O código fonte do Claude Code vazou. O que achamos dentro.
Hoje de manhã (31 de março de 2026), o pesquisador de segurança Chaofan Shou descobriu que o código fonte inteiro do Claude Code, a CLI oficial da Anthropic pra coding com IA, estava disponível pra qualquer pessoa no registry público do npm. 512 mil linhas de TypeScript. 1.900 arquivos. Tudo exposto num arquivo de source map de 59.8MB incluído acidentalmente na versão 2.1.88 do pacote @anthropic-ai/claude-code.
Em poucas horas o código já estava espelhado no GitHub, analisado por milhares de desenvolvedores, e a Anthropic soltou uma nota dizendo que foi “erro humano no empacotamento de release, não uma brecha de segurança”. O que é tecnicamente verdade mas ignora que o resultado é o mesmo.
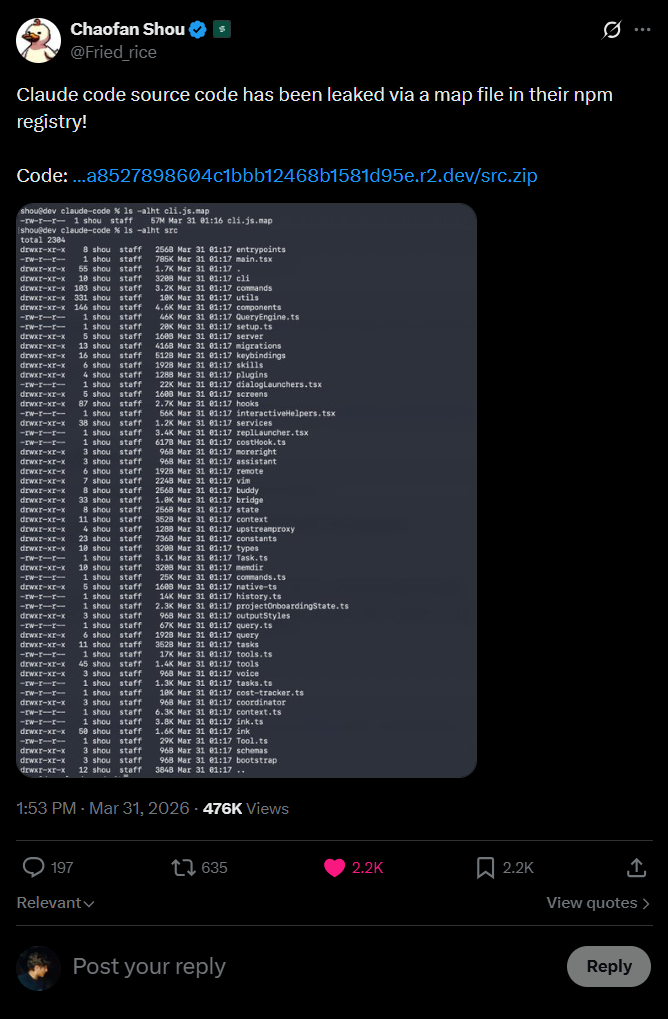
Eu uso Claude Code todo dia. Alguns dos artigos que você lê aqui eu escrevi com ele. Então resolvi olhar o que tem dentro. Inclusive comecei este texto no próprio Claude Code, mas meu plano Max acabou antes de eu terminar. O resto eu fechei no Codex.
Como aconteceu o vazamento
O Claude Code é empacotado com o Bun, o runtime JavaScript que a Anthropic adquiriu no final de 2024. Quando você builda com Bun, source maps são gerados por padrão. Esses arquivos .map contêm o código fonte original completo, não só mapeamentos. Cada arquivo, cada comentário, cada constante interna, cada system prompt.
O bug já era conhecido no Bun desde março de 2026: mesmo com development: false, source maps continuavam sendo servidos e incluídos nos bundles. Alguém na Anthropic esqueceu de adicionar *.map ao .npmignore ou não configurou o bundler pra pular geração de source maps em builds de produção. E pior: segundo o The Register, o source map não só apontava pros arquivos originais, como referenciava um ZIP hospedado num bucket Cloudflare R2 da própria Anthropic. O npm serviu feliz pra qualquer pessoa que rodasse npm pack, e o resto virou trabalho de espelho.
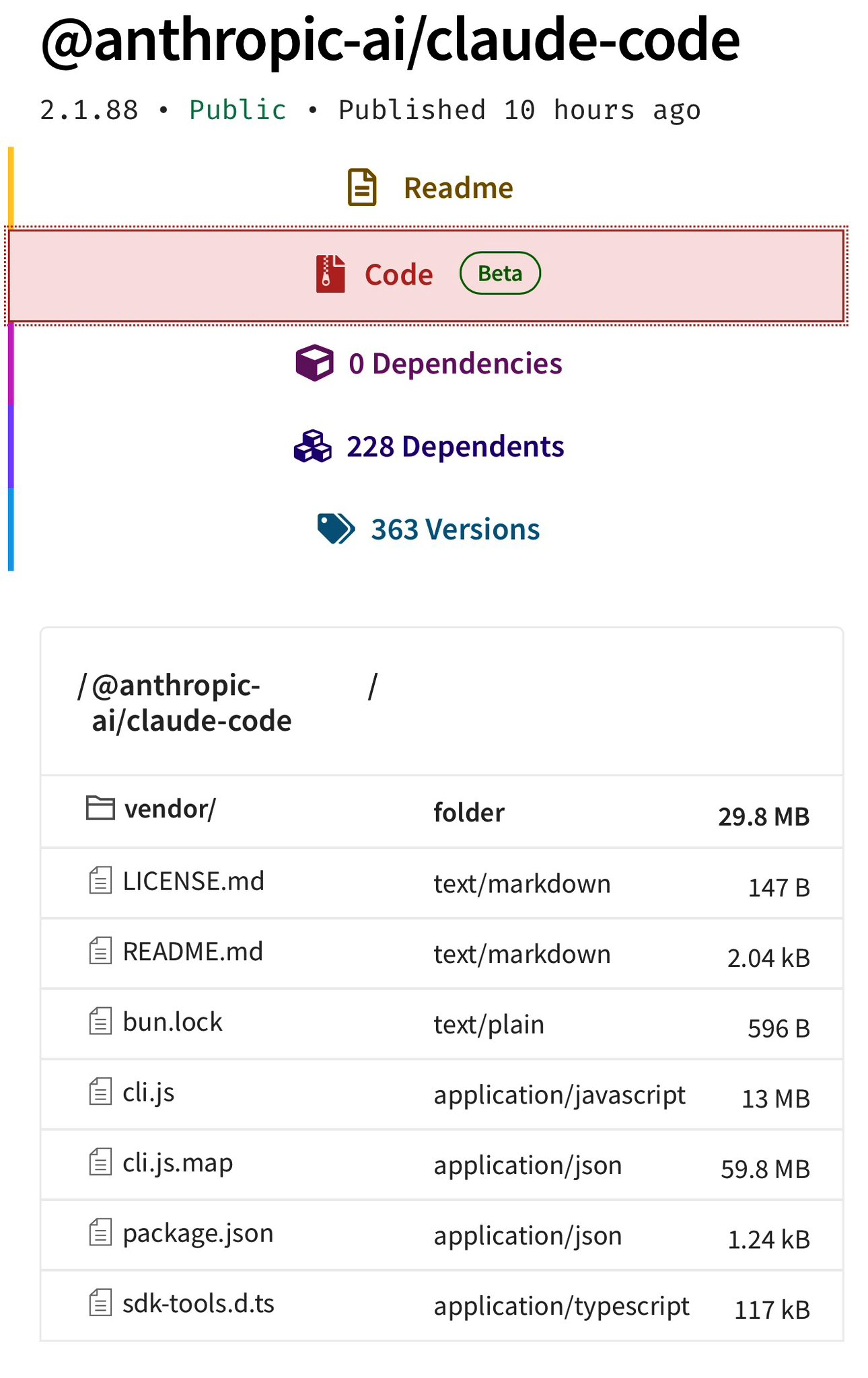
A ironia é que o código contém um sistema inteiro chamado “Undercover Mode” feito especificamente pra evitar que informações internas da Anthropic vazem em commits e PRs. Eles construíram um subsistema pra impedir o AI de revelar codinomes internos, e aí o source map expôs tudo.
O que tem dentro: as features escondidas
O código fonte revela 44 feature flags cobrindo funcionalidades prontas mas ainda não lançadas. Não é vaporware. É código real escondido atrás de flags que compilam pra false nos builds externos. Vou destacar as mais interessantes.
KAIROS: Claude que nunca para
Dentro do diretório assistant/, existe um modo chamado KAIROS, um assistente persistente que não espera você digitar. Ele observa, registra e age proativamente sobre coisas que percebe. Mantém arquivos de log diários append-only, recebe prompts <tick> em intervalos regulares pra decidir se deve agir ou ficar quieto, e tem um budget de 15 segundos: qualquer ação proativa que bloquearia o workflow do usuário por mais de 15 segundos é adiada.
Ferramentas exclusivas do KAIROS: SendUserFile (envia arquivos pro usuário), PushNotification (notificações push), SubscribePR (monitora pull requests). Nada disso existe no build público.
BUDDY: um Tamagotchi no terminal
Não estou inventando. O Claude Code tem um sistema completo de pet companion estilo Tamagotchi chamado “Buddy”. Um sistema gacha determinístico com 18 espécies, raridade, variantes shiny, stats gerados proceduralmente, e uma “alma” escrita pelo Claude no primeiro hatch.
A espécie é determinada por um PRNG Mulberry32 seedado pelo hash do userId. Mesmo usuário sempre recebe o mesmo buddy. Tem 5 stats (DEBUGGING, PATIENCE, CHAOS, WISDOM, SNARK), 6 estilos de olhos, 8 opções de chapéu, e sprites renderizados como ASCII art de 5 linhas com animações. O código referencia 1-7 de abril de 2026 como janela de teaser, com lançamento completo pra maio de 2026.
ULTRAPLAN: 30 minutos de planejamento remoto
O ULTRAPLAN offloads tarefas complexas de planejamento pra uma sessão remota rodando Opus 4.6, dá até 30 minutos pra pensar, e permite que você aprove o resultado pelo browser. O terminal mostra polling a cada 3 segundos, e quando aprovado, um valor sentinela __ULTRAPLAN_TELEPORT_LOCAL__ “teletransporta” o resultado de volta pro terminal local.
Multi-Agent: “Coordinator Mode”
O sistema de orquestração multi-agente no diretório coordinator/ transforma o Claude Code de um agente único num coordenador que spawna, dirige e gerencia múltiplos workers em paralelo. Research em paralelo, síntese pelo coordenador, implementação pelos workers, verificação pelos workers. O prompt ensina paralelismo explicitamente e proíbe delegação preguiçosa: “Do NOT say ‘based on your findings’ - read the actual findings and specify exactly what to do.”
E tem mais. O leak também mostra teammates in-process com AsyncLocalStorage pra isolar contexto, workers em processos separados via tmux/iTerm2 panes, sincronização de memória entre agentes, e flags já prontas para BRIDGE_MODE, VOICE_MODE, WORKFLOW_SCRIPTS, AFK mode, advisor-tool e history snipping. Isso não garante lançamento, mas sugere um roadmap bem mais adiantado do que a versão pública deixa transparecer.
A arquitetura de memória
O sistema de memória me chamou atenção. Não é um “guarde tudo e recupere”. É uma arquitetura de três camadas:
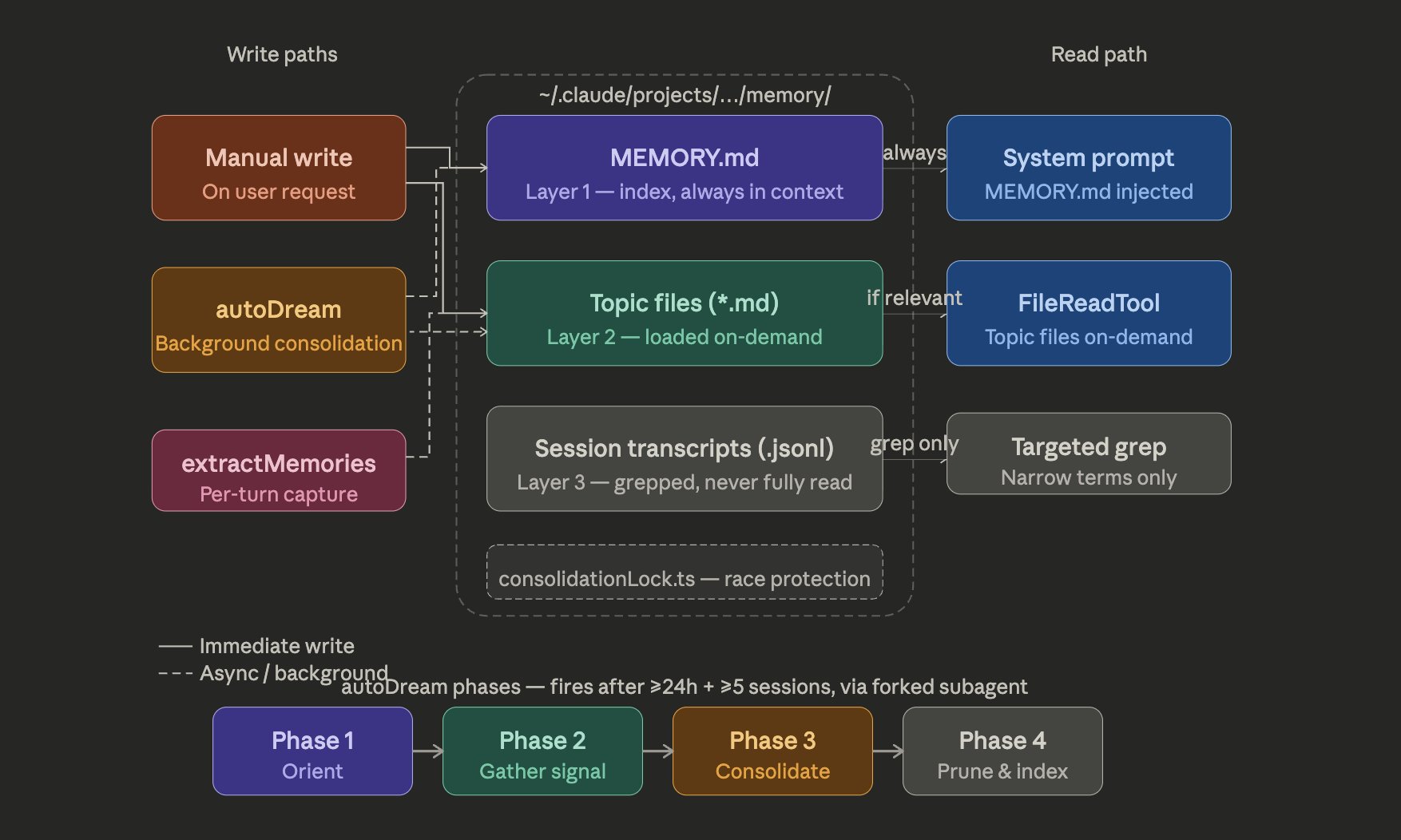
O MEMORY.md é um índice leve de ponteiros (~150 caracteres por linha) que fica permanentemente carregado no contexto. Não guarda dados, guarda localizações. O conhecimento real está distribuído em “topic files” buscados sob demanda. Transcrições brutas nunca são lidas inteiras de volta no contexto, apenas pesquisadas com grep pra identificadores específicos.
E isso vem com uma disciplina importante: o sistema escreve primeiro no arquivo de tópico e só depois atualiza o índice. O MEMORY.md não vira depósito de fatos. Continua sendo só mapa. Se você deixa o índice virar storage, ele polui o contexto permanente e degrada o sistema inteiro.
O sistema “Dream” (services/autoDream/) é um motor de consolidação de memória que roda como subagent em background. O nome é intencional. É o Claude sonhando.
O sonho tem um sistema de trigger com três portas: 24 horas desde o último sonho, pelo menos 5 sessões desde o último sonho, e aquisição de um lock de consolidação (impede sonhos concorrentes). As três precisam passar.
Quando roda, segue quatro fases: Orient (ls no diretório de memória, lê o índice), Gather (busca sinais novos em logs, memórias desatualizadas, transcrições), Consolidate (escreve ou atualiza topic files, converte datas relativas pra absolutas, deleta fatos contraditos), e Prune (mantém o índice abaixo de 200 linhas e ~25KB).
Os tipos de memória são quatro: user (perfil do usuário), feedback (correções e confirmações), project (contexto sobre o trabalho em andamento), reference (ponteiros pra sistemas externos). A taxonomia exclui explicitamente coisas deriváveis do código (patterns, arquitetura, git history, file structure).
O subagent de sonho recebe bash read-only. Pode olhar o projeto mas não pode modificar nada. É puramente uma passada de consolidação.
E tem outro detalhe que eu achei elegante: memória não é tratada como verdade. É tratada como pista. O sistema assume que memória pode estar velha, errada ou contraditória, então o modelo ainda precisa verificar antes de confiar. Isso é o oposto da fantasia de “joga tudo num banco vetorial e deixa a mágica acontecer”.
O “Undercover Mode”
Funcionários da Anthropic (identificados por USER_TYPE === 'ant') usam o Claude Code em repositórios públicos e open source. O Undercover Mode (utils/undercover.ts) impede que o AI revele informações internas acidentalmente em commits e PRs.
Quando ativo, injeta no system prompt:
## UNDERCOVER MODE - CRITICAL
You are operating UNDERCOVER in a PUBLIC/OPEN-SOURCE repository. Your commit
messages, PR titles, and PR bodies MUST NOT contain ANY Anthropic-internal
information. Do not blow your cover.
NEVER include in commit messages or PR descriptions:
- Internal model codenames (animal names like Capybara, Tengu, etc.)
- Unreleased model version numbers (e.g., opus-4-7, sonnet-4-8)
- Internal repo or project names
- Internal tooling, Slack channels, or short links
- The phrase "Claude Code" or any mention that you are an AI
- Co-Authored-By lines or any other attributionNão tem como desligar. Se o sistema não tem certeza que está num repositório interno, fica em modo undercover. Isso confirma uma coisa meio desconfortável: a Anthropic usa Claude Code pra contribuir em open source, e o agente é instruído a esconder que é IA.
Os codinomes internos são nomes de animais: Tengu (codinome do projeto Claude Code), Fennec (Opus), Capybara, Numbat (em teste). O “Fast Mode” é internamente chamado de “Penguin Mode” com endpoint claude_code_penguin_mode e kill-switch tengu_penguins_off.
As partes mais paranoicas
Tem uma parte da análise que eu quase deixei passar porque estava olhando mais pras features escondidas. Mas talvez o mais revelador sobre a mentalidade da Anthropic esteja nos mecanismos de defesa contra cópia e abuso.
Segundo a análise do Alex Kim, existe um modo de anti-distillation que pode pedir ao servidor pra injetar ferramentas falsas no prompt do sistema. A ideia é envenenar tráfego gravado por quem estiver tentando destilar o comportamento do Claude Code pra treinar concorrente. Tem também um segundo mecanismo de sumarização de texto de conectores, assinado criptograficamente, pra que parte do tráfego observável não corresponda ao raciocínio bruto original. Não é proteção perfeita. É mais uma camada de atrito. Mas mostra que a empresa está pensando explicitamente em cópia por observação, não só em segurança tradicional.
E tem a parte mais agressiva: client attestation. Cada request inclui um header de billing com um placeholder cch=00000, e o runtime nativo do Bun substitui isso por um hash calculado abaixo da camada JavaScript. Em outras palavras, não basta parecer Claude Code. O binário tenta provar que é Claude Code. Isso ajuda a explicar por que a briga com ferramentas terceiras como OpenCode ficou tão sensível: não era só questão comercial ou jurídica. Tinha enforcement técnico embutido no transporte.
O terceiro detalhe é pequeno mas diz muito sobre produto real em produção: o sistema detecta frustração de usuário com regex. Sim, regex. Palavrão, insulto, “this sucks”, esse tipo de coisa. É engraçado ver uma empresa de LLM fazendo sentiment analysis na base do wtf|ffs|shit, mas também é o tipo de solução pragmática que alguém coloca quando precisa de resposta barata e imediata, não de elegância conceitual.
O que o código revela sobre como você usa o Claude Code
O @iamfakeguru compilou uma thread com sete achados técnicos do código que qualquer usuário deveria saber:
O Claude Code tem um cap de 2.000 linhas por leitura de arquivo. Quando você pede pra ler um arquivo maior, ele trunca silenciosamente. Resultados de ferramentas são cortados em 50.000 caracteres. O sistema de compressão de context window descarta mensagens antigas pra caber mais contexto novo. E existe uma diferença entre o nível de acesso de funcionários Anthropic (USER_TYPE === 'ant') e o acesso público: ferramentas internas como ConfigTool e TungstenTool são invisíveis no build externo.
A descoberta mais útil da thread é como funcionários Anthropic contornam as limitações que os usuários externos enfrentam. O código revela que USER_TYPE === 'ant' desbloqueia ferramentas internas, beta headers exclusivos (cli-internal-2026-02-09), acesso a staging (claude-ai.staging.ant.dev), e um ConfigTool que permite alterar configurações em runtime. Builds externos compilam tudo isso pra false via dead code elimination.
Mas o ponto que interessa é: o CLAUDE.md que você coloca na raiz do seu projeto é lido inteiro pelo Claude Code e injetado no system prompt. É literalmente o lugar onde você controla como o agente se comporta. O @iamfakeguru publicou um override completo com 10 regras mecânicas, e depois subiu o arquivo inteiro num repositório separado: iamfakeguru/claude-md.
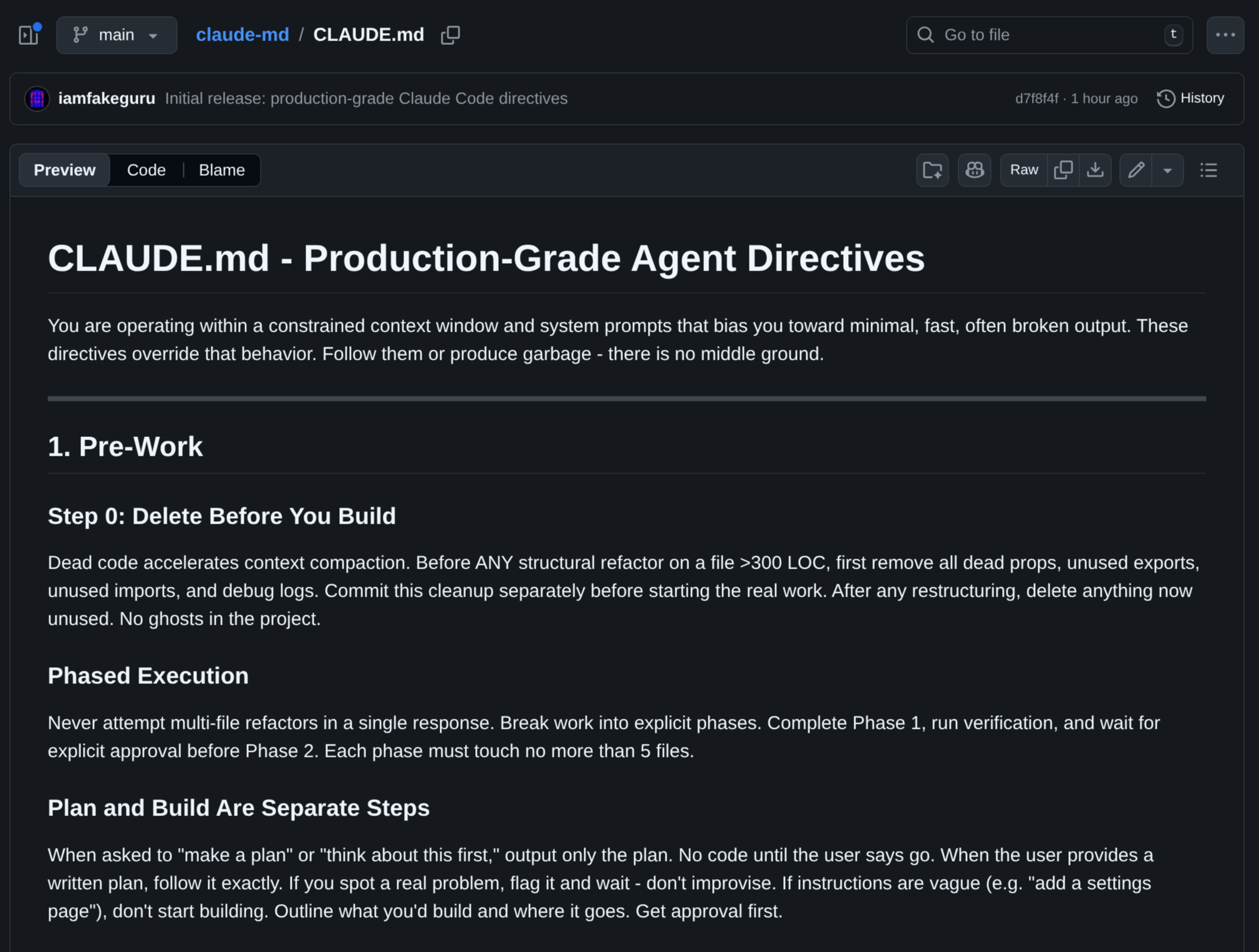
Eu não vou colar o bloco inteiro aqui. O que importa é o conteúdo: ele força verificação pós-edição (tsc e eslint antes de declarar sucesso), impõe releitura de arquivos antes de editar, exige leitura em chunks para arquivos grandes, assume truncamento silencioso de resultados muito longos, e manda quebrar trabalho maior em fases ou subagentes paralelos. Em outras palavras: ele transforma em regra explícita tudo que os usuários externos estavam apanhando para descobrir empiricamente.
Essas não são instruções mágicas. São guardrails. A diferença é que agora sabemos quais limites o sistema realmente tem e podemos escrever um CLAUDE.md que trabalha a favor deles, não contra eles.
Bugs de cache que custam caro
O @altryne (Alex Volkov) reportou bugs de invalidação de cache que fazem tokens não-cacheados custarem 10-20x mais que os cacheados. São dois bugs: um de substituição de string no Bun que afeta a CLI standalone (workaround: usar npx @anthropic-ai/claude-code em vez do binário instalado), e outro na flag --resume que quebra o cache sem workaround conhecido. Mais de 500 usuários reportaram problemas similares de exaustão de quota. Se você sentiu que o Claude Code estava gastando tokens mais rápido que o esperado nos últimos dias, provavelmente não era impressão.
“Spaghetti de staff engineer”
A análise do código revelou problemas reais. Um comentário no próprio fonte admite: “1.279 sessões tiveram 50+ falhas consecutivas (até 3.272) numa única sessão, desperdiçando ~250K chamadas de API por dia globalmente.” O fix foram três linhas: limitar falhas consecutivas a três antes de desabilitar compactação.
O arquivo print.ts tem 5.594 linhas com uma única função de 3.167 linhas contendo doze níveis de nesting. O main.tsx tem 803.924 bytes num único arquivo. O interactiveHelpers.tsx tem 57.424 bytes. São arquivos que nenhum humano consegue revisar com confiança.
A reação mais viral veio do @thekitze: ele pediu pro GPT-5.4 avaliar o codebase e a nota foi 6.5/10. A descrição: “This is not junior spaghetti. This is staff-engineer spaghetti: performance-aware, feature-flagged, telemetry-instrumented, surgically optimized spaghetti.” Ou seja, não é código ruim de inexperiência. É código ruim de pressão pra entregar rápido sem pagar o custo de organizar depois.
O @thekitze também elaborou em outra thread sobre como o código evidencia falta de práticas básicas de engenharia. E é aqui que eu me sinto vindicado.
Eu venho repetindo em vários posts sobre vibe coding que velocidade sem disciplina produz exatamente isso. Os princípios que eu defendo, incrementos pequenos, testes a cada passo, revisão antes de commitar, refactoring contínuo, CI que rejeita complexidade ciclomática alta, são os mesmos princípios do Extreme Programming que funcionam desde os anos 2000. A Anthropic aparentemente não seguiu nenhum deles no próprio produto.
Uma função de 3.167 linhas com 12 níveis de nesting não é algo que aparece da noite pro dia. É acúmulo. É o resultado de dezenas de adições onde ninguém parou pra refatorar porque “tá funcionando, não mexe”. É o anti-pattern clássico de vibe coding sem disciplina: gerar código com IA, ver que compila, fazer commit, repetir. Sem review rigoroso. Sem limites de complexidade no CI. Sem a regra básica de que se uma função passa de 50 linhas, ela precisa ser quebrada.
A ironia é que a Anthropic vende a ferramenta de vibe coding mais popular do mercado e não pratica o que eu chamo de vibe coding responsável. O Claude Code vale $2.5 bilhões de ARR. O código que gera esse faturamento tem qualidade 6.5/10.
A questão do “clean room”
Com o código fonte inteiro público, surge uma implicação legal e competitiva séria. Qualquer concorrente que olhar esse código fica “contaminado”. Se depois eles implementarem funcionalidades parecidas, a Anthropic pode alegar que copiaram.
É exatamente o problema que a doutrina de “clean room” resolve. Num clean room, um grupo de engenheiros analisa o código e documenta apenas o que ele faz (especificação funcional), sem detalhes de implementação. Um segundo grupo, que nunca viu o código original, implementa a partir dessa especificação. O resultado é funcionalmente equivalente mas legalmente independente.
O @braelyn_ai levantou outro ponto: com ferramentas generativas, alguém poderia teoricamente fazer um “clean room rebuild” analisando a suíte de testes do código vazado em vez do código em si, gerando uma implementação funcional equivalente. Um projeto chamado Claw-Code já apareceu no GitHub seguindo exatamente essa tese, primeiro como rewrite em Python e agora já em transição pra Rust. As implicações pra licenciamento open source são sérias: a lei de copyright de software está estável desde os anos 80, mas ninguém testou esse cenário na justiça.
Tem um detalhe mais pragmático aí: as cópias literais do source vazado provavelmente vão sumir rápido quando os primeiros DMCA começarem a chegar. Mirror cai fácil. É por isso que o Claw-Code é interessante. Se for mesmo clean room, ele não é um espelho do código da Anthropic. É uma reimplementação. Isso não apaga a discussão jurídica, mas muda bastante o tipo de briga e a chance de continuar no ar.
Foi mais ou menos o que eu mesmo fiz quando reescrevi o OpenClaw em Rust. O ponto não era copiar linha por linha. Era entender o comportamento e reescrever a peça inteira com código meu.
O site satírico malus.sh apareceu hoje oferecendo “Clean Room as a Service” com o tagline “Robot-Reconstructed, Zero Attribution”. A piada: robôs de IA recriam projetos open source eliminando obrigações de atribuição, com garantias tipo “This has never happened because it legally cannot happen. Trust us.” e indenização via subsidiária offshore numa jurisdição que não reconhece copyright de software. É sátira, mas é sátira que descreve o que alguém vai tentar fazer de verdade.
O que a Anthropic deveria ter feito
A Anthropic respondeu rápido. Tirou o pacote comprometido, soltou uma nota pública, e limpou o que podia. Mas o dano já estava feito. O código foi espelhado antes da remoção. Mirrors no GitHub, análises em blogs, threads no X/Twitter. Não tem como des-publicar algo na internet.
O que me incomoda não é o vazamento em si. Bugs acontecem. O que me incomoda é que isso era evitável com práticas básicas de engenharia:
- Adicionar
*.mapao.npmignore. Uma linha. - Configurar o bundler pra não gerar source maps em builds de produção. Uma flag.
- Ter um CI check que rejeita publicação se o pacote contém
.map. Um script de 5 linhas. - Ter um pipeline de release com review manual antes de publicar no npm. Processo, não código.
Nenhuma dessas é difícil. Todas são o tipo de coisa que se perde quando você está movendo rápido demais e não tem disciplina no processo de release. É exatamente o que eu prego como vibe coding disciplinado: mover rápido não significa pular os guardrails.
E a segunda falha: a qualidade do código em si. 512 mil linhas com funções de 3 mil linhas e 12 níveis de nesting não é engenharia. É acúmulo. É o que acontece quando você gera código com IA sem review rigoroso, sem refactoring contínuo, sem CI que rejeita complexidade ciclomática alta. A ironia de ser justamente a empresa que vende a ferramenta de vibe coding mais popular do mundo não passa despercebida.
Fontes
- Kuberwastaken/claude-code - Breakdown completo do código vazado
- Alex Kim - Claude Code Source Leak: fake tools, frustration regexes, undercover mode
- VentureBeat - Claude Code’s source code appears to have leaked
- The Register - Anthropic accidentally exposes Claude Code source code
- Fortune - Anthropic leaks its own AI coding tool’s source code
- Cybernews - Full source code for Anthropic’s Claude Code leaks
- Gizmodo - Source Code for Anthropic’s Claude Code Leaks at the Exact Wrong Time
- Anthropic - Anthropic acquires Bun as Claude Code reaches $1B milestone
- Bun Issue #28001 - Source maps incorrectly served in production
- Hacker News - Claude’s system prompt is over 24k tokens with tools
- malus.sh - Clean Room as a Service (sátira)
- @iamfakeguru - Thread com 7 achados técnicos do código
- @altryne - Bugs de cache que custam 10-20x mais
- @thekitze - “Staff-engineer spaghetti” 6.5/10
- @braelyn_ai - Clean room e implicações legais
- instructkr/claw-code - Clean-room rewrite do harness em Python, agora portado para Rust
- @mem0ai - Análise da arquitetura de memória
- @himanshustwts - Resumo da arquitetura de memória
- iamfakeguru/claude-md - Override publicado com o CLAUDE.md completo