Testes de Integração em MonoRepo | Bastidores do The M.Akita Chronicles
Este post vai fazer parte de uma série; acompanhe pela tag /themakitachronicles. Esta é a parte 8.
E não deixe de assinar minha nova newsletter The M.Akita Chronicles!
–
Testes unitários são a zona de conforto de todo desenvolvedor. Você mocka tudo, isola tudo, roda em milissegundos, e o verde no terminal te dá uma falsa sensação de segurança. Até o dia que você deploya e descobre que o serviço A grava num formato que o serviço B não consegue ler. Ou que o RSS do Hacker News mudou de Atom pra RSS e seu parser explodiu. Ou que a Yahoo Finance começou a retornar 429 depois do terceiro ticker porque o rate limit que funcionava em teste não existe na vida real.
Testes unitários provam que as peças funcionam isoladas. Testes de integração provam que o sistema funciona. E num projeto com múltiplas aplicações compartilhando dados via filesystem, a diferença entre os dois é a diferença entre “o código compila” e “a newsletter chega na inbox”.
O Problema: Três Apps, Um Filesystem, Zero Garantias
O projeto tem uma arquitetura incomum: três aplicações Rails/Hugo num monorepo, integradas via um diretório content/ compartilhado:
akitando-news/
├── marvin-bot/ # Gera conteúdo (Discord bot, AI, scraping)
├── newsletter/ # Monta e envia a newsletter
├── blog/ # Hugo + Hextra → Netlify
├── podcast-tts/ # Servidor TTS (Python/FastAPI)
└── content/ # Markdown + YAML, a cola entre tudoO marvin-bot escreve Markdown com frontmatter YAML em content/anime/, content/hacker_news/, etc. O newsletter lê esses arquivos pra montar a newsletter. O blog serve o mesmo conteúdo como páginas estáticas. O podcast lê a newsletter montada pra gerar o script de diálogo.
O contrato entre esses sistemas é implícito. Não tem schema. Não tem API versionada. Não tem protobuf. O contrato é: “o arquivo Markdown tem esse frontmatter, com esses campos, nessa estrutura”. Se o marvin-bot muda o formato de um campo — digamos, muda image de string pra array — o newsletter quebra silenciosamente. Nenhum teste unitário de nenhum dos dois apps detecta isso.
Essa é a falha fundamental de testar sistemas distribuídos com testes unitários: você está testando cada lado do contrato separadamente, mas nunca o contrato em si.
Camada 1: Testes Unitários com Isolamento Paranoico
Antes de falar de integração, preciso explicar o que os testes unitários fazem nesse projeto — porque sem essa base, os testes de integração não teriam onde pisar.
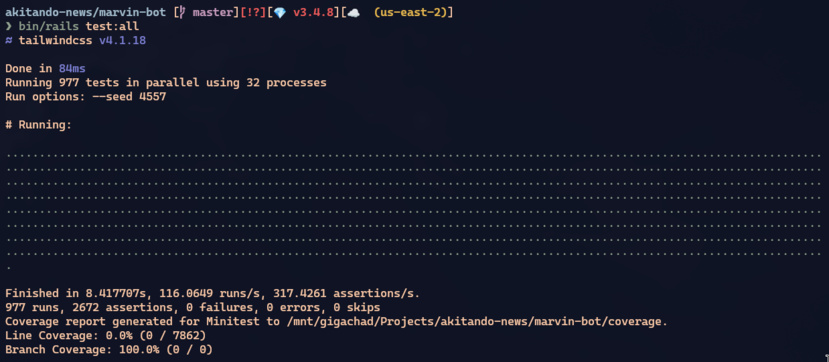
Os 977 testes do marvin-bot rodam em paralelo usando todos os cores da máquina. Cada worker de teste tem seu próprio diretório:
parallelize(workers: :number_of_processors)
parallelize_setup do |worker|
Rails.application.config.content_dir =
Rails.root.join("tmp", "test_content_w#{worker}").to_s
endMas worker-level não é suficiente. Dentro de cada worker, múltiplos testes rodam sequencialmente — e se um teste deixa um arquivo em content/stories/, o próximo teste pode encontrar dados espúrios. A solução: um diretório único por teste:
setup do
@base_content_dir = Rails.application.config.content_dir
@test_content_dir = File.join(@base_content_dir, SecureRandom.hex(8))
Rails.application.config.content_dir = @test_content_dir
FileUtils.mkdir_p(File.join(@test_content_dir, "stories"))
FileUtils.mkdir_p(File.join(@test_content_dir, "newsletters"))
FileUtils.mkdir_p(File.join(@test_content_dir, "images"))
end
teardown do
FileUtils.rm_rf(@test_content_dir) if @test_content_dir
Rails.application.config.content_dir = @base_content_dir if @base_content_dir
endPresta atenção na linha do teardown que restaura @base_content_dir. Sem ela, o próximo teste criaria seu diretório dentro do diretório do teste anterior — tmp/test_content_w3/abc123/def456/ — e em 50 testes você teria um caminho com 50 níveis de profundidade. Aprendi isso perdendo uma tarde inteira debugando por que os testes ficavam cada vez mais lentos ao longo da suite.
Esse padrão — worker-level base + per-test subdirectory + restore no teardown — é idêntico nos dois apps. E é o que permite rodar 977 testes em 7 segundos com 32 workers paralelos.
A regra de ouro: o content_dir de teste NUNCA pode apontar pro ../content real. Se apontar, o rm_rf do teardown apaga os prompts de produção. Não é hipotético — aconteceu durante o desenvolvimento.
Camada 2: O Ambiente de Integração
Testes unitários mockam tudo: APIs externas, AI, Discord, SES. Isso é correto — você não quer gastar $2 em tokens do GPT-5.2 toda vez que roda bin/rails test. Mas significa que os testes nunca exercitam o pipeline real.
O projeto tem um terceiro environment além de development e test: integration. Não é test. Não é staging. É um modo específico pra rodar o pipeline completo com dados reais, usando APIs reais, mas sem mandar emails de verdade:
# config/environments/integration.rb
# Jobs rodam inline (perform_later vira perform_now)
config.active_job.queue_adapter = :inline
# Emails salvos em arquivo ao invés de enviados via SES
config.action_mailer.delivery_method = :file
config.action_mailer.file_settings = {
location: Rails.root.join("tmp/integration_emails")
}O queue_adapter = :inline é crucial. Em produção, perform_later enfileira o job no SolidQueue e um worker separado executa. Em integração, executa na hora, no mesmo processo. Isso transforma o pipeline assíncrono de produção num pipeline síncrono que você pode rodar, observar, e debugar sequencialmente.
O SES é substituído por escrita em disco — cada email vira um arquivo HTML em tmp/integration_emails/. Depois de rodar o pipeline, você abre esses HTMLs no browser pra validar visualmente que o email renderiza correto.
Camada 3: DevCache — LLM Não É Idempotente
Aqui está um problema que quem trabalha com IA em produção conhece: chamar o GPT-5.2 com o mesmo prompt duas vezes não retorna a mesma resposta. E cada chamada custa dinheiro. Se você está iterando no pipeline de integração — rodando, ajustando um prompt, rodando de novo — gastar $3 por iteração fica caro rápido.
A solução é o DevCache: um cache file-based que só ativa no env de integração:
module DevCache
CACHE_TTL = 1.day
CACHE_ENVS = %w[integration].freeze
def self.fetch(namespace, key)
return yield unless enabled?
path = cache_path(namespace, key)
if path.exist? && File.mtime(path) > CACHE_TTL.ago
return JSON.parse(path.read, symbolize_names: true)
end
result = yield
path.write(JSON.generate(result))
result
end
endEm produção e em test, DevCache.fetch executa o bloco direto. Em integração, salva o resultado como JSON e retorna o cached na próxima execução. TTL de 1 dia — suficiente pra iterar no mesmo dia sem recalcular, curto o bastante pra não servir dados velhos.
O código de geração usa assim:
summary = DevCache.fetch("summarize", url_key) do
AiChat.summarize(article[:content], source_url: url)
endPrimeira execução: chama o GPT-5.2, paga $0.02, salva em tmp/dev_cache/summarize/{md5}.json. Segunda execução: lê do cache, custo zero. O FORCE=1 busta o cache quando você quer forçar regeneração — mas como flag explícita, não como default.
O DevCache existe em ambos os apps (marvin-bot e newsletter) com implementação idêntica. Quando roda integration:clean, ambos os caches são limpos.
Ponto: cache de LLM em ambiente de desenvolvimento não é otimização — é requisito. Sem ele, iterar num prompt que precisa de 8 chamadas de API fica financeiramente inviável.
Camada 4: Dados Reais via Rsync
Aqui é onde a maioria dos projetos para. Eles têm testes unitários, talvez um ambiente de staging, e mandam pro ar. O problema: staging usa dados de teste. Dados de teste são limpos demais. Não têm os edge cases que dados reais têm:
- Artigos com títulos em japonês (anime ranking)
- URLs que redirecionam 3 vezes antes de chegar no destino
- Imagens que retornam 200 com Content-Type
text/html(CloudFlare error page) - Newsletters anteriores com formatos de frontmatter ligeiramente diferentes
- Stories com
score: nullporque foram criadas antes de o campo existir
A solução: rsync de produção.
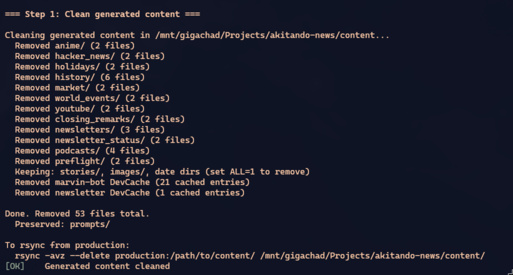
# Limpa conteúdo gerado (preserva stories e imagens de produção)
cd marvin-bot && bin/rails integration:clean
# Sincroniza content/ de produção pra local
rsync -avz --delete production:/path/to/content/ ../content/
# Roda o pipeline completo com dados reais
RAILS_ENV=integration bin/rails integration:pipelineO integration:clean é cirúrgico: remove diretórios gerados (anime/, hacker_news/, newsletters/, podcasts/) mas preserva stories/ e images/ — que são dados submetidos pelo usuário via Discord. Depois do rsync, o diretório local é uma cópia exata da produção.
O pipeline então gera todas as seções a partir desses dados reais. Se um parser quebra com um título em coreano, você descobre aqui — não em produção às 17h de domingo quando os 8 jobs rodam em paralelo.
Camada 5: O Pipeline Completo
O coração do sistema de integração é o integration:pipeline. Ele simula a semana inteira de produção em uma execução:
RAILS_ENV=integration bin/rails integration:pipelineO pipeline roda em ondas, respeitando dependências:
Wave 1 (paralelo, 8 jobs):
Book, Holidays, History, Geek History,
Anime, Hacker News, YouTube, World Events
Wave 2 (depende de World Events):
Market Recap
Wave 3 (depende de tudo):
Closing Remarks
Preflight → Newsletter Assembly → Podcast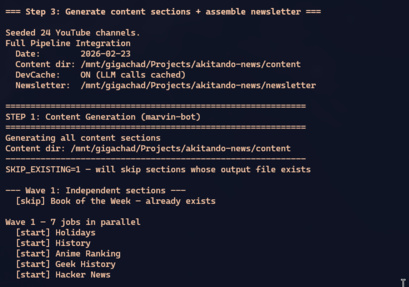
Cada wave roda seus jobs em threads paralelas, exatamente como a produção faz com SolidQueue. A execução paralela não é um detalhe de implementação — é uma feature de teste. Se dois jobs tentam escrever no mesmo arquivo, ou se um job lê um arquivo que outro está no meio de escrever, o bug aparece aqui.
threads = to_run.map do |name, klass|
Thread.new do
ActiveRecord::Base.connection_pool.with_connection do
run_single_job(name, klass, target_date, results)
end
end
end
threads.each(&:join)O with_connection é necessário porque cada thread precisa de sua própria conexão SQLite — sem ele, conexões vazam e o pool esgota.
Ao final, o pipeline imprime uma tabela de status e um resumo de billing:
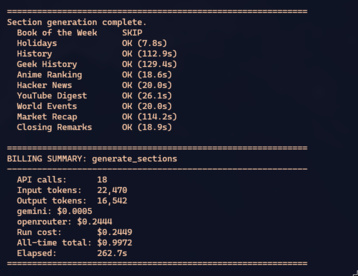
Esse billing summary não é vaidade — é controle de custos. Se um prompt refatorado aumenta o output tokens em 3x, você vê aqui antes de ir pra produção e gastar 10x num domingo com 200 stories.
Camada 6: Preflight — Validação Estrutural Automatizada
Depois de gerar todas as seções, o pipeline roda o ContentPreflight. Ele não valida o conteúdo — valida a estrutura. Cada seção é checada:
- Arquivo existe? Se
content/anime/2026-02-16.mdnão existe, algo falhou. - Item count mínimo? A seção de anime precisa de pelo menos 3 itens. Se tem 1, o gerador teve um problema.
- Markers obrigatórios? O Markdown precisa ter
[COMMENTARY]e[AKITA]— sem eles, a newsletter assembly não sabe onde cortar. - Dados específicos? Market recap precisa de pelo menos 5 ticker rows.
O resultado é um status por seção: pass, degraded, fail, ou skip. O pipeline usa isso pra decidir se a newsletter pode ser montada automaticamente ou se precisa de intervenção humana:
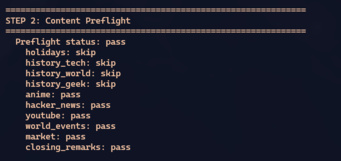
Em produção, esse resultado vai pro Discord como um embed. No pipeline de integração, é printado no terminal. A lógica é a mesma — o que muda é o canal de notificação.
Camada 7: Cross-App — Newsletter Assembly
Aqui está onde o monorepo paga dividendos. O marvin-bot precisa invocar o newsletter pra montar a newsletter final. Em produção, são servidores diferentes. No pipeline de integração, é um system() call:
env_vars = "RAILS_ENV=integration CONTENT_DIR=#{Shellwords.escape(content_dir)}"
cmd = "cd #{newsletter_dir} && #{env_vars} bin/rails integration:generate_all"
system(cmd)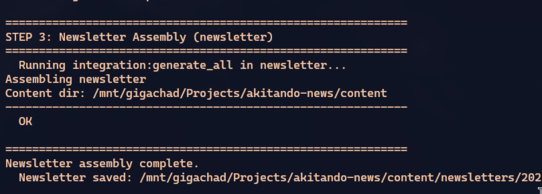
O newsletter lê os arquivos que o marvin-bot acabou de gerar em content/, monta a newsletter, e salva o resultado em content/newsletters/. O CONTENT_DIR é passado explicitamente — os dois apps apontam pro mesmo diretório.
Se o formato do frontmatter mudou e o newsletter não consegue parsear, o erro aparece aqui. Se o SectionParser do newsletter divergiu do SectionParser do marvin-bot (são cópias idênticas, mas manuais), aqui é onde você descobre.
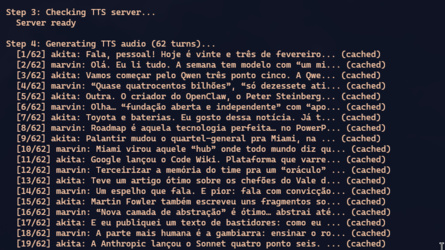
Depois da newsletter, o podcast: o pipeline invoca podcast:integration, que gera o script de diálogo a partir da newsletter montada, sintetiza o áudio via TTS, e monta o MP3 final. É o pipeline mais longo — de newsletter Markdown a MP3 pronto pro Spotify, passando por LLM de duas passadas e síntese de voz por turn.
O Valor de Testar com Dados de Produção
Vou dar exemplos concretos de bugs que só apareceram com dados reais:
1. Títulos de anime em japonês quebravam o slugify.
O ContentWriter.slugify usava parameterize do Rails, que strip caracteres non-ASCII. Título: “進撃の巨人 Season 4” → slug: “season-4”. Dois animes com subtítulo “Season 4” collidiam no filesystem. Nunca apareceu em teste porque os fixtures usavam títulos em inglês.
2. O parser de HackerNews assumia RSS, mas o feed mudou pra Atom.
rss/channel/item virou feed/entry. Testes unitários mockavam o XML. O parser em si nunca foi testado contra o feed real. Na integração com rsync do feed real, o parser retornou zero itens — detectado pelo preflight como fail.
3. Yahoo Finance retornava 429 depois do 5º ticker. O rate limiting não existia em teste (HTTP era mockado). Na integração real, os primeiros 5 tickers passavam, depois tudo falhava. A solução — sleep entre requests — nunca seria implementada sem dados reais revelando o problema.
4. Imagens com URL válida mas Content-Type errado.
Uma CDN retornava 200 para URLs de imagem, mas com body HTML (Cloudflare error page). O UrlValidator.reachable? retornava true. O ImageProcessor.download_image baixava o HTML e tentava redimensionar. O mini_magick crashava com um erro obscuro. O fix: validar Content-Type no HEAD response — mas esse cenário nunca apareceria com URLs mockadas.
5. O newsletter assembly falhava com stories que tinham score: null.
Stories antigas, criadas antes do campo score ter um default, tinham nil no frontmatter. O assembly tentava fazer sort_by { |s| s[:frontmatter]["score"] } — nil <=> "high" levanta ArgumentError. Só apareceu quando rsynquei dados de produção que tinham 3 meses de stories acumuladas.
Nenhum desses bugs seria pego por teste unitário. Todos foram pegos pelo pipeline de integração com dados reais.
Dicas Práticas
1. Separe Custo de Fidelidade
O pipeline de integração completo custa ~$0.40 em API calls. Não é muito, mas se você roda 10 vezes num dia iterando, são $4. O DevCache resolve isso: primeira execução paga, as seguintes são grátis.
Mas tem cenários onde você quer pagar de novo — quando muda um prompt e precisa ver o resultado real. O FORCE=1 busta o cache seletivamente. E o SKIP_EXISTING=1 pula seções que já foram geradas, economizando tempo quando você só quer re-rodar uma seção específica.
2. O Integration Environment Não É Staging
Staging é um servidor que roda 24/7 simulando produção. O integration environment é um modo de execução local que você liga quando precisa e desliga quando terminou. Não precisa de infraestrutura dedicada. Não precisa de database separado. É o mesmo código, na mesma máquina, com flags diferentes.
A diferença é filosófica: staging testa “o sistema funciona no servidor de staging?”. Integration testa “o sistema funciona com esses dados específicos?”. O primeiro é environment-dependent. O segundo é data-dependent. E bugs de dados são mais comuns que bugs de environment.
3. Clean Antes de Rsync, Não Depois
A ordem importa: limpe o conteúdo gerado antes de sincronizar de produção. Se fizer o contrário — rsync primeiro, clean depois — você perde os dados de produção que acabou de baixar.
O integration:clean é cirúrgico por design. Remove anime/, hacker_news/, newsletters/ (gerados), mas preserva stories/ e images/ (produção). Isso permite um workflow iterativo: rsync uma vez, roda o pipeline, ajusta um prompt, roda de novo — sem re-baixar 500MB de content.
4. Preflight É Seu Smoke Test
Não confie que “rodou sem exceção = está correto”. Um job de geração pode rodar, produzir um Markdown com 2 itens ao invés de 10, e retornar sucesso. O preflight detecta isso verificando contagens mínimas, markers obrigatórios, e estrutura esperada.
Na prática, todo bug de LLM que encontrei foi detectado pelo preflight: respostas truncadas, formato errado, seções faltando. O GPT-5.2 é bom, mas não é determinístico — e quando erra, erra de formas criativas que nenhum schema validation pegaria.
5. Billing Summary Não É Opcional
Se você está usando LLM em produção, todo pipeline de teste precisa reportar custo. Não por contabilidade — por engenharia. Um prompt que funciona mas custa 3x mais que o anterior é um bug de performance. Tokens de input e output por provider, custo por job, custo total — tudo visível a cada execução.
6. Monorepo Facilita, Mas Não Resolve
Ter os três apps no mesmo repositório facilita: um git bisect cobre mudanças em ambos os lados do contrato. Um PR que muda o formato do frontmatter no marvin-bot pode também atualizar o parser no newsletter — no mesmo commit.
Mas “pode” não é “garante”. O contrato entre os apps é file-based e implícito. Não tem tipo compartilhado, não tem interface comum. O SectionParser é copiado manualmente entre os dois apps. Se alguém edita um e esquece do outro, divergem. O teste de integração é a única verificação de que os dois lados concordam.
7. Preview Antes de Enviar
O pipeline não termina na geração. O newsletter tem um newsletter:preview que renderiza o resultado final em HTML light e dark:
cd newsletter
FILE=../content/newsletters/2026-02-16.md bin/rails newsletter:preview
# → tmp/preview/newsletter_light.html
# → tmp/preview/newsletter_dark.htmlAbrir esses HTMLs no browser é o teste de integração visual. O Markdown pode estar perfeito, o frontmatter correto, todos os campos presentes — mas a imagem de um anime aparece esticada porque o aspect ratio mudou. Ou o bloco de comentário do Marvin não tem contraste suficiente no dark mode. Esses bugs são visuais — nenhum teste automatizado pega.
8. O Pipeline de CI É Diferente do Pipeline de Integração
São coisas diferentes. CI roda em todo commit:
bin/ci # rubocop + bundler-audit + brakeman + tests (~22s)Integração roda quando você quer validar o pipeline end-to-end — antes de um deploy, depois de mudar prompts, ou depois de rsync de dados novos de produção. CI é rápido e barato. Integração é lento e custa dinheiro. Os dois são necessários.
O Custo de Não Ter Integração
Vou ser direto: se esse projeto não tivesse o pipeline de integração, eu teria enviado pelo menos 3 newsletters quebradas.
Uma com seção de anime faltando porque o parser de XML assumia RSS e o feed era Atom. Uma com todas as imagens de YouTube apontando pra 404 porque o padrão de URL de thumbnail mudou. E uma com o market recap mostrando tickers do mês passado porque o Yahoo Finance bloqueou as requests e o job falhou silenciosamente.
Testes unitários teriam passado em todos esses cenários. O CI teria dado verde. O deploy teria ido pro ar. E às 7 da manhã de segunda-feira, 300 pessoas teriam recebido uma newsletter com buracos.
O pipeline de integração é caro — em tempo de setup, em custo de API, em complexidade de manutenção. Mas é ordens de magnitude mais barato que enviar conteúdo quebrado pra assinantes reais. Especialmente quando você só tem uma chance por semana.
Conclusão
A hierarquia de testes nesse projeto é:
- Testes unitários (1.330 nos dois apps, 7 segundos em paralelo, $0): prova que cada peça funciona isolada
- CI pipeline (rubocop + audit + brakeman + tests, ~22 segundos, $0): prova que o código está saudável
- Pipeline de integração (dados reais, APIs reais, ~3 minutos, ~$0.40): prova que o sistema funciona
- Preview visual (HTML no browser, manual, $0): prova que o resultado final é apresentável
Cada camada pega um tipo diferente de bug. Nenhuma sozinha é suficiente. E a que mais surpreende — a que pega os bugs que você jurava que não existiam — é a terceira: dados reais, pipeline real, sem mocks.
A confiança que você tem no seu sistema é proporcional ao quão reais são os dados nos seus testes. Mocka tudo e você tem 100% de coverage e zero de confiança. Testa com dados de produção e você tem a verdade — por mais inconveniente que seja.