Transformando YouTube num App de Karaoke | Frank Karaoke
Projeto no GitHub: github.com/akitaonrails/frank_karaoke
Eu sempre gostei de karaokê. De vez em quando saio pra cantar com família ou amigos. Em São Paulo tem bons lugares na Liberdade e no Bom Retiro, por exemplo, com cabines no estilo japonês. Se você nunca foi num karaokê desses: você aluga uma sala privada por hora, tem um catálogo enorme de músicas, dois microfones, e um sistema de pontuação que avalia seu canto em tempo real. Os melhores sistemas são japoneses, como o Joysound e o DAM. Nota acima de 90 (de 100) é considerada avançada. O DAM, na série LIVE DAM Ai, até usa IA pra dar notas mais “humanas”.
Mas nem todo lugar tem esse nível.
O problema com karaokê no Brasil
No Brasil a gente cresceu com o Videokê, a marca que o coreano Seok Ha Hwang trouxe pro país em 1996, importando equipamento da Coreia. Virou febre nos anos 90 e 2000, apareceu em todo bar, churrasco e festa de aniversário. O problema é que esses aparelhos pararam no tempo. Os modelos atuais, como o VSK 5.0, vêm com uns 12-13 mil músicas no catálogo, que você expande comprando cartuchos ou pacotes de música. Na prática, o repertório é velho, a interface é dos anos 2000, e se a música que você quer cantar saiu depois de 2015, boa sorte.
A solução que muitos bares adotaram foi permitir Chromecast ou espelhamento de tela pra que os clientes busquem músicas direto no YouTube. Faz sentido: no YouTube você encontra karaokê de qualquer música. Versão com letra, versão instrumental, versão com guia vocal.
Mas tem um downgrade: você perde a pontuação. Uma das coisas mais divertidas do karaokê é a competição. Ver sua nota subindo, comparar com os amigos, tentar bater o recorde da noite. Se você está só cantando em cima de um vídeo do YouTube, não tem feedback nenhum. É como jogar boliche sem placar.
E comprar um sistema profissional pra casa? Importar um Joysound F1 sai por mais de US$ 2.000 só o hardware, fora a assinatura mensal do catálogo. Pra uso casual não faz sentido.
A ideia: YouTube com pontuação em tempo real
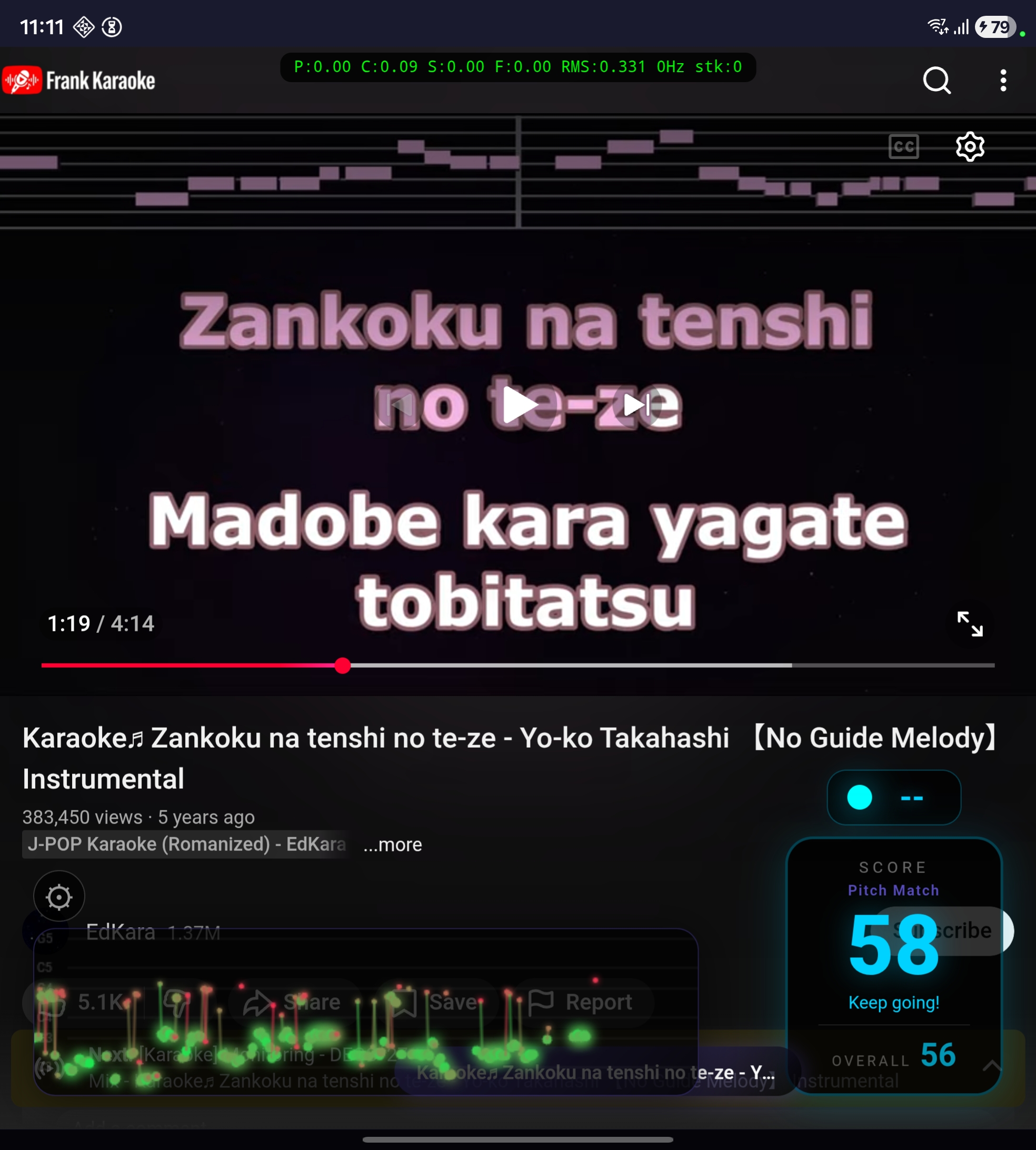
O Frank Karaoke surgiu dessa frustração. Se o YouTube já tem todas as músicas, por que não fazer um app que funciona como wrapper do YouTube com overlay de pontuação em tempo real? Você busca qualquer vídeo de karaokê, canta junto, e o app analisa sua voz pelo microfone e mostra uma nota ao vivo.
É um app Flutter pra Android. Internamente ele carrega o YouTube numa webview e injeta um overlay em HTML/CSS/JavaScript direto na página. O display de score, o trail de pitch, o painel de configurações, o seletor de modo, tudo renderizado dentro da webview via injeção de JS.

Scoring sem referência
Agora, o problema real. Todos os sistemas profissionais de karaokê dependem de arquivos de referência pré-fabricados pra cada música. Todos.
O SingStar da Sony, que vendeu mais de 12 milhões de cópias entre 2004 e o fim do PS3, tinha um track de notas feito à mão pra cada música. Cada nota, cada sílaba, tudo mapeado manualmente. O mecanismo comparava o pitch do cantor via FFT contra essa referência em tempo real. Detalhe que eu achei esperto: a oitava era ignorada. Se a nota certa era um Dó, tanto faz se você cantou Dó3 ou Dó4. Homens cantam músicas femininas sem problema.
O Joysound e o DAM no Japão vão além e avaliam três dimensões separadas: precisão de pitch (音感), ritmo/timing (リズム感) e expressividade/dinâmica de volume (表現力). Tudo baseado em dados MIDI do servidor do operador. O formato open source equivalente é o UltraStar, onde cada música tem um arquivo .txt assim:
: 12 4 5 Hel- (TipoNota BeatInicial Duração Pitch Sílaba)Pitch 5 = MIDI 65 (F4). A pontuação compara o pitch do cantor com o da nota, módulo oitava, com tolerância de 1 semitom.
O Frank Karaoke funciona com qualquer vídeo do YouTube. Não tem arquivo de referência. Não tem MIDI. Não tem anotação de melodia. Zero metadata sobre qual nota você deveria estar cantando.
Eu não sei nada de pontuação de karaokê. Não sei nada de processamento de áudio, detecção de pitch, teoria musical aplicada a software. Nada. Então pedi pro Claude Code fazer uma pesquisa extensiva sobre o assunto. O que ele trouxe de volta está documentado em docs/scoring.md no repositório, e é bastante coisa: papers acadêmicos sobre avaliação de canto (Nakano et al. 2006, Tsai & Lee 2012, Molina et al. 2013), patentes (a Yamaha tem uma de 1999, US5889224A, que detalha pontuação por MIDI com 3 faixas de tolerância), e o código fonte de projetos open source como UltraStar Deluxe, AllKaraoke, Vocaluxe e Nightingale.
A conclusão da pesquisa: sem referência por música, você precisa avaliar qualidade vocal de forma genérica. Medir como a pessoa canta, não o que ela deveria estar cantando. E como não existe uma métrica única que funcione pra todos os casos, decidimos implementar quatro modos de pontuação diferentes, cada um medindo uma dimensão diferente da qualidade vocal.
O problema do microfone do celular
Antes dos modos de pontuação, preciso explicar um problema mais fundamental que a pesquisa revelou: o microfone do celular.
Quando você canta karaokê com o celular, o microfone capta três coisas ao mesmo tempo: sua voz, a música saindo do alto-falante, e ruído ambiente da sala. Sua voz está fisicamente mais perto do microfone, então domina o sinal. Mas não o suficiente pra uma separação limpa.
Tentei várias abordagens pra isolar a voz:
Subtração espectral usando o áudio de referência do YouTube. Abandonei. O CDN do YouTube bloqueia extração direta de áudio por user-agent não-browser, e mesmo com o áudio de referência, a equalização do alto-falante, a reverberação da sala e o delay de Bluetooth tornam o sinal diferente demais do que o microfone capta. Subtração simples gera artefatos piores que nenhuma subtração.
Pré-ênfase + center clipping. Abandonei também. O center clipping destrói a forma de onda que o algoritmo YIN precisa pra autocorrelação, e a pré-ênfase amplifica ruído tanto quanto voz.
O que funciona é um filtro bandpass de 200-3500 Hz: um filtro IIR de segunda ordem (Butterworth, Q=0.707) em cascata. O high-pass em 200 Hz elimina baixo, bumbo, bass guitar do bleed do alto-falante. O low-pass em 3500 Hz elimina pratos, hi-hats, ruído de alta frequência. Os fundamentais da voz humana (85-300 Hz) e os formantes (300-3000 Hz) passam pelo filtro. Não é isolamento perfeito, mas melhora bastante a razão voz/música pra detecção de pitch.
Mas o bandpass sozinho não resolve tudo. Guitarras, sintetizadores e piano produzem sinais periódicos na mesma faixa de frequência da voz, e o YIN detecta pitch neles também. Pra lidar com isso, o app faz uma calibração adaptativa: nos primeiros 5 segundos de warmup (quando ninguém está cantando), ele coleta amostras de RMS do sinal pra estabelecer um baseline do nível do alto-falante. Durante a música, mantém esse baseline atualizado (percentil 25 dos últimos ~4 segundos de frames). Pra um frame ser pontuado, o RMS precisa estar pelo menos 1.3x acima do baseline. A voz está mais perto do microfone, então empurra o RMS acima do nível do alto-falante. A melodia instrumental fica perto do baseline e é filtrada. Nos testes, o cantor original saindo pelo alto-falante marcava uns 37 pontos com dots esparsos no trail, enquanto alguém cantando de verdade marcava ~59 com dots densos.
Outro detalhe chato: no Android, especificamente nos Samsung, o AutomaticGainControl (AGC) do DSP atenua o sinal em vez de amplificar. Nos Galaxy, habilitar AGC reduz o pico do microfone de ~0.06 pra ~0.003. Silêncio pra detecção de pitch. Então o app desabilita AGC, echo cancellation e noise suppression. Quando o pico fica abaixo de 0.01, aplica ganho por software (até 30x) pra trazer o sinal a níveis usáveis.
O algoritmo YIN
Pra detectar o pitch da voz eu uso o YIN, de Alain de Cheveigné (IRCAM-CNRS) e Hideki Kawahara (Universidade de Wakayama). É um estimador de frequência fundamental no domínio do tempo. A ideia central é a Cumulative Mean Normalized Difference Function (CMNDF), que basicamente mede o quão periódico é o sinal em cada lag, normaliza pra reduzir falsos positivos, e usa interpolação parabólica pra refinar o resultado. É leve o suficiente pra rodar em tempo real no celular, o que importa aqui.
No app, o threshold do YIN é 0.70 (ajustado pra sinais mistos de voz + música), e frames com confiança abaixo de 0.3 são descartados. Abaixo disso, provavelmente é ruído ou instrumento.
Os 4 modos de pontuação
Cada modo avalia um aspecto diferente da qualidade vocal. Todos compartilham o mesmo pipeline de áudio (bandpass → YIN → gate de confiança). A diferença é como interpretam o pitch detectado.
Pitch Match
Mede o quão limpo você sustenta as notas. Usa decaimento gaussiano baseado no desvio padrão dos valores MIDI numa janela rolante de ~15 frames. Notas firmes (desvio < 0.3 semitons) pontuam 85-100%. Voz tremendo (desvio > 2 semitons) pontua perto de zero. Bom pra músicas que você já conhece bem.
Contour
Mede a forma melódica do seu canto. Não importa qual nota exata você acerta, só a direção e o fluxo. Avalia a amplitude do pitch e movimentos melódicos (saltos > 0.5 semitom) numa janela rolante. Canto monótono pontua ~10%. Movimento melódico suave com amplitude de 2-6 semitons pontua 70-100%. Bom pra quando você está aprendendo uma música nova.
Intervals
Mede a qualidade musical dos saltos entre notas consecutivas. Tom inteiro (2 semitons) pontua mais alto. Terças e quartas pontuam bem. Saltos descontrolados de uma oitava ou mais pontuam baixo. Usa uma curva gaussiana centrada no tom inteiro. Funciona quando você está cantando numa tonalidade diferente da original.
Streak
É o Pitch Match com multiplicador combo. Cada frame consecutivo com score acima de 0.4 incrementa o contador de streak. O streak adiciona pontos bônus (até +0.4 em streak de 30+). Quebrar um streak > 5 frames empurra uma penalidade de 0.05 no EMA. Silêncio congela o streak, então pausas instrumentais não te prejudicam. O modo mais divertido pra festas.
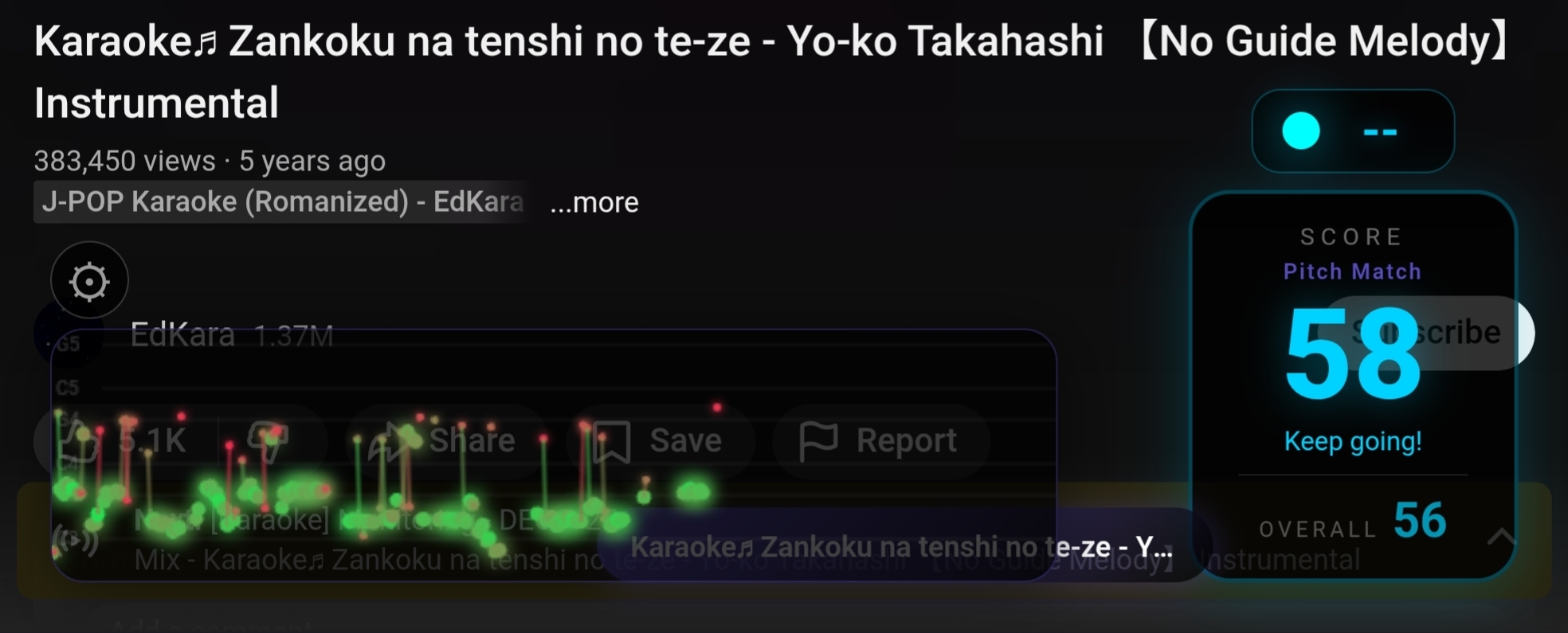
A lógica por trás desses quatro modos veio da pesquisa que o Claude fez nos papers acadêmicos. Cada um mede uma dimensão diferente: afinação, contorno melódico, fraseado e consistência. Nenhum deles sozinho é suficiente, mas juntos cobrem razoavelmente bem o que dá pra avaliar sem ter a melodia de referência da música.
O Pitch Oracle
Além dos quatro modos puramente vocais, o app tem o que eu chamo de Pitch Oracle. A ideia: em vez de avaliar sua voz isoladamente, o app baixa o áudio de referência do vídeo via youtube_explode_dart, decodifica pra PCM, roda o YIN nele, e constrói um timeline de pitch com timestamp da música inteira. Durante a pontuação, se o pitch do microfone bate com o pitch da referência naquele momento do vídeo, provavelmente é bleed do alto-falante, e é ignorado. Se difere, é sua voz, e é pontuado.
A sincronização funciona pelo currentTime do elemento de vídeo HTML5, enviado pro Dart via um listener JS de timeupdate a cada ~250ms. O oracle consulta o pitch de referência na posição exata do playback, levando em conta pause, seek e mudança de velocidade.
Na primeira vez que você toca uma música, o oracle leva uns 5-15 segundos pra baixar e analisar o áudio. Mas o timeline é salvo como JSON no cache local do app (pitch_oracle/<videoId>.json). Se você tocar a mesma música de novo, carrega instantaneamente do cache, sem request de rede. Isso também resolve o problema de rate limiting do YouTube pras músicas que você mais canta.
Com o oracle ativo, os modos mudam de comportamento. Pitch Match compara a classe de pitch do cantor contra a da referência (agnóstico à oitava, como o SingStar). Contour usa correlação cruzada entre o movimento de pitch do cantor e o da referência. Intervals compara os saltos em semitons contra os da referência.
Quando o YouTube bloqueia o download por rate limiting (acontece depois de muitos requests seguidos do mesmo IP, limpa em 15-30 minutos), o oracle falha silenciosamente e os modos voltam pra análise puramente vocal.
O caminho até aqui
O app que você vê agora passou por muita iteração antes de chegar nesse estado.
Primeiro, eu tentei fazer uma versão desktop Linux pra facilitar o debug. Faz sentido, né? Testa no desktop, itera rápido, depois porta pro celular. O problema é que o Flutter não tem backend de webview pra Linux desktop. O webview_flutter simplesmente não funciona. Tentei o webview_cef, que é baseado no Chromium Embedded Framework. O CEF spawna seu próprio processo de GPU, e no Hyprland (compositor Wayland baseado no wlroots) isso conflita com o pipeline de renderização do compositor. No meu setup com NVIDIA, a sessão inteira do Hyprland congelou. Tela travada, sem resposta a teclado, tive que matar pelo TTY. Fora que o CEF exige download de um binário de ~200MB na primeira build. Desisti do CEF e escrevi com o Claude uma bridge nativa em C++ usando WebKitGTK com method channels do Flutter. Funcionou, mas cada peculiaridade do YouTube exigia código separado pro Linux e pro Android. O just_audio também não tem implementação pra Linux desktop. No fim a versão Linux virou peso morto. Deletei ~1.500 linhas de código Linux-específico e foquei só no Android.
Depois veio a saga do microfone no Samsung. No meu Galaxy Z Fold, o microfone captava um sinal absurdamente baixo. Pico de ~0.005, basicamente silêncio pro detector de pitch. Fiquei umas duas horas tentando entender. Baixei thresholds, aumentei ganho por software até 50x, desabilitei preprocessadores de áudio. Nada funcionava direito. Até que descobri o problema real: o AutomaticGainControl do Android. O nome diz “controle automático de ganho”, o que sugere que ele amplifica sinais fracos. Na implementação DSP dos Samsung, ele faz o oposto. Ele atenua o sinal pra um nível de referência baixo, otimizado pra chamadas de voz. Com AGC ligado, o pico caía de ~0.06 pra ~0.003. Desligar o AGC resolveu. Mas aí o pacote audio_session religava o AGC por baixo dos panos. Removi ele também. Foram três rodadas de fix, cada uma achando mais uma camada do problema.
E a pontuação. A pontuação levou mais tempo que todo o resto junto. A primeira implementação usava média cumulativa, que deixava a nota travada num valor e não respondia ao canto em tempo real. Troquei pra janela rolante. Aí a nota ficava presa em ~50% por causa de um bug no peso da pontuação primária. Consertei, e ela passou a começar em 70% mesmo sem ninguém cantando. Consertei de novo. O modo Streak não resetava direito no silêncio. O chromatic snap dava nota alta pra qualquer coisa. O histórico de pitch não era limpo nos gaps de silêncio e os modos ficavam estagnados. Cada bug corrigido revelava outro. Foram mais de 25 commits só ajustando a pontuação, do primeiro protótipo até o estado atual.
O resultado não é perfeito. Eu sei. Mas funciona o suficiente pra ser divertido, que era o objetivo desde o começo.
Configurações
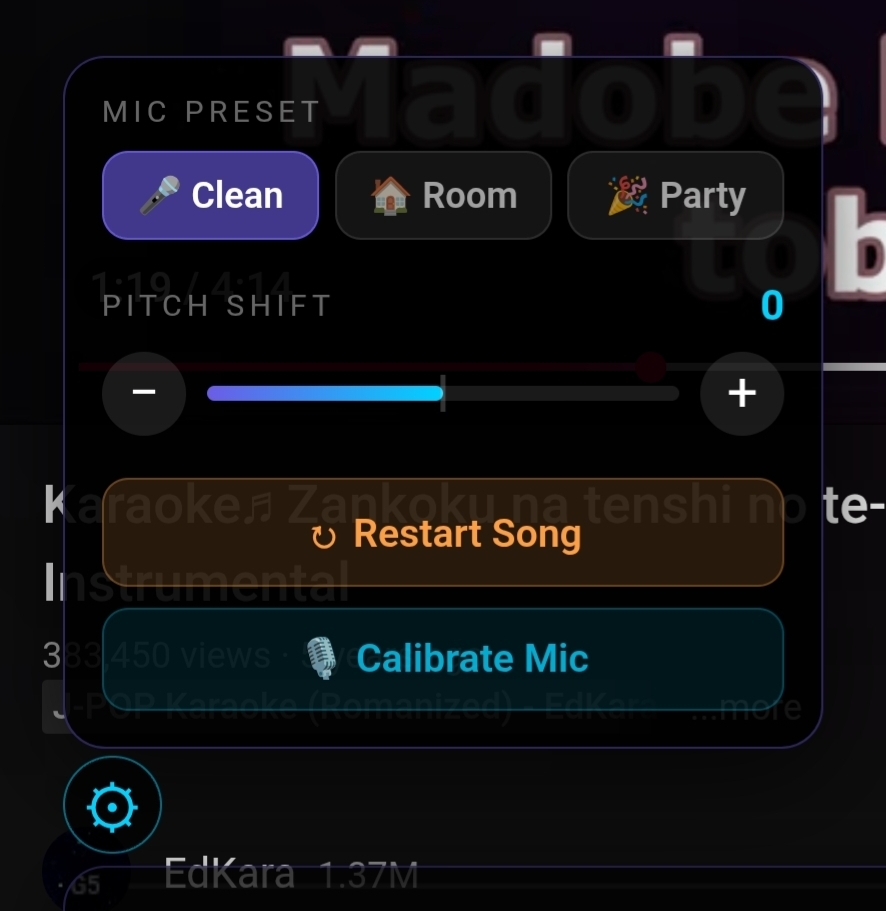
O painel de configurações fica no ícone de engrenagem do overlay. Tem três presets de microfone pra diferentes ambientes (microfone externo limpo, sala normal, festa barulhenta), cada um ajustando thresholds de confiança e amplitude. Tem pitch shift pra quando a música é aguda demais pra sua extensão vocal. O ajuste muda tanto o áudio do vídeo quanto a pontuação ao mesmo tempo: usa o playbackRate do elemento HTML5 com preservesPitch=false, então +2 semitons acelera o áudio pra 1.12x (pitch sobe) e -2 semitons desacelera pra 0.89x (pitch desce). A pontuação compensa o offset, então você canta na sua faixa confortável e o sistema avalia corretamente. Tem calibração de microfone, um processo de 3 segundos que mede o ruído da sala e adapta os thresholds. E tem restart pra zerar a pontuação sem recarregar o vídeo.
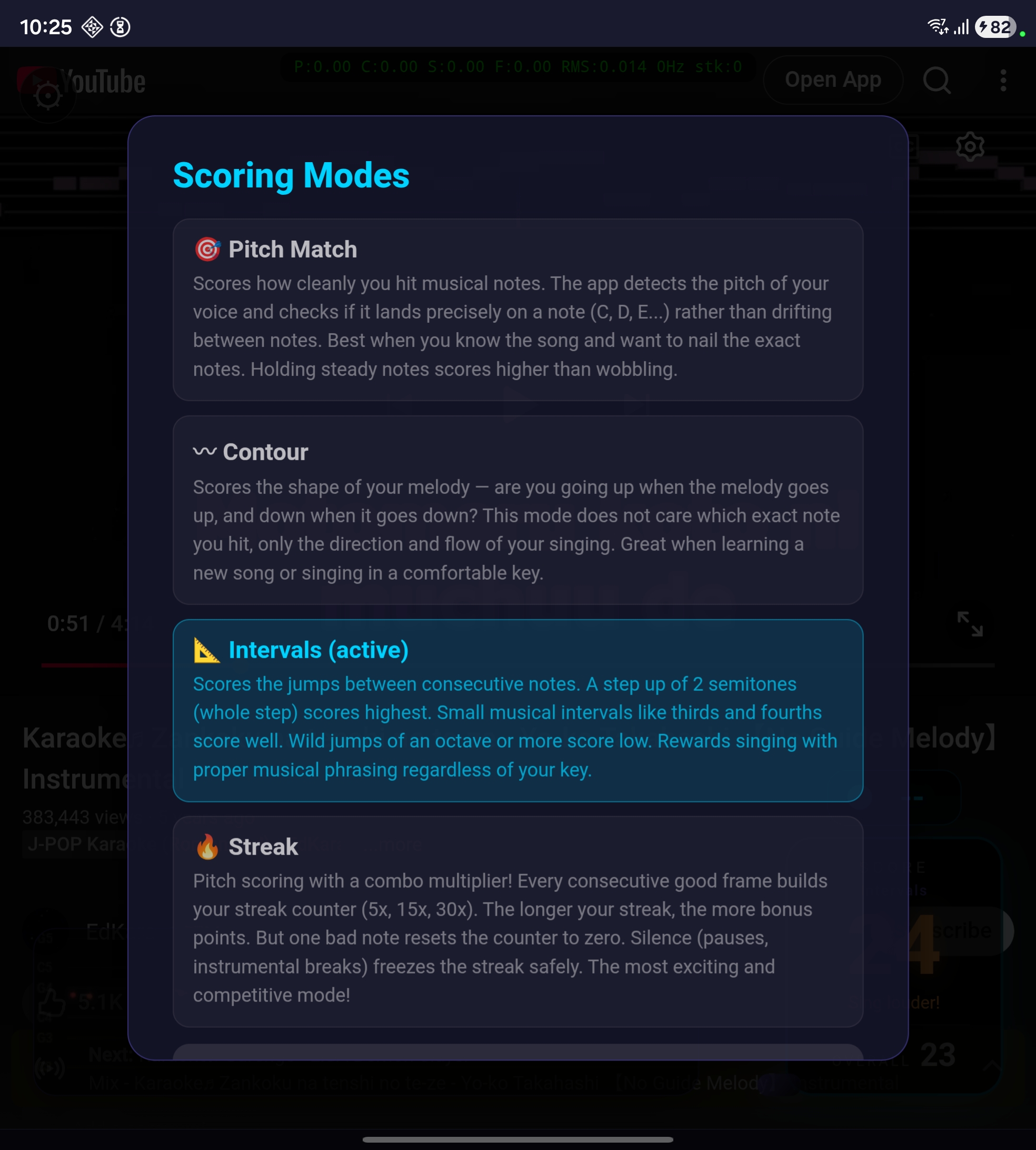
Pra trocar de modo de pontuação, toque na caixa de score durante a reprodução.
Fluxo de uso
- Abra o app. O YouTube carrega dentro do app com o logo do Frank Karaoke.
- Busque um vídeo de karaokê. Qualquer vídeo funciona, mas faixas instrumentais com letra na tela dão melhores resultados.
- O vídeo pausa brevemente pra inicializar o microfone, baixar dados da música pro pitch oracle, e preparar o overlay. Na primeira vez com uma música nova isso leva uns 5-15 segundos. Se você já tocou essa música antes, carrega do cache instantaneamente.
- Cante. O score “live” reflete sua performance atual (média exponencial com alpha 0.15, resposta em ~1 segundo). O score “overall” é a média cumulativa da música inteira.
- Quando o vídeo pausa, a pontuação pausa junto (pra não pontuar ruído ambiente). Se fizer seek, o score zera e tem 5 segundos de warmup.
Como instalar
O app ainda não está na Play Store, estou esperando o Google verificar minha identidade de desenvolvedor. Deve aparecer lá nos próximos dias. Enquanto isso, é um projeto aberto e dá pra instalar direto.
O jeito mais fácil é baixar o APK assinado direto da página de releases do GitHub. No celular ou tablet Android, baixe o FrankKaraoke-0.2.0-android.apk, abra e toque em Instalar. Se o Android reclamar de “fontes desconhecidas”, habilite em Configurações > Segurança pro seu navegador. Na primeira execução o app pede permissão de microfone. Depois vá nas configurações (ícone de engrenagem) e calibre o microfone antes de cantar, são 3 segundos.
Se você quer compilar do fonte ou contribuir, o repositório está no GitHub. Precisa de Flutter SDK 3.10+, Android SDK API 24+, e um dispositivo físico pra testar microfone (emulador não dá resultados representativos).
git clone https://github.com/akitaonrails/frank_karaoke.git
cd frank_karaoke
flutter pub get
flutter run -d <device_id>O README tem o resto.
Stack: Flutter + Riverpod pra state management, webview_flutter pro YouTube, youtube_explode_dart pra extração de áudio, record pra captura PCM do microfone, audio_decoder pra decodificação de referência via Android MediaCodec, e o algoritmo YIN implementado em Dart puro.
A documentação técnica do sistema de pontuação está em docs/scoring.md no repositório. Cobre como SingStar, Joysound e DAM funcionam, os papers acadêmicos, a arquitetura do pitch oracle, os problemas de isolamento de voz no Android, e o roadmap.
A pontuação é experimental
Preciso ser direto: o sistema de pontuação é experimental. Sem arquivos de referência por música, a avaliação é aproximada. O app mede se você está afinado, se segue um contorno melódico, se seus intervalos são musicais, se é consistente. Mas não te diz se você está cantando a melodia certa desta música específica (a menos que o pitch oracle consiga baixar o áudio, e nem sempre consegue).
Se você tem experiência com processamento de áudio, detecção de pitch, ou avaliação musical, o repositório está aberto e a documentação de pesquisa em docs/scoring.md detalha o que foi tentado, o que funciona e o que não funciona. Em particular: calibração dos thresholds dos modos, melhorias no isolamento de voz, e integração com o UltraSinger (que gera arquivos de referência a partir de músicas usando Demucs + basic-pitch + WhisperX) são áreas onde contribuição de quem entende do assunto faria diferença. Apreciamos qualquer ajuda de especialistas na calibração desses sistemas.
Ah, e o nome. Frank Karaoke. É uma homenagem ao Sinatra. Quem mais?
Projeto no GitHub: github.com/akitaonrails/frank_karaoke