Vibe Code: Fiz um Indexador Inteligente de Imagens com IA em 2 dias | Frank Sherlock
Nas últimas 48 horas, construí do zero um aplicativo desktop completo, com binários publicados para Linux, macOS e Windows. 50 commits, ~26 horas de trabalho efetivo, 8.359 linhas de Rust, 5.842 de TypeScript, 338 testes automatizados. Se você me dissesse isso 2 anos atrás, eu chamaria de mentira.

O nome é Frank Sherlock — um sistema local de catalogação e busca de imagens usando IA. Você aponta pra uma pasta (pode ser um NAS com terabytes), ele escaneia tudo, classifica cada arquivo usando um LLM de visão rodando localmente na sua GPU, e te dá busca full-text sobre o conteúdo. Não é cloud, não manda nada pra fora, roda 100% na sua máquina.
Eis alguns exemplos de textos que ele extraiu de algumas das minhas imagens:
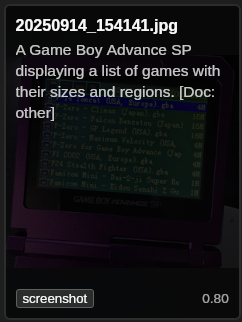
E olha os detalhes do Surya OCR: ele leu direitinho o texto na tela do Game Boy:
Mais do que isso, eu tenho diretórios de screenshots de comprovantes de pagamento. Nunca mais ia achar nada ali, mas agora:

Embora ele faça alguns erros, claro, animes obscuros (ele fica achando que tudo que ele não reconhece é Evangelion 😂). Mas muitos ele surpreendentemente acerta também. Mas as descrições em si já ajudam muito.
Vai precisar de um mínimo de GPU (eu só testei na minha 5090, mas é pra baixar modelos menores pra GPUs menores, e teoricamente suporta AMD e Mac também, mas ainda não testei - aceito Issues e Pull Requests pra quem quiser fazer beta-testing em Mac e Windows). Basta ter o Ollama instalado e rodando; opcionalmente, Python (pra ter o Surya OCR, que é opcional, mas é o melhor).
Vou colocar como “1.0” quando tiver mais gente testado em Windows/macOS e eu tiver os certificados pra assinar os executáveis direitinho. Esta é uma versão “beta” ainda! Compilem e rodem vocês mesmos em suas máquinas, tá tudo explicado no README.
E eu fiz isso com meu “Agile Vibe Coding” — basicamente, programar em parceria com um LLM (no caso, Claude Code).
Agile Vibe Coding funciona. E funciona muito bem. Mas a ideia é só 10% do trabalho. Os outros 90% são engenharia.
Engenharia requer experiência, julgamento, e saber fazer as perguntas certas. O LLM é um executor excelente. Mas quem decide o que executar, em que ordem, e por quê, esse continua sendo o trabalho do desenvolvedor.
Tem um discurso crescente de que qualquer pessoa com uma boa ideia pode construir software agora. Num certo sentido, sim, você pode colocar um protótipo no ar rápido. Mas a distância entre “roda na minha máquina” e “software que funciona em 3 sistemas operacionais, sobrevive a cancelamentos no meio do processamento, não corrompe dados, e escala de 94 arquivos de teste pra 500 mil em produção” continua sendo enorme. Esse gap é engenharia, e engenharia ainda exige alguém que saiba o que está fazendo.
Vou contar a história completa: da pesquisa inicial ao release, passando por benchmarks, prova de conceito, decisões de arquitetura, CI/CD multi-plataforma, e tudo que ficou entre “eu tenho uma ideia” e “aqui está o AppImage, o DMG e o MSI”.

A Ideia Original
Tudo começou com uma pergunta simples: será que LLMs open-source de visão conseguem classificar conteúdo de verdade? Não estou falando de “mulher na praia” — isso qualquer modelo faz. Estou falando de olhar pra uma imagem e dizer “isso é a Ranma, do anime Ranma 1/2 da Rumiko Takahashi, numa cena do OVA The Battle for Miss Beachside”. Será que chegamos nesse nível? (TL;DR não, mas o suficiente)
E se chegamos, dá pra fazer um catálogo inteligente de arquivos? Algo que eu aponte pro meu NAS com terabytes de mídia acumulada ao longo de décadas e consiga buscar por conteúdo, não por nome de arquivo? Quem tem um NAS em casa sabe: depois de alguns anos, os arquivos acumulam e a organização de diretórios simplesmente para de escalar. Você sabe que tem aquele comprovante de pagamento de 2019 em algum lugar, mas o arquivo se chama IMG_20190315_142301.jpg e está num diretório com mais 3 mil fotos.
Meu hardware: AMD 7850X3D, RTX 5090, Arch Linux. Restrição absoluta: nada de APIs remotas, nada de OpenAI, nada de cloud. Tudo open-source, tudo local. Se eu vou processar terabytes de arquivos pessoais, incluindo documentos financeiros e fotos privadas, não quero mandar nada pra servidor de terceiros. Fora que o custo de API cloud pra esse volume seria proibitivo.
Mas primeiro: pesquisa. Sem saber se a tecnologia entrega o que eu preciso, não faz sentido construir nada. Scripts pequenos, protótipos rápidos, modelos diferentes. Ver o que funciona antes de escrever a primeira linha de código do app de verdade. Esse é um padrão que eu sigo há anos: valide a suposição mais arriscada primeiro. Se o LLM de visão não conseguir classificar decentemente, todo o resto é desperdício.
Pesquisa A/B: Benchmark Driven Development
Essa é a parte que a maioria das pessoas pula, e é exatamente onde a experiência faz diferença. A tentação de pular direto pra implementação é enorme. “Vou usar o modelo X porque li num blog que é bom.” Não. Antes de escolher modelo, framework, ou arquitetura, eu montei um benchmark formal.
Montei um corpus de teste com 94 arquivos: 60 imagens (fotos, screenshots, anime, documentos, receipts), 9 áudios, 13 vídeos e 12 documentos. Pra cada arquivo, criei um ground truth em JSON com a classificação correta — tipo, descrição, série (quando aplicável). Esse ground truth é o que permite medir accuracy de verdade, não “olhei o resultado e pareceu OK”.
O benchmark tem 6 fases, cada uma respondendo a uma pergunta específica:
- Metadata: quanto custa extrair metadata básica? (resposta: barato, 0.07s/arquivo)
- Imagens: qual modelo de visão é melhor? Qual OCR?
- Áudio: Whisper funciona? Qual tamanho de modelo?
- Vídeo: classificação por frames funciona?
- Catálogo unificado: o pipeline completo integrado funciona?
- Projeção de custo: quanto tempo e dinheiro pra processar um NAS real?
Fase 2: Visão — O Resultado Que Ninguém Esperava
Testei qwen2.5vl:7b, llava:13b e minicpm-v:8b em 30 imagens rotuladas. O resultado:
| Modelo | Type Accuracy | Series Accuracy | JSON Valid | Latência/img |
|---|---|---|---|---|
| qwen2.5vl:7b | 0.80 | 0.14 | 0.87 | 0.55s |
| minicpm-v:8b | 0.50 | 0.00 | 0.83 | 1.63s |
| llava:13b | 0.33 | 0.06 | 0.83 | 1.62s |
O modelo de 7B parâmetros ganhou de lavada dos maiores. Não é typo. O qwen2.5vl:7b bateu o llava:13b (quase o dobro do tamanho) em todas as métricas, e ainda foi 3x mais rápido. Isso contradiz a intuição de “modelo maior = modelo melhor”. Na prática, depende do task e do prompt.
Naturalmente, a próxima pergunta é: e o 32B? Mesmo modelo, versão gigante. A gente deve conseguir bem mais, certo? Errado:
| Modelo | Type Accuracy | Series Accuracy | Latência/img |
|---|---|---|---|
| qwen2.5vl:7b | 0.87 | 0.19 | 0.77s |
| qwen2.5vl:32b | 0.87 | 0.25 | 22.46s |
O 32B deu +0.06 em series accuracy (literalmente 1 acerto a mais em 16 itens rotulados) e custou 29x mais tempo. Pra quem vai processar centenas de milhares de arquivos, essa troca não fecha. 29x mais lento significa que um job de 6 horas vira um job de uma semana.
Aqui faço um comentário sobre ferramenta: fiz a primeira rodada com Claude Code e tinha pedido pra ele escolher os modelos que achava melhores. Mas depois decidi ir pro GPT Codex e ele fez outras sugestões que achei interessante testar. Em resumo: tenho achado Codex muito melhor pra experimentação e código exploratório, pra pesquisa mesmo. Claude eu acho melhor quando já sabemos melhor exatamente o que queremos.
Com o Codex, testei os novos candidatos qwen3-vl:8b e qwen3-vl:30b-a3b com 3 repetições para fins de significância estatística. Resultado? Ambos piores que o qwen2.5vl:7b — type_accuracy de 0.55 contra 0.89 do incumbent, com intervalo de confiança de 95% que nem se aproxima. E ainda mais lentos: 2x e 2.2x respectivamente. Modelo mais novo nem sempre é modelo melhor pro seu caso de uso. O qwen3-vl frequentemente retornava JSON truncado ou mal-formado — uma regressão real em robustez.
OCR: Surya vs Ollama Vision
Para extração de texto (documentos escaneados, receipts, screenshots com texto), testei dois engines:
| Engine | Cobertura | Similaridade | Latência/img |
|---|---|---|---|
| Surya | 54/65 arquivos | 0.9455 | 8.15s |
| Ollama Vision | 38/65 arquivos | 0.9419 | 1.73s |
Surya encontra texto em muito mais arquivos (83% vs 58%), mas é 5x mais lento. Quando encontra texto, a qualidade é praticamente igual (similarity > 0.94 nos dois). Solução óbvia: abordagem híbrida. Usa Surya quando precisa de cobertura máxima, Ollama Vision como fallback rápido. O design do pipeline ficou: tenta Surya → se falhar ou não encontrar texto → fallback pra Ollama Vision. Por isso falei no começo que Surya é opcional, se não quiser instalar.
Projeção de Custo
A fase 6 fez algo que raramente vejo em projetos open-source: projeção de custo pra uso real. Com os timings medidos por tipo de arquivo, extrapolamos pra cenários de NAS:
| Cenário | Arquivos | Tempo | Custo Elétrico |
|---|---|---|---|
| Corpus teste | 94 | 24 min | $0.02 |
| NAS pequeno | ~5K | 6.6 h | $0.36 |
| NAS médio | ~50K | 2.6 dias | $3.37 |
| NAS grande | ~500K | 26 dias | $33.70 |
Leve esses números com algum ceticismo porque é conta em papel de pão. $34 de eletricidade pra classificar 500 mil arquivos com GPU local. Tenta fazer isso com API do GPT-4 Vision — a $0.01 por imagem (conservador), são $5.000. O preço do meu setup (GPU + eletricidade) se paga no primeiro uso grande.
A lição: faça benchmark, não adivinhe. Eu poderia ter assumido que o modelo maior seria melhor, ou que o mais novo superaria o antigo. Os dados mostraram o contrário. ~2 horas de benchmarks me pouparam de escolhas erradas que custariam dias de retrabalho (antigamente eu diria “semanas”).
Prova de Conceito em Python
Com os benchmarks em mãos, o próximo passo foi validar o pipeline completo antes de partir pro Rust. Não o pipeline de benchmark (que testa cada modelo isoladamente), mas o pipeline de classificação real — a sequência exata de chamadas que o app final vai fazer pra cada arquivo.
Criei um protótipo em Python — 754 linhas em um único arquivo (classification/run_classification.py) — que implementava a estratégia vencedora dos benchmarks.
O pipeline tem 4 estágios de enriquecimento:
- Classificação primária: manda a imagem pro
qwen2.5vl:7bcom prompt estruturado, pede JSON com tipo, descrição, tags, confidence - Enriquecimento anime: se o tipo primário for anime/manga/cartoon, faz uma segunda passada com prompt especializado pedindo série, personagem, cena, artista
- Documento/OCR: se for documento ou receipt, extrai texto com Surya e/ou Ollama Vision, depois pede dados estruturados (datas, valores, IDs de transação)
- Output: grava resultado em YAML espelhando a estrutura de diretórios de origem
A parte mais crítica é o parsing de JSON do LLM. Quem já trabalhou com output de LLMs sabe que eles são… criativos com formatação. Às vezes vem com markdown fences (json ... ). Às vezes tem texto antes e depois do JSON. Às vezes o JSON está quase certo mas falta fechar uma chave. O protótipo implementou uma cascata de 3 tentativas que depois virou a regra do projeto inteiro:
- Parse direto:
json.loads(response)— funciona em ~70% dos casos - Extração por balanceamento de chaves: encontra o primeiro
{, conta chaves abertas e fechadas, extrai o substring — pega mais ~20% - Regex field salvage: se tudo mais falhar, usa regex pra extrair campos individuais (“type”: “…”, “description”: “…”) — salva os últimos ~10%
Essa cascata ficou no código Rust praticamente idêntica. PoC bem feito encurta o caminho pra produção.
Resultado: 60 imagens processadas, zero erros, 6.29s/imagem de média. O pipeline funcionava de ponta a ponta. Hora de construir o app de verdade.
Construindo o App Tauri
Nesse ponto, tentei continuar com o Codex, mas aí ele se engasgou em tentar converter o Poc em Python pra Tauri. Mas como agora as escolhas já foram feita, voltei pro Claude Code, e ele não teve problemas em mapear do Python pra Rust.
Aqui é onde o vibe coding mostra a que veio. Vou contar a timeline real, commit por commit, pra você ter noção do ritmo. Os timestamps são do git log, então são precisos.
Sábado 21/02 (19:29 → 21:08) — 6 commits, 1h39
Tudo começou com research. Seis commits de setup, scripts de benchmark, análise de resultados:
f57221c 19:29 Phase 0: Project setup with uv, environment verification
4977497 19:45 Implement all phases: metadata, image/audio/video classification
af6e3aa 19:49 Add research results report
41d6c2a 20:12 Add per-file timing, OCR phase, cost estimation
0cd1b10 21:02 Fix Surya OCR, re-run on 94-file corpus
25b3ace 21:08 Add conclusions, cost analysis, recommended pipelineSábado à noite, só pesquisa pura. Nenhuma linha de código do app. Mas quando fui dormir, sabia qual modelo usar, qual abordagem de OCR, e quanto ia custar em tempo e eletricidade.
Domingo 22/02 (13:05 → 23:30) — 14 commits, ~10h25
O domingo foi o dia de construção pesada. Acordei, almocei, e sentei pra trabalhar.
13:05 — Primeiro commit do dia: o protótipo Python de classificação. 749 linhas validando o pipeline completo de classificação, a cascata de JSON parsing, e o enriquecimento condicional. Esse protótipo não era throwaway — ele era o design document executável do pipeline Rust que viria depois.
Dei uma pausa pra pra dar uma saída, passear, tomar um vinho, depois voltei e continuei:
17:31 — Benchmarks atualizados com os novos candidatos (qwen3-vl:8b e qwen3-vl:30b-a3b). Três repetições cada, intervalos de confiança. Confirmaram que o qwen2.5vl:7b era a escolha certa — não por pouco, mas por uma margem enorme.
17:56 — O “big bang”: scaffold do app Tauri. 9.631 linhas inseridas num único commit. A estrutura inteira do app: Rust backend com SQLite + FTS5, React frontend, config system, scanner de arquivos, modelos de dados, query parser pra busca natural. Nesse ponto o app já buscava no banco. Não tinha classificação ainda, mas a fundação estava sólida — e é exatamente o ponto. O scaffold veio com testes, tipos TypeScript, e a arquitetura de diretórios que eu defini. O Claude gerou o código, mas a estrutura de módulos (config, db, scan, models, query_parser) veio de como eu queria organizar as responsabilidades.
19:04 — O commit mais pesado do projeto: 4.186 linhas. Classification pipeline em Rust (1.069 linhas de classify.rs — praticamente a tradução do PoC Python), geração de thumbnails (Lanczos3, 300px, JPEG 80%), scanning incremental com fingerprint, o script Surya OCR em Python, runtime detection pra Ollama, e a expansão brutal do banco de dados com upsert, touch, delete e FTS indexing. Num commit. Com 47 testes. Eu tive que tomar as decisões de arquitetura (como o cache espelha o rel_path, como o scan é dividido em duas fases, como os erros propagam), mas o Claude escreveu o grosso do código e os testes que vieram junto.
19:55 — Redesign de UI, cancellation de scan, auto-cleanup de classificações órfãs, reorganização do repo inteiro (movi tudo de research pra _research_ab_test/). CI e release workflow já configurados nesse commit — eu sabia que ia precisar deles no dia seguinte.
21:02 — DB resilience (WAL mode, backup, health check), gerenciamento de roots (adicionar, remover, listar diretórios monitorados), zoom, redesign do sidebar com tree view, fix de thumbnails. Quatro features num commit. Num workflow manual, cada uma dessas seria um PR separado com review de dias.
21:14 → 21:39 — Read-only database mode pra filesystems sandbox, resume de scans interrompidos no startup, redesign de grid tiles com hover overlay, modelo de seleção, infinite scroll. Três commits em 25 minutos. O Claude estava num ritmo absurdo.
22:41 — Multi-select com Ctrl/Shift click, preview de collage com os itens selecionados, Ctrl+C copia pro clipboard do OS.
23:30 — O grande refactor: frontend monolítico (tudo no App.tsx - se não explicar, Claude sempre faz isso) desmembrado em 15 componentes + 10 hooks + 84 testes frontend. Esse é o tipo de coisa que normalmente leva um dia inteiro de trabalho tedioso. Com vibe coding, foi um commit de uma hora. O Claude extraiu cada componente, criou os hooks, montou os testes com mocks adequados, e manteve tudo funcionando. Eu só precisei dizer “refatora esse monolito em componentes e hooks, e escreve testes pra cada um”.
Segunda-feira 23/02 (00:09 → 14:33) — 30 commits, ~14h
A segunda foi de polimento, robustez e a maratona de cross-platform.
00:09 — Abstração multi-OS: todo código específico de plataforma isolado no módulo platform/. Essa decisão, tomada cedo, salvou horas de dor no CI. Quando o Windows precisou de tratamento especial pra paths UNC, a mudança ficou contida em platform/process.rs em vez de espalhada em 8 arquivos.
00:12 → 01:18 — Sequência rápida: cargo audit no CI, remoção de duplicações, licença GPL-3.0, help dialog (F1) com exemplos de query syntax, sort controls pra resultados, sistema de migração SQLite formal, context menu (copy, delete, rename). Seis commits em pouco mais de uma hora.
09:38 — Após dormir umas 8 horas, o primeiro commit da manhã: extração do módulo LLM. O monolito de chamadas ao Ollama que vivia dentro de classify.rs foi separado em llm/client.rs (chamadas HTTP, parsing JSON), llm/management.rs (download, listagem, cleanup de modelos) e llm/model_selection.rs (seleção hardware-aware por tier). Atomic file ops pra não corromper cache se o processo morrer no meio de uma escrita.
10:54 — Extração de localização EXIF (GPS coordinates → endereço legível), modal de edição de metadata, setup instructions por OS (cada OS tem dependências diferentes pro Ollama e Python).
11:34 — Suporte a PDF: scanning, indexing e preview usando PDFium. Não é trivial — PDFium precisa de binário nativo por plataforma, renderização de páginas em imagem, detecção de páginas em branco (pra não gerar thumbnail de uma capa vazia), montagem de thumbnail com as 2 primeiras páginas com conteúdo, e extração de texto nativo como alternativa mais rápida ao OCR.
12:08 — Albums e Smart Folders. Albums são coleções manuais (o usuário arrasta arquivos pra dentro), Smart Folders são queries salvas que aparecem no sidebar e atualizam automaticamente. Duas migrações de banco, novo componente de sidebar, drag-and-drop. Em 34 minutos.
12:11 → 12:52 — Ícones SVG macOS-inspired no sidebar, suporte a argumento CLI (sherlock /path/to/folder), copy description/OCR text no context menu, fix de path do PDFium em produção, ícones e screenshots no README, script tauri no npm, sidebar toggle, titlebar dinâmico, fix de compilação Windows (imports Unix-only). Dez commits em 41 minutos. A maioria desses foram issues que apareceram no CI ou durante teste manual.
13:14 → 13:54 — A maratona de CI fixes. Auto-provision do venv Surya OCR com barra de progresso no SetupModal, regeneração de ícones com alpha channel, cargo fmt + clippy + fix de UNC paths no Windows, testes pros exemplos do help dialog, rescan de pasta individual, fix de assertions Windows, fix de permissions do release workflow. Sete commits de hardening. Cada um resolvendo um bug real que aparecia no CI matrix ou em teste.
14:26 — Drag-and-drop pra reordenar roots no sidebar, cancelamento de scan antes de deletar um root (pra não deixar o scan rodando em background num diretório que o usuário removeu — edge case sutil que poderia causar crash).
14:33 — Último commit: fix de responsividade no cancelamento de scan. Check do cancel flag após cada classificação, poll imediato em vez de esperar o próximo tick. Detalhe pequeno, impacto grande na UX.
Decisões de Arquitetura
Aqui é o que separa “deixar o LLM escrever código” de “construir software de verdade”. Nenhuma dessas decisões veio de prompt. O Claude não sugeriu nenhuma espontaneamente. Eu tive que pedir cada uma.
Princípio Read-Only
O app nunca escreve nos diretórios escaneados. Tudo — thumbnails, cache de classificação, banco de dados — fica em ~/.local/share/frank_sherlock/. Isso não é só boa prática, é respeito pelo dado do usuário. Se alguém aponta pro NAS da empresa, o app não pode sair criando .sherlock/ em cada subdiretório. Se o diretório é montado como read-only via NFS, o app precisa funcionar normalmente. Parece óbvio, mas muitos apps de catalogação que você conhece criam caches e thumbnails dentro dos diretórios de origem. (cof Synology @eaDir cof)
Scanning Incremental
Escanear terabytes de dados toda vez que o app abre seria insano. O scan é incremental em dois sentidos:
- Fase de descoberta (rápida): caminha o filesystem comparando mtime + tamanho de cada arquivo. Se nada mudou desde o último scan, nem lê o conteúdo — apenas atualiza o marcador de “visto neste scan”. Pra um NAS com 500K arquivos onde 99% não mudou, essa fase leva segundos, não horas.
- Fase de processamento (pesada): só pra arquivos novos ou modificados. Calcula fingerprint (SHA-256 dos primeiros 64KB), gera thumbnail, classifica com o LLM. E aqui entra a detecção de movidos: se um arquivo mudou de path mas o fingerprint é o mesmo, o app preserva toda a classificação já feita e apenas atualiza o path. Você reorganizou 10 mil fotos em pastas novas? O app detecta e não reclassifica nenhuma.
O checkpoint é por arquivo. Se o scan for interrompido (o app crashou, o usuário fechou, acabou a luz), na próxima vez ele retoma do último arquivo processado, não do zero. Isso é implementado via scan job persistence no banco: o cursor do scan fica salvo em scan_jobs.
Cancelamento Cooperativo
O scan roda numa thread separada via tokio::spawn_blocking. Para cancelar, uso AtomicBool compartilhado entre a thread de scan e o frontend. O flag é checado:
- Antes de cada arquivo na fase de descoberta
- Antes de cada classificação na fase de processamento
- Após cada classificação (pro caso de a chamada ao Ollama demorar)
Isso garante que o cancelamento responde em no máximo o tempo de uma classificação (~1 segundo), não no tempo do scan inteiro. Sem esse design, cancelar um scan de 500K arquivos poderia levar minutos — ou simplesmente não funcionar.
Resiliência do Banco
SQLite com WAL mode (permite leituras concorrentes durante escrita), health check no startup, backup automático antes de migrações, sistema de migração formal via rusqlite_migration. Cinco migrações no total:
- Schema inicial (tabelas de arquivos, roots, scan_jobs, e a virtual table FTS5 pra busca)
- Coluna
location_textpra endereço EXIF - Rebuild do índice FTS (necessário após mudar a tokenização)
- Tabelas
albumsealbum_filespra coleções manuais - Tabela
smart_folderspra queries salvas
As migrações são identificadas por posição e nunca podem ser editadas ou reordenadas depois de publicadas. Isso é o tipo de regra que você aprende depois de corromper o banco de produção de alguém uma vez. A regra está codificada no CLAUDE.md do projeto pra que futuras sessões de vibe coding não a violem.
Seleção de Modelo Hardware-Aware
Nem todo mundo tem uma RTX 5090. O app detecta a GPU no startup e escolhe o modelo adequado:
- GPU fraca ou sem GPU:
qwen2.5vl:3b(tier small — roda em qualquer coisa) - GPU com >= 6GB VRAM:
qwen2.5vl:7b(tier medium, o default dos benchmarks) - Apple Silicon com >= 48GB unificados:
qwen2.5vl:32b(tier large, só onde a memória unificada permite sem swap)
A detecção usa nvidia-smi no Linux/Windows, system_profiler no macOS, e sysinfo como fallback pra RAM do sistema. O resultado é cacheado no AppState do Tauri pra não ficar executando subprocesso toda hora.
Multi-OS e CI/CD
Se tem uma parte do projeto que justifica ter experiência, é essa. Fazer software que compila é fácil. Fazer software que compila e passa todos os testes em Linux, macOS e Windows ao mesmo tempo te ensina humildade.
Módulo Platform
Todo código específico de OS vive em src-tauri/src/platform/:
gpu.rs: detecção de GPU (NVIDIA via nvidia-smi, AMD via sysfs/rocm-smi, Apple via system_profiler)clipboard.rs: cópia de imagem pro clipboard (xclip no Linux, pbcopy no macOS, PowerShell no Windows)python.rs: localização de Python (python3 vs python no PATH), caminhos de venv por OSprocess.rs: abstração de execução de subprocesso com tratamento de output
Isso significa que classify.rs, scan.rs, thumbnail.rs — nenhum deles sabe em qual OS está rodando. Eles pedem pra plataforma e a plataforma resolve. Quando o Windows precisou de tratamento especial pra paths UNC (aqueles que começam com \\?\), a mudança ficou contida em platform/. Quando o macOS precisou de um import condicional, idem. O resto do codebase não foi tocado.
GitHub Actions Matrix
Dois workflows:
- CI (push + PR): build e teste em Linux, macOS e Windows. Cada push roda
cargo test+npm testnos 3 OS. Incluicargo fmt --check,cargo clippy -- -D warningsecargo audit. Se qualquer plataforma falhar, o PR não passa. - Release (tags v*): build via
tauri-action, gera AppImage (Linux), DMG (macOS arm64), MSI (Windows), e cria um Draft Release no GitHub com os binários anexados.
Os 10+ commits de CI fix na segunda de manhã, foram a parte menos glamorosa do projeto. Coisas como:
#[cfg(not(target_os = "windows"))]em imports que usamstd::os::unix::fs::PermissionsExtdunce::canonicalizeno lugar destd::fs::canonicalizeporque o Windows gera paths com prefixo\\?\que quebram comparações de string- Instalar
rustfmteclippyexplicitamente no runner porque nem sempre vêm no toolchain default da GitHub Actions - Remover o target macOS Intel do release workflow (Apple Silicon only — não vale o custo de manter dois targets Mac)
Ninguém posta essas coisas no X. Mas sem elas, seu app não builda em 2 dos 3 targets.
Integrações Externas
O app depende de 3 sistemas externos. Cada um trouxe seus próprios problemas.
Ollama
O Ollama serve os modelos de visão via API REST local (porta 11434). O app faz:
- Verificação de status: checa se o Ollama está rodando e lista modelos instalados/carregados
- Download de modelo: se o modelo recomendado não está instalado, oferece download com barra de progresso via streaming da API
- Geração: manda imagem em base64 + prompt, recebe JSON (com a cascata de parsing de 3 níveis)
- Cleanup: descarrega modelos da VRAM quando não está classificando, pra não ficar monopolizando a GPU pras outras aplicações do usuário
O Ollama é o único hard requirement. Sem ele, a classificação não funciona. O SetupModal guia o usuário pela instalação e download do modelo.
Surya OCR
Surya é um engine de OCR em Python que roda localmente. O problema: o app é Rust e não pode depender de uma instalação Python do sistema. A solução:
- O app mantém um Python venv isolado em
~/.local/share/frank_sherlock/surya_venv/ - O script
surya_ocr.pyé bundled como resource do Tauri (empacotado no binário) - No primeiro uso, o
SetupModaloferece provisionar o venv automaticamente (encontra Python, cria venv, pip install surya-ocr + dependências) - A classificação chama o script via subprocess, passa a imagem como argumento, lê o texto extraído do stdout
O Surya é um soft requirement: se não estiver instalado, o app funciona normalmente — só não vai ter OCR dedicado. O pipeline degrada gracefully pra usar Ollama Vision como fallback, que é pior em cobertura mas funciona. O usuário vê um aviso no setup, não um erro que bloqueia o uso.
PDFium
Pra PDFs, eu precisava de extração de texto nativo e renderização de páginas pra thumbnail. PDFium é o engine do Chrome pra PDFs, e tem bindings Rust via pdfium-render.
O binário do PDFium é baixado por um script (scripts/download-pdfium.sh) e bundled via lib/ nos resources do Tauri. Cada plataforma recebe o binário correto (.so, .dylib, .dll). O lib/ é gitignored — os binários são baixados no build, não versionados.
O pipeline de PDF:
- Tenta extrair texto nativo (sem OCR) — muitos PDFs já têm text layer
- Se tiver texto suficiente, usa direto pra indexação (mais rápido e mais preciso que OCR)
- Se não, renderiza a página e manda pro pipeline de imagem (Ollama Vision)
- Detecta páginas em branco, encontra a primeira página com conteúdo real
- Gera thumbnail como montagem das 2 primeiras páginas com conteúdo (dá uma noção melhor do documento do que só a capa)
O que Agile Vibe Coding Realmente É
OK, agora o ponto que realmente importa. O motivo de eu estar escrevendo isso.
O Que o Claude Fez
- Escreveu a maior parte do código Rust e TypeScript
- Gerou 166 testes Rust e 172 testes frontend
- Implementou o parsing de JSON com 3 níveis de fallback
- Configurou CI/CD com matrix de 3 OS
- Fez refactors massivos (monolito → 15 componentes + 10 hooks)
- Lidou com edge cases de encoding, paths Unicode, e formatos de arquivo exóticos
- Escreveu queries SQL, migrações, índices FTS5
- Implementou detecção de GPU, clipboard por OS, resolução de Python
- Criou o setup flow com barra de progresso e download de modelo
- Debugou e fixou dezenas de issues de compilação cross-platform
A velocidade é difícil de descrever sem parecer exagero. O commit das 19:04 de sábado, aquele de 4.186 linhas com 47 testes, levou cerca de uma hora incluindo minha revisão. Um dev humano, mesmo bom, levaria um dia inteiro pra escrever isso com a mesma cobertura de testes.
O Que Eu Fiz
- Decidi fazer benchmarks antes de escrever qualquer código de app
- Escolhi Tauri em vez de Electron (menor footprint, Rust nativo, sem Node runtime em prod)
- Defini o princípio read-only como regra inviolável
- Projetei o scan incremental com detecção de move por fingerprint
- Decidi por cooperative cancellation com AtomicBool
- Exigi migração formal de schema (nada de ALTER TABLE ad-hoc em scripts soltos)
- Insisti em abstração de plataforma desde o primeiro commit multi-OS
E principalmente: fiz as perguntas chatas. “E se o scan for cancelado no meio?” virou o sistema de checkpoint. “E se o banco corromper?” virou WAL + backup + health check. “E se a pessoa não tiver GPU boa?” virou model selection por tier. “E se o Surya não estiver instalado?” virou soft requirement com fallback. “E se o usuário deletar um root que está no meio de um scan?” virou cancel-before-delete. “E se o arquivo mudar de lugar mas o conteúdo for o mesmo?” virou detecção de move.
Ah, e decidi a hora de parar de adicionar features e publicar.
Essa última é subestimada. A tentação de ficar adicionando “só mais uma coisa” é enorme quando o custo marginal de implementar é baixo. O Claude implementa qualquer feature que eu pedir em minutos. Mas software que nunca é publicado não serve pra ninguém. Saber a hora de parar é uma skill que nenhum LLM vai te dar.
O Padrão Real
Agile Vibe coding não é “pedir pro LLM fazer um app”. É pair programming com um parceiro que é rápido pra caramba, tem memória perfeita, e nunca reclama de refactor. Você diz o que quer, ele implementa, você revisa e ajusta a direção. Mas se você não sabe pra onde ir, velocidade não ajuda — você só chega mais rápido no lugar errado.
As perguntas que eu fiz — sobre resiliência, cancelamento, multi-OS, degradação graceful, detecção de edge cases — nenhuma delas veio do LLM. Vieram de anos construindo software que precisa funcionar em ambientes reais, com usuários reais, em hardware diverso. O Claude não vai te perguntar “e se o usuário puxar o cabo de rede no meio do download do modelo?”. Mas se você perguntar, ele implementa o tratamento em minutos.
É tentador olhar pra esse projeto e concluir que qualquer pessoa com uma boa ideia poderia ter feito o mesmo. Mas tente imaginar: sem a decisão de fazer benchmarks, eu teria escolhido o modelo errado. Sem o PoC em Python, teria descoberto os problemas de JSON parsing em produção. Sem a abstração de plataforma, estaria debugando issues de Windows espalhadas por 15 arquivos. Sem o checkpoint de scan, usuários perderiam horas de processamento a cada crash. Sem a migração formal de schema, a primeira atualização quebraria o banco de todo mundo.
Pense num arquiteto com uma equipe de construção absurdamente eficiente. O arquiteto não precisa levantar cada parede, mas precisa saber onde elas vão e o que acontece se você tirar uma. A equipe executa rápido, trabalha de noite, não reclama. Mas alguém precisa ter desenhado a planta. Sem planta, é só um monte de tijolos empilhados rápido.
Números Finais
Pra quem gosta de números concretos:
| Métrica | Valor |
|---|---|
| Commits | 50 |
| Horas de trabalho efetivo | ~26h |
| Linhas de Rust | 8.359 |
| Linhas de TypeScript | 5.842 |
| Linhas de CSS | 1.649 |
| Testes Rust | 166 |
| Testes frontend | 172 |
| Testes total | 338 |
| Plataformas | 3 (Linux, macOS, Windows) |
| Migrações de banco | 5 |
| Módulos Rust | 13+ |
| Componentes React | 15+ |
| Hooks React | 10+ |
O primeiro commit foi sexta-feira 21/02 às 19:29. O último foi segunda-feira 23/02 às 14:33. Descontando sono (~8h na noite de sábado/domingo, ~8h na madrugada de domingo/segunda) e pausas, são ~26 horas de trabalho distribuídas em um fim de semana.
De zero — sem um único arquivo no repositório — a binários publicados para 3 sistemas operacionais, com testes automatizados rodando no CI a cada push. Incluindo a fase de pesquisa, que sozinha justificaria um sprint.
Conclusão
Agile Vibe coding funciona. Mas funciona como qualquer ferramenta poderosa: nas mãos de quem sabe o que está fazendo.
A ideia do Frank Sherlock caberia num tweet: “classificar imagens com LLM local”. Mas transformar isso em software real exigiu: pesquisa benchmarked com ground truth formal, prova de conceito validando o pipeline completo, arquitetura incremental, tratamento de erros em 3 níveis, cancelamento cooperativo, migração formal de schema, abstração de plataforma, CI/CD com matrix de 3 OS, integração com 3 sistemas externos com graceful degradation, e 338 testes pra garantir que nada disso quebra quando alguém fizer cargo update.
O LLM acelerou tudo isso absurdamente. Mas não substituiu a necessidade de saber o que fazer. Se eu tivesse pedido “faz um app que classifica imagens” sem as 2 horas de benchmark, sem a prova de conceito, sem as decisões de arquitetura, sem as perguntas chatas sobre edge cases, o resultado seria um protótipo que funciona na minha máquina e quebra em qualquer outro lugar. E provavelmente eu nem perceberia até alguém reclamar.
O vibe precisa de um condutor experiente. Por enquanto, esse condutor ainda é humano.
Código em github.com/akitaonrails/FrankSherlock. GPL-3.0, local-only, open source.