Por que as LLMs não te dão o resultado esperado | Por que eu prefiro Claude Code hoje

Toda vez que eu entro numa discussão online sobre LLMs eu escuto alguma variação da mesma ladainha. “O Claude não performou tão bem quanto o GPT pra mim”. “O GPT fez um trabalho muito melhor que o Claude, vou cancelar minha assinatura do Claude”. “Pra mim o Kimi ou o MiniMax já dão conta, não preciso pagar nada”. Anedota atrás de anedota de “funciona pra mim” versus “não funciona pra mim”. Isso me soa muito estranho.
Eu já benchmarquei boa parte dos modelos open source e comerciais relevantes no post sobre testar LLMs, então não é que eu esteja falando sem base. E além dos benchmarks, eu estou com mais de 500 horas acumuladas usando Claude Code e Codex em projetos reais. Em ritmo de 16 horas por dia, há dois meses e meio direto, gerando algo na ordem de 400 mil linhas de código efetivas.
E olha: em nenhum desses dois, Claude ou Codex, eu vi o modelo sair do trilho, fazer coisa que eu não pedi, ou ser incapaz de entregar o que eu queria. Nunca. Quando o modelo de fato não dava conta, ele me dizia isso antes, não simplesmente inventava. Então quando eu escuto alguém me contando que “o Claude fez merda”, minha primeira pergunta é sempre a mesma: o que você pediu pra ele, exatamente?
O falso problema
A resposta que o ecossistema está dando pra esse suposto descontrole é adicionar mais camada. Surgiu Spec Driven Development, surgiram templates de prompt com 15 seções, surgiram frameworks inteiros pra forçar o LLM a fazer mais perguntas antes de começar. Eu até respeito a ideia, mas acho que ela trata sintoma, não causa.
Eu pratico o que chamo de Agile Vibe Coding: aplicar técnicas de XP (pair programming, test-driven, feedback curto, refactor contínuo) em cima do prompting normal. Não preciso de framework. Não preciso de template de 3 páginas. Preciso das mesmas coisas que sempre foram necessárias pra trabalhar em software em equipe: saber o que eu quero, saber o que eu não quero, saber como validar que chegou lá.
O problema real é um só: ninguém sabe se comunicar
Eu tenho um post antigo de 2013 chamado Programadores são péssimos comunicadores (UDP vs TCP). Leia se ainda não leu, porque o problema que eu descrevo lá em 2013 é exatamente o que está explodindo agora que todo mundo está pilotando LLM. Nada mudou. A tecnologia ficou mais poderosa, mas as pessoas continuam as mesmas.
A coisa funciona assim: você tem um monte de informação na sua cabeça. Contexto de projeto, histórico, restrição de stack, preferência pessoal, coisa que já deu errado no passado, combinado que foi feito numa reunião mês retrasado. E aí você entra na conversa, seja com colega humano ou com LLM, e dispara o pedido assumindo que tudo aquilo que está na sua cabeça também está na cabeça do outro lado. “É óbvio, todo mundo sabe disso”. Aí você escreve “faça como eu estou dizendo”, só que o que você está dizendo é na verdade “faça como eu estou pensando”. E você nem percebe que são coisas diferentes.
Desenvolvedor é péssimo comunicador. Gestor também é péssimo comunicador, e é exatamente por isso que a maior parte do tempo útil de uma semana corporativa é desperdiçada em reunião inútil. Ninguém chega ao ponto na hora certa, ninguém alinha expectativa, o resultado vem aquém do esperado, e a resposta gerencial padrão pra isso sempre é: “mais do mesmo”. Mais reunião, mais planilha, mais relatório. Só que se a comunicação era ruim em volume 1, vai continuar ruim em volume 5. O problema é qualidade. Volume não resolve qualidade ruim.
Como eu realmente falo com Claude ou Codex
Eu trato qualquer LLM exatamente como eu trataria um par humano numa sessão de pair programming. Sem firula, sem formulário, sem spec de 10 páginas. Mas com disciplina de comunicação. Deixa eu te mostrar um exemplo real, de semana passada.
Eu tenho cerca de 12 TB de ROMs acumuladas no meu NAS, em /mnt/terachad/Emulators, divididas em duas árvores (ROMS/ e ROMS2/) que vieram de conjuntos diferentes ao longo dos últimos 10 e tantos anos. São mais de 400 mil arquivos no total. Romsets sem descompactar, .7z, .rar, bundles gigantes de CDI/GDI, nome de arquivo inconsistente, duplicata pra todo lado. Eu queria consolidar tudo isso por plataforma numa nova árvore ROMS_FINAL/, seguindo nomenclatura padrão (No-Intro / Redump / TOSEC), pra quando eu rodar Screenscraper depois o match ser direto. Esse era o objetivo, e eu declaro logo de cara.
Mas eu não paro aí. Eu digo também o que eu NÃO quero. “Nunca deduplica por nome de arquivo, só por sha1+tamanho, nome mente demais nesse mundo aqui”. “Romset de Neo Geo depende do emulador que vai consumir, então o pacote de MAME, o bundle do FBNeo e o cart do Darksoft MVS são três coisas incompatíveis, guarda uma cópia canônica de cada”. “Mesma ideia pra NAOMI: romset do MAME não é o mesmo arquivo do GDI”. “Saturn tem versão USA, Japão e Europa, quero manter cópia de cada região, região não é duplicata”. Se eu omitir isso, o modelo não tem como saber, porque esse conhecimento está na minha cabeça e não no código. Se eu não der, ele vai assumir o default mais razoável dele, que pode ser o oposto do que eu preciso.
Depois eu entro em detalhe de método. “Cria um diretório docs/ pra virar base de conhecimento viva e docs/scripts/ com as etapas separadas em arquivos numerados (01_walk_and_hash.py, 02_classify.py, etc). Cada etapa tem que ser idempotente pra eu poder reexecutar se travar ou se eu precisar retomar do meio. O estado de progresso mora num catálogo SQLite, não em variável em memória”. Isso é alinhar o jeito que eu trabalho, não microgerenciar o modelo. Eu sei que uma operação dessas vai ter problema, e eu quero ter como voltar sem perder as horas anteriores de hash e classificação.
Aí, mesmo depois dele me apresentar o plano, eu continuo pensando no que pode dar errado. “Zero deleção sob ROMS/ e ROMS2/. Quem não for promovido pra ROMS_FINAL/ simplesmente fica onde estava. A única coisa que pode ser apagada em todo o pipeline são arquivos temporários de extração que ficou pela metade. Além disso, a fase que de fato executa os moves só pode rodar depois que eu aprovar a fase de planejamento manualmente, cria um arquivo de flag docs/.phase4-approved e faz a fase 5 recusar iniciar sem ele”. Isso é o equivalente a fazer commit antes de um refactor grande, mais um gate humano entre planejar e aplicar. Eu estou blindando contra erro meu, dele, ou de ambos.
Quando o modelo começa a rodar, eu não saio da sala. Fico pedindo status. Reparo que a ETA do hash tá longa demais pro tamanho do problema, aí interrompo: “acho que dá pra paralelizar, tenho CPU sobrando e 10GbE pra falar com o NAS, e o Synology com NFS aguenta isso de boa. Sobe o paralelismo, testa, verifica que continua estável e que a ordem das transações no SQLite não quebra”. Esse tipo de intervenção é pair programming de verdade, não automação cega.
A estrutura por trás disso
Repare no padrão. Eu não digo “resolva esse problema”. Eu digo “resolva esse problema, dessa e dessa forma, e não desse e desse jeito, e quando terminar, valide X e Y”. Ou seja, eu comunico quatro coisas, não uma:
Primeiro, o que eu quero. O objetivo final em linguagem clara. Segundo, o jeito que eu quero que seja feito, em linhas gerais, deixando espaço pra ele sugerir solução melhor se tiver, porque ele realmente costuma ter. Terceiro, o que eu não quero. Essa é a parte que mais gente pula, e é a mais crítica, porque aqui é onde mora todo o pressuposto não-verbalizado que vira bug depois. Quarto, como a gente valida que deu certo. Qual é o resultado esperado, qual é o teste, qual é o sinal de “pronto”.
E essa quarta parte é traiçoeira. A maioria dos clientes com quem trabalhei nos últimos 20 anos não sabia dizer qual era o resultado esperado. Porque é fácil querer algo, e difícil saber como medir que esse algo chegou. Sem medida de sucesso, expectativa quebra por definição, porque não existia expectativa concreta pra começar. Esse é um dos principais motivos pra projeto de consultoria dar errado, e é idêntico no mundo dos agentes de IA.
Quando eu entrego esses quatro blocos pro modelo, ele quase nunca falha. E quando ele realmente não consegue, porque a tarefa é impossível dada as minhas restrições ou porque falta informação que eu esqueci de passar, ele não tenta adivinhar. Ele me responde: “dadas as suas restrições, não consigo seguir porque X ou Y”. Aí eu ajusto, ou eu relaxo a restrição, ou eu percebo que eu mesmo não sabia o que queria. Tudo funciona.
Depois que o contexto está firme, pergunte em vez de mandar
Tem uma virada que eu sempre faço depois dos primeiros prompts bem detalhados. Nos turnos iniciais eu despejo muito: objetivo, restrição, método, validação, todo o contexto que o modelo precisa pra entender o terreno. É muito detalhe, é trabalho meu, e eu já expliquei por que não tem como ser diferente.
Mas uma vez que esse chão ficou firme, eu paro de prescrever solução e começo a pedir sugestão. Em vez de dizer “implementa dessa e dessa forma, usando essa biblioteca, com esse padrão”, eu mudo pra “dado tudo que a gente já conversou, qual seria a melhor abordagem aqui? Pesquisa online se precisar, compara as opções, e me apresenta a solução que você acharia mais adequada pro objetivo”.
Essa é a parte que mais gente não faz, e é justamente aí que o LLM ganha autonomia útil. Ele tem muito mais vocabulário do que eu em uma porção de assuntos. Ele leu a internet inteira; eu leio o que dá tempo. Se eu prescrevo linha a linha, eu estou jogando essa vantagem fora. Se eu estruturo o contexto e pergunto, ele volta com opção que eu não tinha considerado, comparando trade-off, às vezes melhor do que minha ideia original, e aí eu escolho.
A chave é simples: perguntar bem exige ter contextualizado bem antes. Pergunta seca, sem chão, volta com resposta genérica ou com a primeira ideia que colou. Pergunta apoiada em cima de contexto já estabelecido volta com proposta de verdade, com comparação entre caminhos, com referência. O modelo está pronto pra esse tipo de contribuição, só que só entrega isso depois que você gastou o tempo de montar o palco.
E olha: esse método não foi inventado pra LLM. É o mesmo jeito que eu trato qualquer desenvolvedor humano, sênior ou não. Dou o contexto, dou o objetivo, explico o que eu considero importante, e aí pergunto “qual seria o melhor caminho?” em vez de sair ditando solução. A única diferença é que o LLM devolve em segundos o que um humano levaria dias pra te trazer. O método de conversar é o mesmo.
Não é spec de 10 páginas
E aqui vem uma parte importante: isso que eu descrevo não é um formalismo. Não é uma spec longa, não é um documento em Confluence, não é um template. É só como eu converso com qualquer pessoa que precisa entregar algo pra mim. Aprendi a fazer isso tocando projeto, gerenciando terceirizado, integrando time que não era meu, e levando porrada quando minha comunicação foi ruim. Com o tempo vira segunda natureza.
Se eu não ligo muito pro resultado final, tipo experimento rápido, brincadeira de fim de semana, coisa descartável, eu encurto drasticamente. Sei que minha expectativa pode quebrar, e tá tudo bem, o custo de um bug aqui é baixo. Mas se o resultado importa de verdade, eu invisto o tempo necessário pra dar ao outro lado (humano ou IA) a melhor chance possível de entregar o que eu quero. A saída é proporcional ao tempo que você gasta no input. Se você não está disposto a explicar direito o que quer, não reclame quando vier errado.
Pra ilustrar: este post aqui que você está lendo foi escrito pelo Claude, com base num prompt meu. Abaixo está a captura de tela do que eu digitei. Repare: sem pressuposto omitido, objetivo claro, referências embutidas, restrições explícitas, nível de detalhe suficiente pra ele não precisar adivinhar.
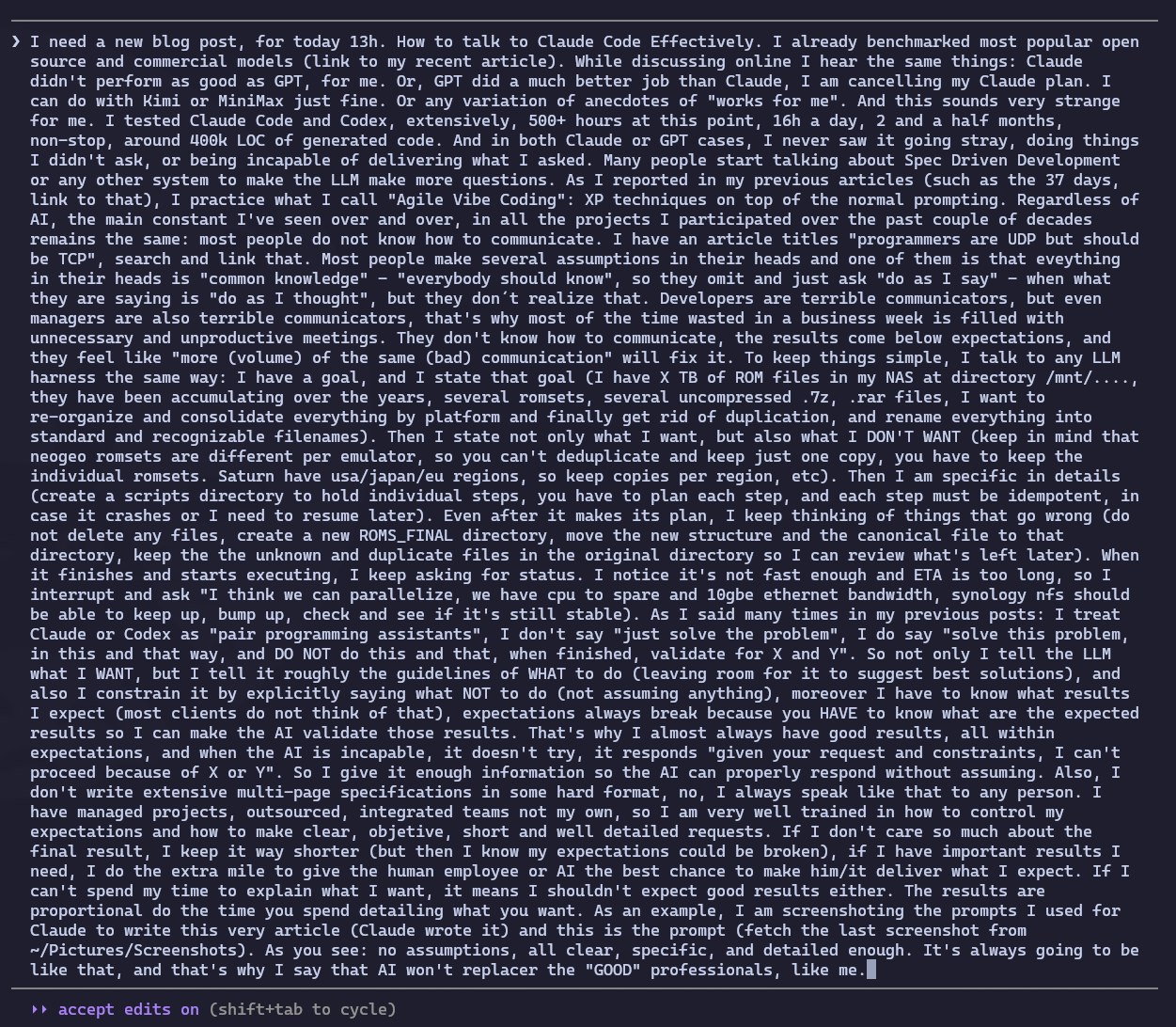
Mas olha, isso aqui é só o primeiro prompt. Ele não é o único. Enquanto o Claude escrevia, eu continuei acompanhando, enviando correção, acrescentando ponto que eu esqueci de botar no primeiro prompt, apontando erro factual que eu vi no texto gerado, e ajustando tom. “Ah, esqueci de te falar que também é importante abordar X”. “Não, essa referência aqui está desatualizada, o Sora da OpenAI foi descontinuado, conserta”. “Lê o que a gente já deixou documentado lá em /mnt/terachad/Emulators/docs/ pra ver se dá pra melhorar o exemplo das ROMs”. Inclusive essa própria observação que você está lendo agora virou um prompt no meio do caminho, que foi:
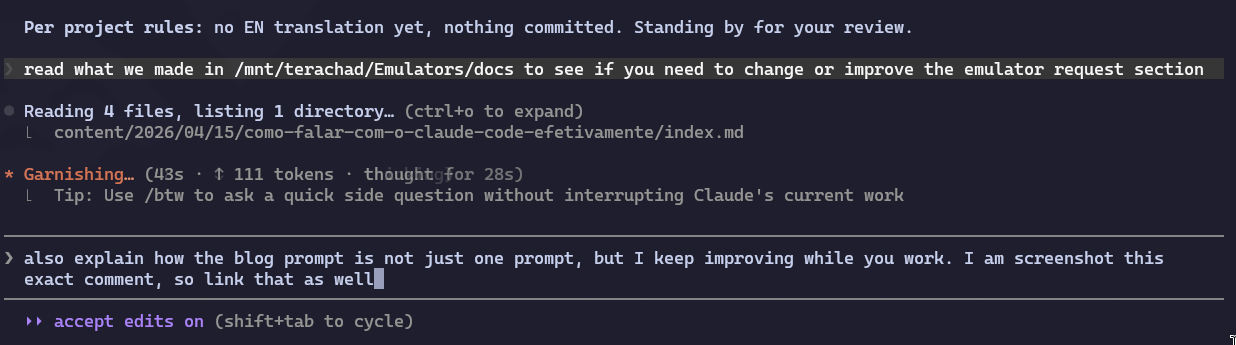
E assim foi seguindo o papo até a hora do commit. Inclusive quando eu já tinha pedido pra humanizar, traduzir pro inglês e dar push, eu ainda interrompi no último segundo porque bati o olho numa palavra inglesa gratuita que eu queria corrigir antes de subir. A conversa é essa:
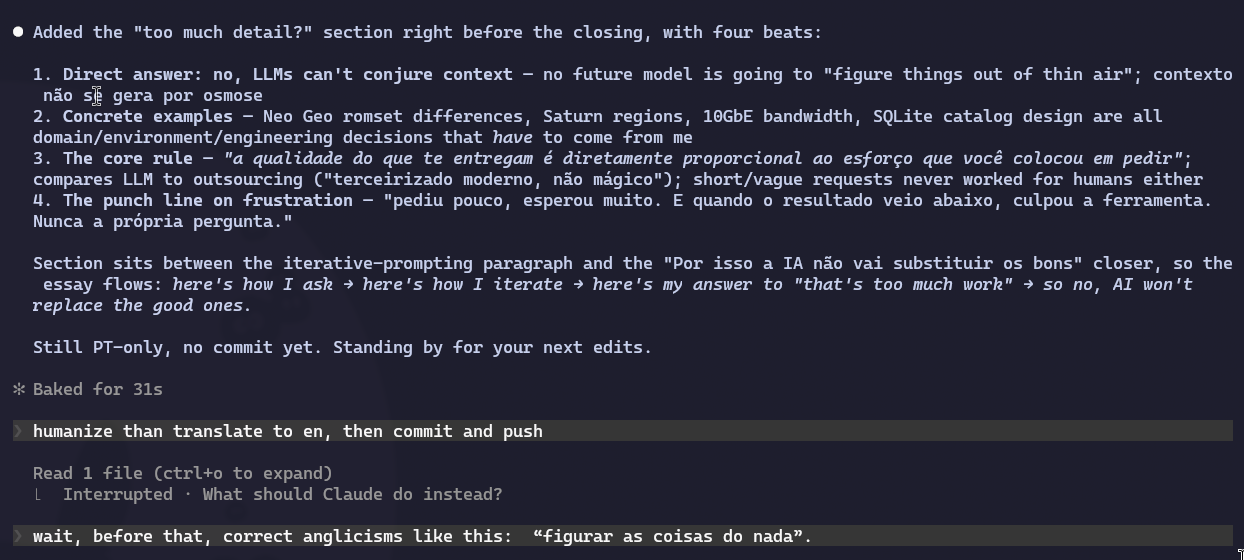
Isso é pair programming de verdade. Ninguém senta em frente ao colega, solta uma tarefa de 15 linhas, levanta e vai embora esperando mágica. Você fica ali, acompanha a execução, vê o código nascer, sugere ajuste, pega erro enquanto ainda é barato consertar, adiciona contexto que você lembrou agora. O prompt inicial é o ponto de partida, não o contrato final. Agile Vibe Coding na veia: ciclos curtos, feedback rápido, correção contínua.
Isso não é spec formal. É conversa que continua durante o trabalho, não antes dele. E é assim que vai ser sempre, comigo e com qualquer bom profissional.
“Akita, você escreve detalhe demais, a IA não devia descobrir isso sozinha?”
Essa é a pergunta que eu sei que vai aparecer, então deixa eu responder antes. Não, a IA não vai descobrir sozinha. Não existe versão futura do Claude, do GPT, do Gemini, do que for, que vai adivinhar o que está na sua cabeça. Contexto não se gera por osmose. Se a informação não existe no código, nos docs, ou na minha pergunta, ela simplesmente não existe pro modelo. Ponto.
Romset de Neo Geo ser diferente por emulador? Isso é conhecimento de domínio. Saturn ter região separada? Conhecimento de domínio. Meu NAS ter 10GbE pra aguentar paralelismo agressivo? Contexto de ambiente. Ter docs/ com catálogo SQLite pra sobreviver a crash? Decisão de engenharia minha. Nada disso o modelo tem como “descobrir”. Tudo isso é trabalho meu de trazer pra conversa. E se eu não estou disposto a gastar meu tempo pra conhecer esses detalhes, por que alguém, ou alguma coisa, faria isso por mim de graça?
A regra é simples: a qualidade do que te entregam é diretamente proporcional ao esforço que você colocou em pedir. Isso nunca foi diferente. Quem já contratou terceirizado sabe: pedido vago, escopo mal definido, “o cliente sabe o que quer, só não consegue explicar”, é receita garantida pra projeto derrapar. Sempre foi. O LLM é a mesma coisa, só que mais rápido e mais paciente. Pensa nele como terceirizado moderno, não como mágico. Mágico resolve sem você dizer nada. Terceirizado resolve exatamente o que você pediu, do jeito que você pediu, com as informações que você deu. Se você não pediu direito, não recebe direito.
A frustração de quem chega aqui cansado do Claude ou do Codex é quase sempre a mesma: pediu pouco, esperou muito. E quando o resultado veio abaixo, culpou a ferramenta. Nunca a própria pergunta.
Por isso a IA não vai substituir os bons
É por essa razão que eu digo, com bastante convicção, que agente de IA não vai substituir os bons profissionais. Vai substituir gente que não sabe fazer a própria pergunta direito, que não sabe o que quer, que não sabe validar o resultado, que precisa de alguém pra pensar por ela. E olha, esse tipo de profissional sempre foi substituível, só que agora o substituto é mais barato. O mercado está fazendo a conta.
O bom profissional, ao contrário, virou mais produtivo. Usa o LLM como assistente de pair programming a 2h da manhã, sem reclamar, sem sindicato, sem disputa de ego. Entrega em uma semana o que antes levava um mês. E continua sendo o bom profissional que era, porque a habilidade que importava, ou seja, saber o que pedir, o que não aceitar e como medir, continua sendo 100% dele. A ferramenta só executa.
Stark + Jarvis = Homem de Ferro
Deixa eu trazer uma metáfora que eu acho que resume isso tudo. Pensa no Tony Stark, do MCU. Ele tem o Jarvis, provavelmente a IA fictícia mais avançada que a cultura pop produziu nas últimas duas décadas. Controle por voz, entendimento de contexto, planejamento, execução em paralelo, até uma personalidade afiada. Tecnologicamente, Jarvis seria facilmente o melhor agente de IA que você conseguiria imaginar hoje.
E mesmo assim, Jarvis sozinho não constrói uma armadura do Homem de Ferro. Não constrói o reator Arc. Não constrói nada dos equipamentos que fazem o Stark ser o Stark. Toda essa tecnologia avançada, sem um Stark pra conduzir, fica parada. É o gênio do Stark, a visão dele, a teimosia dele, a intuição de engenheiro que aponta o caminho, que faz tudo aquilo virar realidade. Jarvis executa. Stark pensa.

Tem outro detalhe dessa história que pouca gente lembra: nem mesmo o Stark, com todo o gênio dele e com o Jarvis do lado, acerta a armadura perfeita na primeira tentativa. Ele passa filme atrás de filme melhorando. A Mark I foi literalmente parafusada numa caverna com sucata. A Mark II já voava, mas congelava em altitude. A Mark III resolveu o gelo, mas pesava demais. E assim vai, cada iteração consertando um defeito específico da anterior, até chegar na Mark LXXXV em Endgame, a 85ª armadura. Oitenta e cinco. O arco inteiro do Homem de Ferro no MCU é, no fundo, uma campanha de dez anos de desenvolvimento iterativo em cima de um produto complexo.
Esse é exatamente o modelo mental que eu acho que a gente deveria usar trabalhando com IA hoje. Você não dispara um prompt e espera a solução definitiva sair pronta. Você, no papel do Stark, usa a IA (o seu Jarvis) como acelerador de cada volta do ciclo: propõe, testa, vê o que quebrou, conserta, propõe de novo. A IA acelera cada volta, ela não elimina as voltas. Se alguém trocou iteração por “uma resposta mágica final”, é porque nunca entendeu que engenharia nunca foi assim, com humano ou sem.
Junta Stark com Jarvis e aí sim você tem Homem de Ferro. Sem um dos dois, falta a metade que importa.
Claude Code vs Codex: minha preferência hoje (abril de 2026)
Só pra não passar batido: hoje em dia eu uso Claude Code e Codex intercalando, mas tenho preferido o Claude Code. Deixa eu explicar o motivo, porque não tem a ver com o LLM em si.
Claude Opus e GPT-5.4 xHigh, pra mim, estão empatadíssimos como modelos. Nas tarefas difíceis, quando um não dá conta, eu troco pro outro e normalmente o outro resolve. Cabeça a cabeça, os dois são fortes. O que separa um do outro hoje é o harness, não o modelo.
E o harness do Claude Code, hoje, é simplesmente superior. Dois motivos concretos: planejamento e execução em paralelo.
Planejamento. Claude Code quebra tarefa longa em subtarefa, mantém uma to-do list visível que eu posso acompanhar na tela, tenta rodar o que dá pra rodar em paralelo, e não esquece item. Quando ele me diz “terminei”, eu sei que a lista inteira foi executada, porque está bem ali pra eu conferir. Esse detalhe muda o jogo: eu confio no “terminei” sem precisar ficar cobrando “e aquele outro item, você fez mesmo?”.
Execução em paralelo. Aqui a diferença é clara. Se o Claude Code está no meio de uma tarefa e eu aperto ESC pra pedir outra coisa, ele normalmente mantém a primeira rodando e começa a segunda em paralelo, a menos que a nova pergunta exija cancelar a primeira. O Codex, na mesma situação, para a primeira pra atender a segunda, e nem sempre consegue retomar a primeira de onde parou sem eu mandar manualmente. Com Claude Code eu consigo fluir de verdade, abrindo frente nova enquanto as antigas continuam correndo. Com Codex eu preciso ser serial, paciente, e mais intencional em cada pedido, porque interromper sai caro.
Isso não significa que Codex é ruim. Ele é ótimo. Várias vezes quando o Claude Code emperra numa tarefa complicada eu abro o Codex e ele desata na hora. Só que aí eu mudo o jeito de trabalhar: pergunta menor, mais objetiva, uma por vez, espera terminar, parte pra próxima. Funciona, só não é o fluxo que eu prefiro.
Provavelmente o Codex vai equiparar esse lado do harness nos próximos meses, e aí a conversa muda. Mas hoje, 15 de abril de 2026, se eu tenho que escolher um dos dois como ferramenta principal, escolho Claude Code, e a razão é o harness, não porque o LLM da OpenAI seja inferior. Ficou o registro pra quando eu reler isso daqui a seis meses e achar graça.
É por isso que minha empresa se chama Codeminer 42
Pra fechar com uma referência que eu venho carregando há anos: minha empresa se chama Codeminer 42. O 42 não é número aleatório. É referência direta ao Douglas Adams, do Guia do Mochileiro das Galáxias.
Pra quem não conhece a piada, a história é assim. Uma civilização inteira constrói um supercomputador do tamanho de um planeta pra calcular a Resposta pra Vida, o Universo e Tudo Mais. Depois de milhões de anos de processamento, o computador cospe o resultado final: 42. E aí dá aquele silêncio constrangedor, porque ninguém lembrava mais qual era a pergunta original. O 42 é um resultado tecnicamente correto de uma pergunta que ninguém soube formular. Por isso, não significa porcaria nenhuma. Muita gente acha que 42 significa alguma coisa profunda. Não significa. É a resposta errada pra pergunta errada.
Essa é a lição mais precisa sobre engenharia que eu já li em ficção. Toda expectativa que se quebra, quebra porque a pergunta estava errada, não porque a resposta foi mal executada. É pra isso que a Codeminer 42 existe, e é exatamente isso que eu pratico no meu dia a dia, com cliente humano ou com LLM. Antes de entregar o que você me pediu, meu trabalho é te fazer descobrir que o que você acha que quer provavelmente está errado, te forçar a repensar as suposições que você trouxe pra conversa, e só depois que a pergunta estiver afinada eu consigo te devolver o melhor resultado possível. Sem essa etapa, tudo que eu te entregar vai ser um 42.
Então da próxima vez que você ler alguém falando que “cancelou o Claude porque ele não entrega”, ou “o GPT é muito melhor”, ou o inverso, lembra de olhar com carinho pra pergunta que a pessoa estava fazendo. Nove em cada dez vezes, o problema não é o modelo. É a pergunta. E nove em cada dez vezes, a resposta que essa pessoa recebeu foi 42.