup— snapshot do diretório de dados (wiki + SQLite).ai-memory restoredesfaz.ai-memory lint/ai-memory forget-sweep/ai-memory embed— manutenção manual. Lint e forget-sweep também rodam no agendamento do servidor por padrão; embedding backfill existe mas fica desligado por default porque pode chamar provedor pago.ai-memory generate-auth-token— quando você for expor o servidor além do loopback (verdocs/deploy.md).
Explorando o wiki no navegador
O servidor também pode montar uma UI web read-only em http://127.0.0.1:49374/web quando sobe com --enable-web. Mesmo binário, mesma porta, sem processo extra. Serve pra três coisas práticas: auditar o que o agente vem salvando, conferir se as páginas consolidadas tão coerentes, e compartilhar uma página avulsa com alguém do time sem precisar dar acesso ao agente.
A homepage lista os projetos detectados, cada um com contagem de páginas e tempo desde a última atividade:
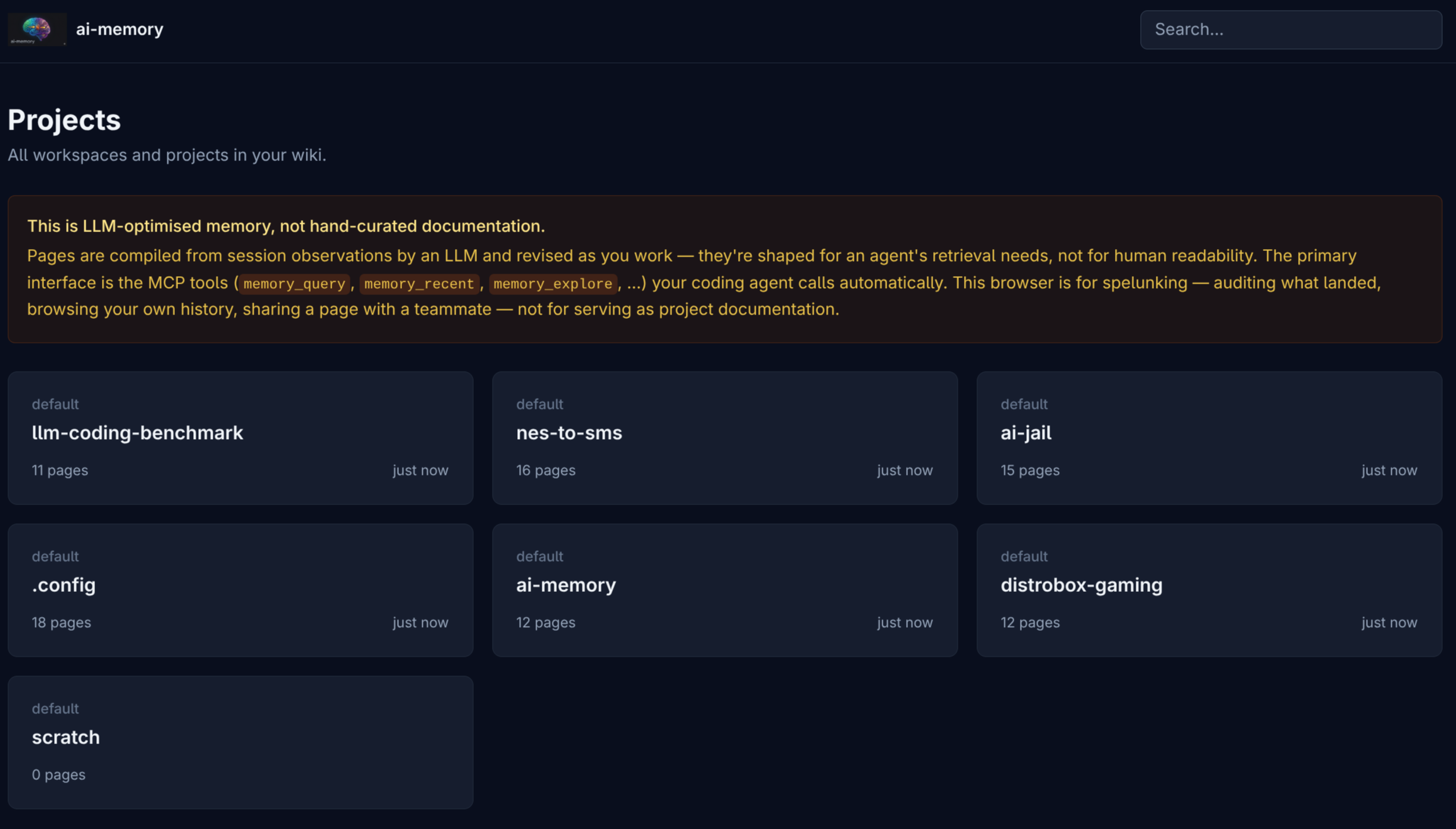
Repare no aviso laranja no topo: o wiki é otimizado pra consumo por LLM, com páginas compiladas a partir de observações de sessão pelo LLM consolidador. Pra documentação canônica curada por humano, use o docs/ próprio do projeto. O /web é pra “spelunking” (vasculhar o histórico).
Cada projeto é isolado por UUID na estrutura física do disco. Duas páginas com o mesmo path em projetos diferentes não colidem. Ao clicar num card você cai na árvore de páginas dele:
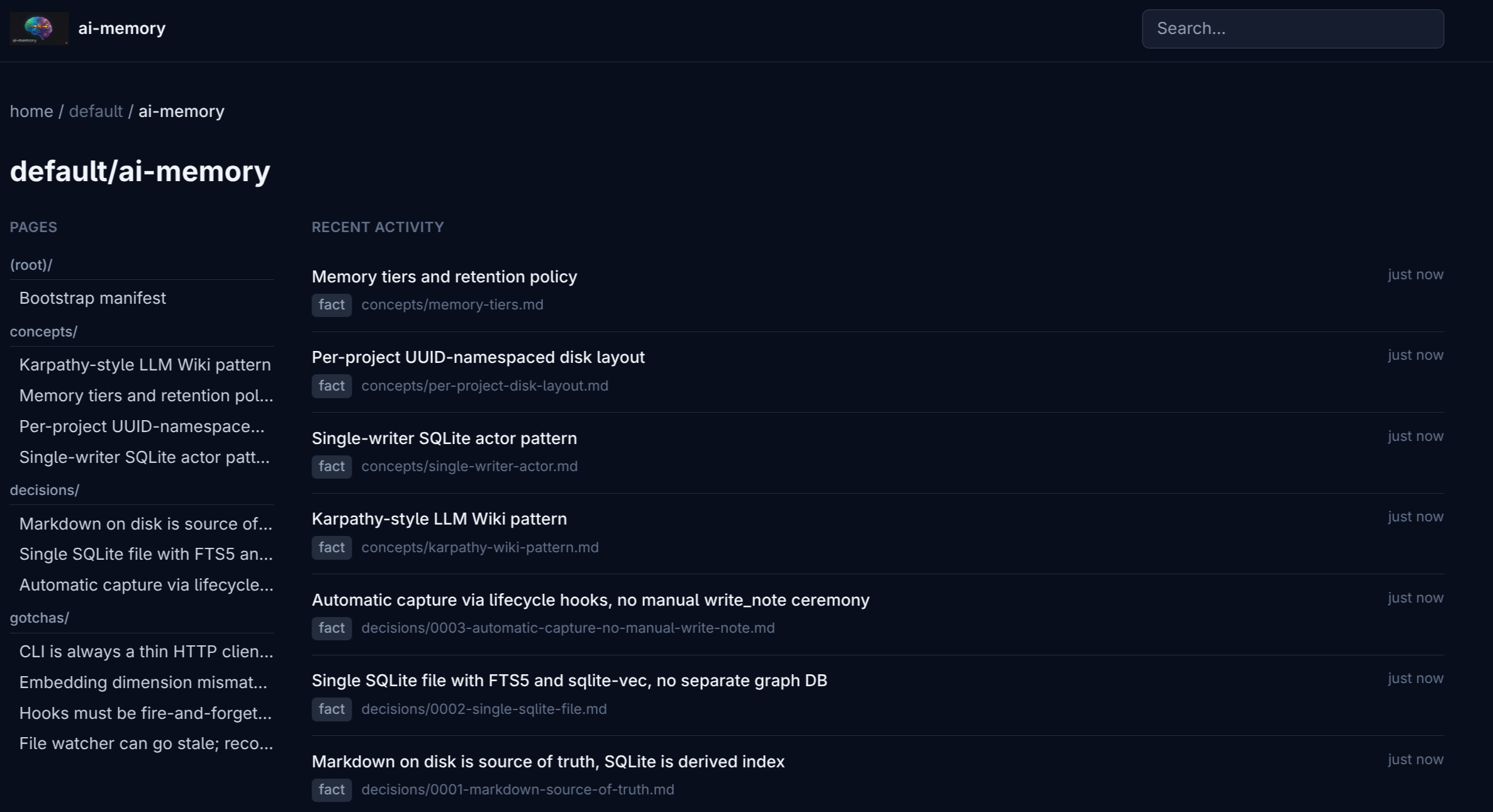
A sidebar mostra a árvore agrupada por tipo: concepts/ (conhecimento durável), decisions/ (decisões arquiteturais), gotchas/ (pegadinhas), _rules/ (regras de projeto sugeridas pro CLAUDE.md), sessions/ (logs por sessão), e bootstrap.md (manifesto gerado pelo ai-memory bootstrap). A coluna direita mostra atividade recente.
Clicando em qualquer página, você cai no markdown renderizado:
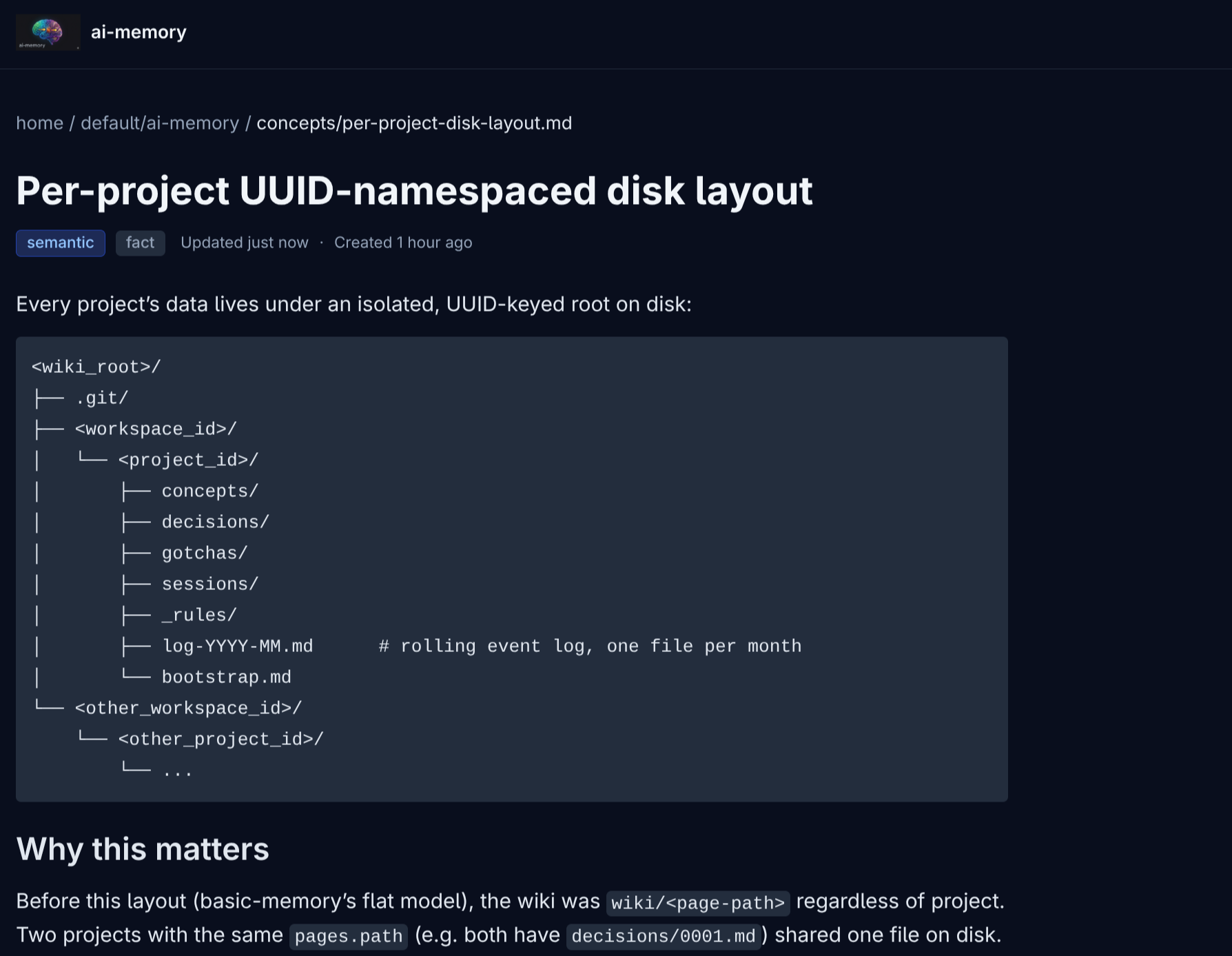
O rendering tem syntax highlighting, badges de tier (working/episodic/semantic/procedural) e kind (decision/gotcha/rule/fact), breadcrumbs, supersession chain visível. A busca combina FTS5, expansão por links e, se configurado, embeddings; modo claro/escuro segue a preferência do sistema via prefers-color-scheme.
Pra editar o wiki você abre os arquivos direto em qualquer editor de markdown (Obsidian funciona bem). A interface web é read-only por design: o LLM consolidador é quem escreve, humanos só leem.
Por que Docker
A escolha de Docker como caminho recomendado foi deliberada. Algumas vantagens práticas:
- Atualização é uma linha.
ai-memory upgradepuxa a imagem nova, refresca o wrapper, re-instala hooks/plugins/extensões. Você não compila Rust, não cuida de versão de libsqlite, não briga com mise/Node version churn como acontece com soluções baseadas em Node. - Isolamento real. O servidor roda no container, lê só
/data(volume nomeado), não polui seu sistema. Se quiser limpar, édocker volume rm. - Mesma imagem em vários setups. Laptop, desktop, homelab. Mesma imagem amd64 ou arm64.
- Restart automático.
--restart unless-stoppedfaz o servidor voltar quando você reinicia o Docker, ou quando liga a máquina (assumindosystemctl enable docker). - Build de source não é necessário. Quem compila Rust toolchain 1.95+ leva uns 3 minutos em release. Pro usuário final, isso é cerimônia desnecessária. O Docker abstrai tudo.
Tem caminho sem Docker no docs/install.md pra quem prefere. Mas Docker é onde a UX é melhor.
Qual LLM usar pra consolidação
Esse é um caso onde não precisa de modelo pesado. A consolidação é texto entra, texto sai: o agente registra observações brutas durante a sessão, no SessionEnd o LLM compila 1-5 páginas de wiki classificadas como concept / decision / gotcha / rule. Não tem raciocínio complexo, não tem código. Opus 4.7 ou GPT-5.5 thinking são overkill, custam caro e demoram muito pra uma tarefa que aceita modelo leve.
Pra escolher o default rodamos A/B testing sério em 6 provedores diferentes contra 5 fixtures sintéticas, cada uma desenhada pra estressar um modo de falha específico: extração multi-página, restrição (resistir a fabricar página quando a sessão é trivial), classificação correta de rule vs gotcha vs decision, e separação de tópicos não relacionados. A doc completa, com tabelas de parse rate, latência e qualidade por fixture, tá em docs/llm-provider-comparison.md. Resumindo a tabela final:
| Modelo | Custo | Latência | Veredicto |
|---|---|---|---|
| Claude Haiku 4.5 | ~$0.02/run | 7s | Default escolhido. Melhor classificação e restrição, sem alucinação. |
| GPT-5.4-mini (OpenAI) | ~$0.005/run | 4s | Alternativa mais barata e rápida. Leve over-classification em sessões triviais. |
| qwen3:32b (Ollama local) | $0 | 92s | Gratuito se você tem servidor local. Latência invisível em background. |
| DeepSeek V4 Flash | ~$0.005/run | 22s | Funciona, mas sem vantagem sobre GPT-mini ou Haiku. |
| Sonnet 4.5 | ~$0.06/run | 11s | Substituído pelo Haiku. 3× o custo, mais alucinação. |
| Kimi-K2.6 | n/a | trava | INELIGÍVEL. Modelo de raciocínio consome o budget de tokens internamente antes de emitir conteúdo. |
Por que Haiku ficou como default: hospedado (sempre disponível), o melhor em restrição (resiste a fabricar páginas quando a sessão é trivial, crucial pra wiki não virar coleção de páginas vazias) e o melhor em classificação (acerta kind: rule consistentemente, que é o que faz o roteamento automático pro _rules/<slug>.md funcionar). Custo de $0.02 por consolidação é desprezível pra uso pessoal.
Mas o usuário tem alternativas legítimas:
- GPT-5.4-mini se o orçamento aperta (5× mais barato que Haiku, 2× mais rápido). O único defeito mensurável foi fabricar uma página
decisions/docs-spelling.mdnuma sessão de correção de typo. Over-classification, mas leve. - qwen3:32b no Ollama se você tem servidor local com ~20GB de RAM/VRAM disponível. Zero custo por consolidação, fidelidade compatível com os hospedados. A latência alta (~92s) não importa porque consolidação roda em background.
- DeepSeek V4 Flash funciona, mas o GPT-mini iguala em qualidade e bate em velocidade.
Quem quiser testar outros modelos, o harness de avaliação tá em evals/ como crate Rust separada. Adiciona um JSON de fixture, roda cargo run -p ai-memory-eval --release, compara dois provedores lado a lado. Os outputs ficam em evals/runs/<timestamp>/{baseline,candidate}/ com o .raw.txt exato que o modelo respondeu mais o .meta.json com latência e parse rate. PRs com novos modelos testados são muito bem-vindos.
Status: beta, falta usuário
O ai-memory tá nas tags v0.2-complete no GitHub. As funcionalidades principais funcionam: captura automática, MCP, web UI opcional, bootstrap, purge/rename/backup, bearer auth, browse, busca FTS5 + graph/link-neighbour RRF, embeddings opcionais, consolidação, decay, manutenção agendada e handoff entre Claude Code / Codex / OpenCode / Cursor / Gemini CLI / OMP-Pi. Eu rodo em produção pessoal há algumas semanas.
Mas é beta. Precisa de muito mais usuário batendo nele pra eu encontrar os bugs que ainda não aparecem na minha máquina. Claude Desktop e OpenClaw funcionam como MCP-only; alguns clientes MCP exóticos ainda precisam de teste real. A integração mais polida hoje é Claude Code, seguida de Codex, OpenCode e OMP/Pi.
Se você tá lendo até aqui, considera instalar e me mandar feedback. Issues no github.com/akitaonrails/ai-memory/issues. PRs são muito bem-vindos — o código é Rust, MIT, e a arquitetura tá documentada em docs/ARCHITECTURE.md e docs/design-decisions.md. Mesmo bug report de “instalei, não rodou no meu setup” ajuda — significa que tem algo que assumi sobre ambientes que não bate com o seu.
A motivação central continua sendo a frase do Karpathy. Memória de agente é texto. Texto fica no disco. Indexa com SQLite. Compila com LLM quando vale o trabalho. Esquece quando ninguém olha mais. Sai do caminho. E quando você troca de agente no meio do projeto, o próximo já sabe onde você parou.
É isso que o ai-memory tenta entregar.