Eu Fiz um Sistema de Data Mining pra Minha Namorada Influencer — Dicas e Truques
Minha namorada é influencer de games, anime, cosplay e cultura pop. Faz entrevistas, cobre convenções, produz conteúdo pra múltiplas plataformas, negocia com patrocinadores. É uma operação profissional de uma pessoa com uma equipe enxuta. E como toda operação profissional, ela precisa de dados.
O problema é que coletar dados de redes sociais é trabalho braçal. Abrir Instagram, YouTube, X, olhar números, comparar com concorrentes, checar calendário de eventos, monitorar patrocinadores, ler comentários, calcular engajamento, decidir preço de publi. Tudo manual, tudo repetitivo, tudo consumindo tempo que deveria ir pra criação de conteúdo.
Fiz o que qualquer programador namorado faria: construí um sistema de data mining completo, com coleta automatizada, análise via LLM, e um chatbot no Discord onde ela conversa com os dados em linguagem natural.
Este artigo não é sobre o código em si (o projeto não será open source). É sobre o processo de construção, as decisões que só aparecem depois que você começa, os truques técnicos que salvaram o projeto, e por que um documento de desejos da sua usuária vale mais que qualquer spec funcional.
Comece Pelo Desejo, Não Pela Arquitetura
A primeira coisa que fiz foi sentar com ela e pedir que falasse livremente o que queria. Sem linguagem técnica, sem formulário, sem user stories. As próprias palavras dela. Gravei num documento IDEA.md que virou o norte do projeto inteiro.
O que saiu dali:
“Maior dificuldade hoje é saber qual tipo de conteúdo criar que pode dar muito certo e por que deram certo, o que fez dar o resultado que deu. Tem que ler comentários dos vídeos pra entender motivos gerais.”
“Quanto deveria/poderia cobrar por uma publicidade, baseado na pesquisa de engajamento, concorrência, patrocinadores, eventos.”
“Como fazer uma publicidade que não parece publicidade, conteúdo pago que traz engajamento sem parecer só propaganda de venda.”
Ela não pediu um dashboard. Não pediu gráficos. Não pediu relatórios em PDF. Pediu respostas pra problemas concretos do dia a dia dela. Isso mudou completamente a forma como eu abordei a arquitetura.
Se eu tivesse começado pela spec técnica, teria construído uma plataforma de analytics com charts bonitos e exports em CSV. O sistema que ela realmente precisava era algo mais parecido com uma assistente que conhece os dados e responde perguntas em português.
O IDEA.md também listava concorrentes e patrocinadores iniciais. Marcas com as quais ela poderia trabalhar (restaurantes temáticos, lojas de figures, Crunchyroll, Piticas, Fanlab). Perfis de referência no Instagram. Tudo isso virou dados de seed. O documento não era um spec — era uma conversa que virou requisito orgânico.
58 Commits em 3 Dias
O projeto foi construído em 3 dias. Não 3 semanas, não 3 meses. 58 commits, 3 fases distintas:
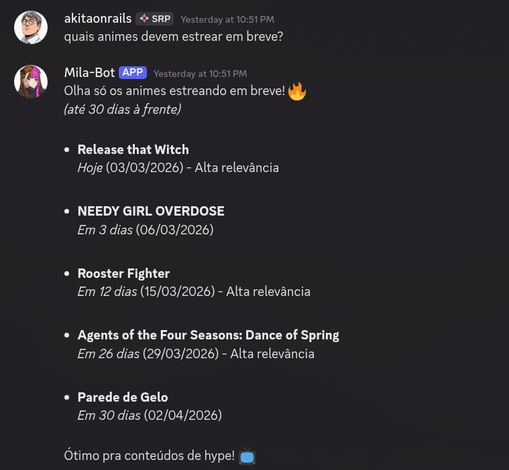
Dia 1 — O Motor de Dados. 12 commits. Scaffold Rails 8, modelos, coletores pra YouTube/Instagram/X, integração com LLM. Pipeline de discovery pra encontrar novos perfis automaticamente. Scoring de performance por post. Análise de sentimento de comentários via Claude. No final do dia, o sistema coletava dados das 3 plataformas e classificava cada post como viral, acima da média, na média, abaixo ou flop.
Dia 2 — O Cérebro e a Voz. 35 commits. O dia mais intenso. Dois sistemas grandes apareceram: o “Oracle” (rastreamento de eventos, convenções, lançamentos de jogos/filmes/anime, notícias) e o chatbot Discord com tool calling via RubyLLM. Também hardening pra produção, Docker, guia de deploy. E uma pivotada grande: troquei o relatório semanal por email por 5 digests diários via Discord.
Dia 3 — Entretenimento e Resiliência. 11 commits. Steam games (Store API + SteamSpy), AniList pra tracking de animes da temporada, analytics de crescimento, geração de imagens via Gemini, sistema de auto-healing pra URLs quebradas.
Os números finais:
| Métrica | Valor |
|---|---|
| Arquivos | 430 |
| Linhas totais | 37.088 |
| Linhas de Ruby | 25.562 |
| Testes | 916 (0 falhas) |
| Modelos | 17 |
| Jobs agendados | 25+ |
| Tools do bot | 40+ |
| Prompts YAML | 23 |
| Integrações externas | 12+ APIs |
Esses números não são mérito meu. Claude fez boa parte do código. Mas a direção, as decisões arquiteturais, e principalmente a validação de cada step foram humanas. Claude não sabe o que uma influencer brasileira de cosplay precisa. Eu também não sabia — mas ela me disse.
A Arquitetura que Emergiu
O sistema final é um Rails 8 headless. Zero interface web. Sem views, sem controllers de verdade (só o /up pra health check). Toda funcionalidade é entregue via background jobs, rake tasks, e o chatbot Discord.
A stack:
- Rails 8.1 com Solid Queue (jobs) e Solid Cache
- SQLite3 em produção (WAL mode, bind mount entre containers)
- RubyLLM pra integração com Claude Sonnet via OpenRouter e Grok
- Ferrum pra scraping com headless Chrome
- Discordrb pro chatbot
- Docker Compose com 4 serviços
O docker-compose.yml ficou enxuto:
x-app: &app
build: .
env_file: .env
restart: unless-stopped
volumes:
- ./data/storage:/rails/storage
services:
app:
<<: *app
ports:
- "127.0.0.1:3000:80"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:80/up"]
deploy:
resources:
limits:
memory: 512M
jobs:
<<: *app
command: bundle exec rake solid_queue:start
depends_on:
app:
condition: service_healthy
deploy:
resources:
limits:
memory: 1G
discord:
<<: *app
command: bundle exec rake discord:start
depends_on:
app:
condition: service_healthy
chrome:
image: chromedp/headless-shell:stable
deploy:
resources:
limits:
memory: 1G4 containers: app (Puma, basicamente só o health check), jobs (Solid Queue rodando 25+ jobs scheduled), discord (o bot), e chrome (headless browser pra scraping). Todo o estado fica em SQLite via bind mount no host. Sem Redis, sem Postgres, sem infraestrutura extra.
Idempotência Acima de Tudo
Se eu tivesse que escolher um conceito pra resumir o projeto, seria idempotência. Todo job pode rodar duas vezes seguidas sem criar duplicatas, sem corromper dados, sem efeitos colaterais.
O pattern base:
module Collection
class BaseCollectorJob < ApplicationJob
SNAPSHOT_DEDUP_WINDOW = 1.hour
retry_on StandardError, wait: :polynomially_longer, attempts: 3
def perform(profile_id: nil)
scope = profile_id ? SocialProfile.where(id: profile_id) : profiles_to_collect
scope.find_each do |profile|
log = find_or_create_log(profile)
begin
items = collect_for_profile(profile)
profile.touch(:last_collected_at)
log.update!(status: :completed, items_collected: items || 0)
rescue => e
log.update!(status: :failed, error_message: "#{e.class}: #{e.message}")
raise if should_raise?(e)
end
end
end
def upsert_post(profile, attrs)
post = profile.social_posts.find_or_initialize_by(
platform_post_id: attrs[:platform_post_id]
)
post.assign_attributes(attrs.except(:platform_post_id))
post.save!
post
end
def record_snapshot(profile, metrics)
return if profile.profile_snapshots
.where("captured_at > ?", SNAPSHOT_DEDUP_WINDOW.ago).exists?
profile.profile_snapshots.create!(captured_at: Time.current, **metrics)
end
end
endDois mecanismos de proteção: find_or_initialize_by(platform_post_id) pra posts (upsert, não insert), e SNAPSHOT_DEDUP_WINDOW pra snapshots (ignora se já coletou na última hora). Se o job crashear no meio e o Solid Queue reenfileirar, nada duplica.
Erros de scraping (BlockedError, RateLimitError) são engolidos silenciosamente — o retry não ajuda, o rate limit precisa esfriar, e ser bloqueado é esperado. Erros de verdade (banco, rede, bugs) sobem pro retry com backoff polinomial.
Essa decisão de “engolir certos erros” parece errada até você rodar o sistema por uma semana e ver que o Instagram bloqueia uma em cada 5 coletas. Se cada bloqueio gerasse 3 retries com backoff exponencial, o sistema ficaria perpetuamente atrasado.
nil vs Zero
Esse é um daqueles bugs conceituais que você só descobre com dados reais. Quando o Instagram não retorna o número de compartilhamentos de um post (porque a API simplesmente não fornece esse dado), o valor deveria ser nil ou 0?
A diferença importa. nil significa “não temos esse dado”. Zero significa “temos o dado e ele é zero”. Se você trata nil como zero, a análise de LLM conclui que ninguém compartilha posts no Instagram — o que é falso. A API simplesmente não expõe essa métrica.
Criei um snippet de prompt reutilizável só pra isso:
Quando um campo é null: Não diga “0 likes” — diga “dado não disponível para esta plataforma”. Quando comparar plataformas, avise que certas métricas não são comparáveis. Quando é zero: Reporte normalmente — o dado é real e confirmado pela API.
Esse snippet é incluído em todo prompt que lida com dados numéricos. Sem ele, o LLM mistura alegremente “não coletado” com “zero de verdade” e tira conclusões erradas.
O Truque do Chrome Headless: Host Header Bypass
O projeto usa chromedp/headless-shell num container separado pra scraping. Funciona perfeitamente. Até você tentar conectar o Ferrum (a gem Ruby de automação de Chrome) nele via Docker networking.
O problema: chromedp/headless-shell usa um proxy socat na porta 9222 que rejeita qualquer request cujo header Host não seja localhost ou um IP. Quando o Ferrum tenta conectar em http://chrome:9222, o Host header vai como chrome:9222, e o socat recusa.
A solução foi descobrir a URL do WebSocket manualmente, forjando o header:
def discover_ws_url(chrome_url)
uri = URI.parse("#{chrome_url}/json/version")
req = Net::HTTP::Get.new(uri)
req["Host"] = "localhost" # bypass
response = Net::HTTP.start(uri.hostname, uri.port) { |http| http.request(req) }
data = JSON.parse(response.body)
ws_url = data["webSocketDebuggerUrl"]
return nil unless ws_url
# WS URL aponta pra 127.0.0.1 dentro do container — troca pelo hostname acessível
remote_uri = URI.parse(chrome_url)
ws_url.sub(%r{://[^/]+}, "://#{remote_uri.host}:#{remote_uri.port}")
endFaço o GET em /json/version com Host: localhost pra passar pelo socat. Recebo a URL de WebSocket (que aponta pra 127.0.0.1 — inútil fora do container). Reescrevo o hostname pra chrome:9222 (o nome do serviço no Docker Compose). Passo a ws_url direto pro Ferrum, que abre o WebSocket sem passar pelo HTTP do socat.
Esse tipo de coisa não vem à cabeça no começo. Você descobre depois de 1 hora de connection refused e leitura do código fonte do chromedp/headless-shell.
Tool Calling: O Bot que Consulta o Banco Sozinho
A parte mais legal do projeto é o chatbot no Discord. Ela digita uma pergunta em português (“como foram meus posts essa semana?”) e o bot chama as ferramentas certas, consulta o banco, e responde com dados reais.
O segredo é o tool calling do RubyLLM. Cada ferramenta é uma classe Ruby com description e params:
class PostPerformanceTool < RubyLLM::Tool
description "Retorna estatísticas de performance dos posts: baseline, " \
"breakdown por tipo de conteúdo, melhores horários, melhores hashtags."
param :username, type: :string, desc: "Username do perfil (ex: milaoliveira.png)"
param :analysis, type: :string,
desc: "Tipo: baseline, content_types, timing, hashtags",
required: false
def execute(username:, analysis: "baseline")
profile = SocialProfile.find_by(username: username.to_s.strip)
return "Perfil '#{username}' não encontrado." unless profile
case analysis.to_s.strip.downcase
when "baseline"
baseline = PostPerformance.compute_baseline(profile)
{
username: profile.username,
post_count: baseline[:post_count],
mean_views: baseline[:mean_views].round(0),
stddev_views: baseline[:stddev_views].round(0),
mean_engagement: baseline[:mean_engagement].round(2)
}
when "timing"
PostPerformance.timing_breakdown(profile).first(10).map do |entry|
{ day: days[entry[:day]], hour: "%02d:00" % entry[:hour],
avg_percentile: entry[:avg_percentile].round(1) }
end
# ...
end
end
endO LLM recebe a lista de 40+ ferramentas com suas descrições, decide quais chamar com quais parâmetros, recebe os resultados, e formula a resposta. O bot no Discord mostra status em tempo real enquanto processa: “Consultando métricas de perfis… Verificando crescimento… Analisando desempenho de posts… (3 consultas)”.
O truque foi fazer cada tool retornar dados estruturados (Hashes e Arrays), não texto formatado. O LLM é muito melhor formatando dados brutos em resposta conversacional do que tentando parsear texto semi-estruturado.
Outro detalhe que só apareceu no uso real: clamping de parâmetros. Quando o LLM pede limit: 999 num parâmetro que aceita no máximo 50, ao invés de retornar erro, faço [[val.to_i, 1].max, 50].min. O LLM erra parâmetros mais do que você imagina. Cada erro gera um round-trip de correção que custa tokens e tempo.
Composable Prompts: YAML > Strings Hardcoded
Todos os prompts do sistema vivem em YAML no config/prompts/. Cada um tem um system (instruções fixas), um template (com interpolação de dados), e opcionalmente includes (snippets reutilizáveis):
module Llm
class PromptBuilder
PROMPTS_DIR = Rails.root.join("config", "prompts")
class << self
def build(name, data = {})
prompt = load_prompt(name)
base = load_prompt(:_base_context)
includes = resolve_includes(prompt["includes"])
system_parts = [base["system"], includes, prompt["system"]]
.compact.reject(&:blank?)
system_message = system_parts.join("\n\n")
user_message = interpolate(prompt["template"], data)
{ system: system_message, user: user_message }
end
end
end
endO _base_context.yml tem informações que todo prompt precisa (quem é a influencer, nichos, público, diretrizes gerais). Os snippets em config/prompts/snippets/ resolvem problemas recorrentes:
null_vs_zero.yml— a distinção nil/zero explicada acimanever_invent.yml— “NUNCA invente dados, analise só o que está presente”json_only.yml— “responda SOMENTE em JSON válido”
Quando um prompt precisa de qualquer combinação desses, basta listar nos includes. Sem duplicação, sem risco de instruções conflitantes entre prompts.
Essa decisão veio de um bug real: dois prompts diferentes davam instruções contraditórias sobre como tratar valores nulos. Um dizia “use 0”, outro dizia “use null”. O LLM obedecia um ou outro dependendo do dia. Centralizar em snippets eliminou a classe inteira de inconsistência.
Discovery Pipeline: Mineração Autônoma de Perfis
O sistema inicial partiu de uma lista manual de concorrentes e patrocinadores. Mas a influencer vive num ecossistema dinâmico — novos creators aparecem toda semana, marcas surgem e somem. O discovery pipeline automatiza isso.
Roda toda sexta-feira às 2 da manhã. Começa minerando dados que já temos no banco: quem tá sendo @mencionado nos posts, quem comenta com frequência e alto engagement, que perfis aparecem em links de bio, quem usa hashtags de marca (#publi, #parceria), que links de Linktree apontam pra outros criadores. Tudo puro SQL, sem API calls, sem risco de rate limit.
Os candidatos que saem daí são validados contra as APIs das plataformas (o Instagram existe? O canal do YouTube é real?), depois enriquecidos com conexões cross-platform (se validamos um Instagram, procuramos o YouTube e X do mesmo criador).
Uma chamada de LLM em batch avalia todos os candidatos, classifica como concorrente, patrocinador potencial ou irrelevante, e dá scores de relevância e fit com o nicho. Os top 3 viram perfis rastreados de verdade — o sistema começa a coletar dados deles automaticamente.
Depois, agrupa tudo em entidades Creator. A influencer é profundidade 0. Concorrentes diretos, profundidade 1. Menções de concorrentes, profundidade 2. Limite máximo de 3 graus de separação, pra evitar cascata infinita.
De Relatório Semanal pra Digests Diários: Ouvindo a Usuária
O plano original era um relatório semanal por email com 9 seções. Mas no meio do caminho decidi que seria mais dinâmico não sair do Discord mesmo e ter essa informação sempre disponível.
Pivotei pra 5 digests diários no Discord:
- Segunda — Recap de Performance (seguidores, crescimento, top posts)
- Terça — Radar de Concorrentes (snapshot, notícias, estratégias)
- Quarta — Playbook de Conteúdo (agenda, tendências, hashtags)
- Quinta — Oportunidades e Preços (marcas, pricing, pacotes)
- Sexta — Semana que Vem (eventos, ações prioritárias)
Cada digest tem itens numerados com botões de feedback. Ela marca o que achou útil e o que não achou. Esse feedback alimenta as análises futuras — o sistema aprende quais tipos de insight ela valoriza.
Essa mudança, que não estava em nenhum plano, provavelmente foi a que mais melhorou a experiência dela. Toda manhã às 9h ela abre o Discord e tem um resumo fresco, digerível, acionável. O email semanal ficou como backup, comentado no recurring.yml.
O Oracle: Contexto que o Algoritmo Não Vê

Dados de redes sociais sem contexto externo são meio inúteis. “Esse post teve 3x mais views que a média” é um fato. “Esse post teve 3x mais views porque saiu no dia do trailer do novo Sonic” é uma insight.
O Oracle é o subsistema que fornece esse contexto.
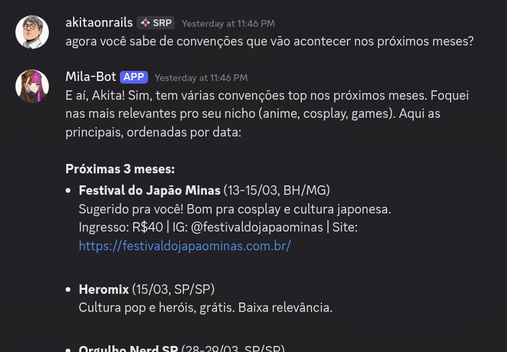
A parte mais crítica é o rastreamento de convenções: CCXP, Anime Friends, BGS, e dezenas de outros eventos do calendário geek. Datas, preços, venues, links de ingresso, contas de Instagram/X do evento. Monitora diariamente por mudanças (data alterada, cancelamento, anúncio de convidado). A influencer planeja o calendário inteiro em torno de convenções. Se a CCXP muda de data, ela precisa saber no dia, não na semana seguinte.
Também rastreia lançamentos de filmes/séries via TMDB, jogos via IGDB (com OAuth do Twitch), animes via AniList — tudo filtrado pra conteúdo geek, janela de 90 dias pra frente. Aniversários de franquias (usando TMDB, IGDB, AniList, Wikimedia) e feriados brasileiros com cálculo de datas móveis. Sim, tem um calculador de Páscoa no código baseado no algoritmo computus. E notícias via scraping de RSS e X/Twitter a cada 6 horas, classificadas por relevância ao nicho.
O evento tracker scrapa sites de convenção com Chrome headless e usa LLM com temperatura 0.1 pra extrair metadados estruturados (data, preço, venue). Tem fallback com regex pra datas no formato brasileiro (“15 de março de 2026”). Deduplicação por fuzzy matching de nome + proximidade de data — porque “CCXP 2026”, “CCXP São Paulo 2026” e “CCXP SP” são o mesmo evento.
SQLite em Produção: Sim, Funciona
SQLite3 em produção. Com WAL mode, um único writer por vez é suficiente porque o sistema tem um padrão previsível de escrita (jobs sequenciais, nunca concorrentes no mesmo segundo). Os dados ficam num bind mount do Docker (./data/storage:/rails/storage) e backup é cp data/storage/*.db backups/.
Rails 8 trata SQLite como cidadão de primeira classe. Solid Queue e Solid Cache rodam em SQLite sem problemas. O overhead de um Postgres pra um sistema que serve uma pessoa não se justifica.
25+ Jobs Agendados
O config/recurring.yml tem 25+ jobs com horários distribuídos pra não sobrecarregar a máquina:
production:
youtube_collection:
class: Collection::YoutubeCollectorJob
schedule: every day at 3am
instagram_collection:
class: Collection::InstagramCollectorJob
schedule: every day at 4am
x_collection:
class: Collection::XCollectorJob
schedule: every 2 days at 5am
oracle_events:
class: Oracle::EventTrackerJob
schedule: every Monday at 2am
convention_monitor:
class: Oracle::ConventionMonitorJob
schedule: every day at 5am
discovery_pipeline:
class: Discovery::OrchestratorJob
schedule: every Friday at 2am
comment_sentiment:
class: Analysis::CommentSentimentJob
schedule: every Sunday at 5am
weekly_analysis:
class: Analysis::WeeklyAnalysisJob
schedule: every Sunday at 6amColeta roda de madrugada (3am-5am). Oracle de inteligência começa na segunda às 2am. Discovery na sexta às 2am. Análise pesada (sentimento, estratégia) no domingo quando não tem digest pra entregar. Digests de segunda a sexta às 9am, cada dia com tema diferente. Manutenção (limpeza de jobs terminados, health check de URLs, agregação de dados antigos) nos intervalos.
O padrão é intencional: nenhum job pesado compete com os digests da manhã. Se a análise semanal atrasar, o digest de segunda ainda entrega porque usa dados da coleta de sábado, não da análise de domingo.
O Que Não Dá Pra Prever Sem Rodar
Algumas coisas que só descobri depois que o sistema tava rodando em produção.
O Instagram bloqueia scraping aleatoriamente. Não importa quão stealth seu browser é. A configuração inicial era só scraping via Ferrum. De cara, resolvi adicionar o Apify como fonte primária (API paga, mais confiável) e o scraping virou fallback.
LLMs alucinam timestamps. Pedi pro bot criar um lembrete pra “amanhã às 15h” e ele calculou uma data em 2024. A solução foi injetar current_datetime em todo prompt que lida com tempo e instruir explicitamente: “calcule baseado em current_datetime, converta pra ISO 8601 com UTC-3”.
O Discord tem limite de 2000 caracteres por mensagem, o que parece óbvio até seu bot mandar uma análise de 4000 chars e o Discord simplesmente truncar. Implementei split automático que quebra no último \n antes do limite.
Os tool calls falham com frequência em parâmetros, o que me surpreendeu. O LLM pede limit: 100 quando o máximo é 50, ou manda o username sem o @ quando deveria ter. Clamping silencioso ([[val.to_i, 1].max, 50].min) e normalização de input (.strip, .delete("@")) em toda tool eliminaram uma categoria inteira de erros que estavam consumindo tokens em loops de retry.
Convenções mudam de data mais do que eu imaginava. Adicionei um sistema de announcements que acompanha cada mudança (data, venue, preço, cancelamento) com timestamp. O evento tracker roda toda segunda, mas o convention monitor roda DIÁRIO porque a última coisa que a influencer quer é descobrir que uma convenção mudou de data depois de já ter reservado hotel.
O Bot Como Interface
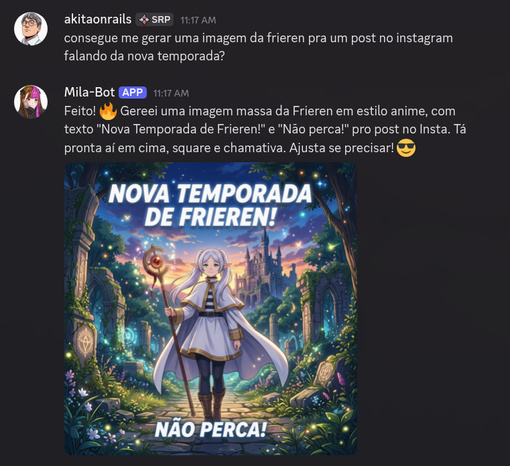
A decisão mais acertada do projeto foi não fazer interface web. O Discord já é onde a influencer passa o dia. O bot vive ali, disponível a qualquer momento. Ela digita “o que eu deveria postar essa semana?” e recebe uma resposta contextualizada com dados dos seus posts, dos concorrentes, do calendário de eventos, das tendências de hashtag, e dos animes/games da temporada.
O chatbot combina múltiplas tools numa resposta. Se ela pergunta sobre estratégia de conteúdo, o LLM chama: digest de conteúdo + calendário de eventos + tendências de hashtag + animes da temporada + jogos da Steam. Cinco consultas ao banco, tudo costurado numa resposta conversacional em português.
Tem até um modo de “pensamento profundo” que ativa quando detecta palavras como “pesquise”, “analise”, “investigue”. Nesse modo, o bot usa TODAS as ferramentas relevantes, faz múltiplas consultas, cruza dados entre fontes.
Conclusão
O projeto inteiro saiu em 3 dias, de zero a produção, coletando dados reais, mandando digests toda manhã. Sem Jira, sem sprint planning, sem 6 meses de discovery phase. Um IDEA.md com os desejos da usuária nas palavras dela, desenvolvimento iterativo commit a commit, e validação contínua com quem vai usar de verdade.
Se eu tivesse começado pela arquitetura, teria passado semanas projetando um dashboard que ela não ia abrir. Começando pelo desejo, o sistema acabou sendo um chatbot no Discord que ela usa todo dia. Jobs assíncronos que não são idempotentes são bombas-relógio — o rate limit vai estourar, o scraping vai falhar, o container vai reiniciar, e se o job não sobrevive a isso sem duplicar dados, o sistema não funciona.
No final das contas, a medida de sucesso do projeto não é a quantidade de linhas de código, nem o número de testes passando, nem a arquitetura elegante. É a influencer abrindo o Discord segunda de manhã e tendo o que precisa pra planejar a semana.