Vibe Code: Qual LLM é a MELHOR?? Vamos falar a REAL
Esta é a pergunta que não quer calar:
“Eu, como um total zero à esquerda em programação, quero fazer um app perfeito, seguro, de qualidade, somente com prompts. Qual LLM vai me atender?”
A minha resposta de 2 anos atrás e até agora continua sendo:
NENHUMA!
Ontem eu fiz um LONGO artigo onde eu DEMONSTRO como é fazer um appzinho do zero somente com Vibe Coding. Um escopo menor que um exercício de “to-do list”.
Pra “fazer funcionar” foi fácil: em 1 hora eu tinha o app. O tal “zero à esquerda” acima, pararia aqui.
Mas pra fazer um código de qualidade, seguro, otimizado, testado, etc, me custou as próximas 12 horas e mais de 250 prompts e intervenções manuais.
Quando postei, alguns ainda vieram “Ah, mas você usou GLM, se tivesse usado Claude Code ou Codex, teria sido mil vezes melhor.”
Ok, engoli o bait.
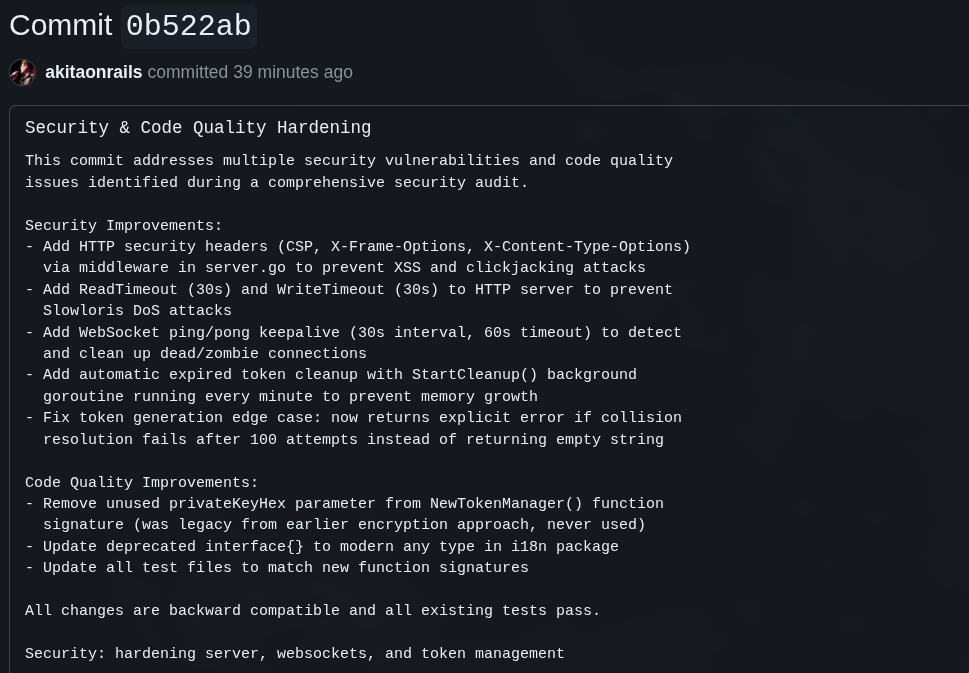
Hoje eu passei mais umas boas 2 horas em cima do código final do GLM e fiz o seguinte:
Mandei o Claude Code fazer uma análise EXTENSIVA de segurança, otimização, testes, etc e ele saiu com este commit
Em cima disso que o Opus corrigiu, pedi pro GPT 5.2 Codex fazer a mesma análise EXTENSIVA. E ele saiu com este commit
Não satisfeito, e vendo que acabou de sair o Kimi 2.5, pedi a ele pra fazer a mesma análise EXTENSIVA. E ele saiu com este commit
Mas pra garantir mesmo, a seguir pedi ao Gemini 3.0 Preview a mesma análise EXTENSIVA. E ele saiu com este commit
Não resisti e quis terminar mandando o MiniMax v2.1 também participar fazendo a mesma análise EXTENSIVA. E ele saiu com este commit
Estão entendendo??? LET THAT FUC–NG SINK IN!!
NENHUM é capaz de fazer um appzinho menor que um to-do list da forma perfeita. Isso não existe.
A única coisa que existe são seus requerimentos. A qualidade do app é diretamente proporcional à sua senioridade!
Quanto mais júnior você for, pior vai ser seu app, com ou sem IA. Quanto mais sênior você for, melhor vai ser seu app, com ou sem IA. A IA é correlacionada diretamente com seu conhecimento E sua experiência.
IAs não são gênios com vontade própria. Elas não vão adivinhar o que você QUER e nem o que você REALMENTE PRECISA.
O que você QUER e o que você PRECISA costumam ser BEM diferentes.
Não adianta colocar segurança da NASA num sistema que não precisa. Não adianta deixar senha de admin aberta e colocar em produção. Você precisa saber quais são os limites certos pro seu caso de uso particular.
IAs são máquinas de probabilidade, cuspidores de texto glorificados, sem nenhuma inteligência. Elas nunca vão alcançar 100% porque isso é impossível.
E eu digo “matematicamente” impossível. Isso porque a quantidade de esforço/recursos necessários pra subir cada por cento nessa escala, aumenta exponencialmente. Como se diria em Cálculo “no limite”, o 100% vai pra infinito.
Então sempre necessariamente vai ser “abaixo de 100%”.
Os 99% do esforço servem pra fazer um app to-do list mínimo. O resto do caminho: escalabilidade, otimização, segurança, mantenabilidade, etc dependem unicamente de quem está pedindo: você.
Russian Doll de LLMs
Essa brincadeira de Opus ➡️ GPT 5.2 ➡️ Kimi 2.5 ➡️ Gemini 3 Pro ➡️ MiniMax V2.1 foi até barato, no total só uns USD 3. Mas novamente, é um app menor que um to-do list. “Deveria” ter sido trivial pra qualquer um deles, não acham?
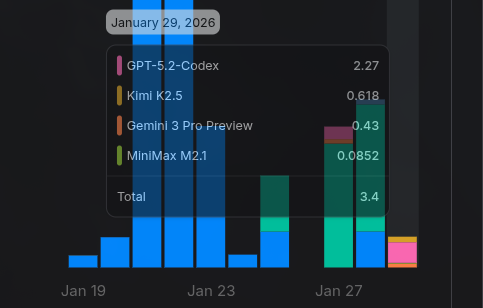
Vamos rapidamente dar uma olhada no que as LLMs fizeram depois que meu appzinho já estava pronto.
Pra quem não viu o artigo anterior, o código final está neste GitHub.
1. Opus 4.5
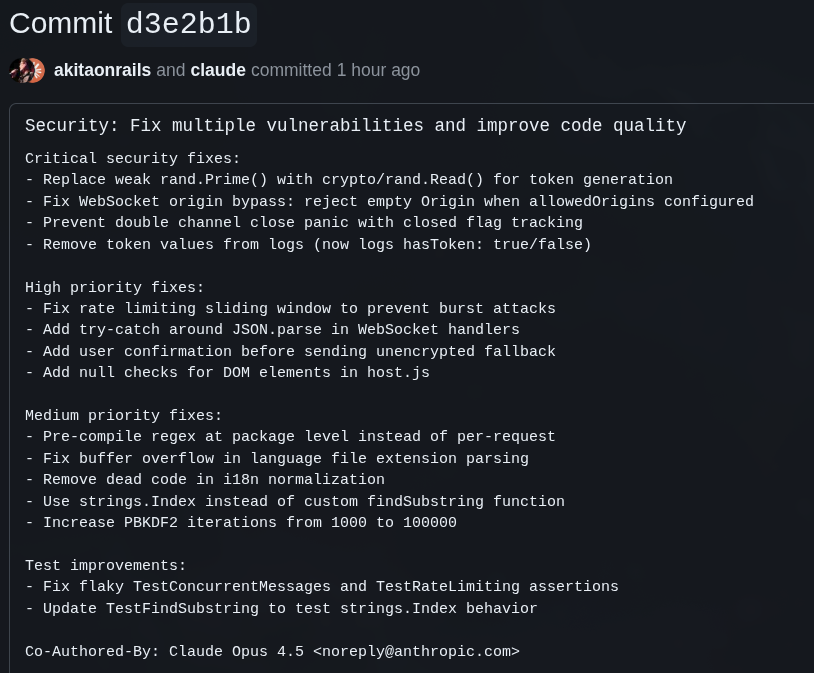
Já tinha dito isso antes e repito, na dúvida, use Claude Code. É o melhor balanceado entre velocidade e qualidade. Se usar o plano Max, também é um bom custo-benefício. Concordo que ele é superior ao GLM 4.7, isso nunca foi uma questão.
Ao mesmo tempo, não é mágica e nem é infalível, muito longe disso. O processo todo que descrevi no artigo anterior vai ser exatamente o mesmo, só vai demorar bem menos (custando menos da minha paciência).
O GLM realmente apanhou muito na checagem de CORS e como o Opus demonstra, ainda sobraram bugs nessa checagem.
O Opus ajustou algumas coisas que são ok, mas desnecessárias. Melhorar a criptografia da comunicação não era necessária, porque era só uma obfuscação. A encriptação de verdade sempre vai ser TLS. Mas tudo bem, é bom manter ajustado.
Mas o que o GLM deixou passar reto e o Opus também é que na primeira versão o token era encriptado porque ia na URL, mas depois que mudamos pra server-side, não precisava mais. Mas ainda “sobrou” código velho disso, e o Opus, em vez de remover, tentou melhorar esse código velho!!
Deveria ser óbvio que não precisa: é server-side, o novo token é só um ID aleatório. Não tem nenhuma necessidade de manter um timestamp encriptado no servidor.
Ele também quis consertar a possibilidade de overflow na hora de carregar arquivo de I18n. Mas isso é algo que eu controlo, não o usuário. Não tem como ter overflow. É overengineering, mas tudo bem também.
Opus tende a ser proativo demais em aspectos que costumam ser desnecessários, dando impressão que é mais inteligente do que realmente é.
Sabe aquele estagiário chato que lê muito blog post e em toda reunião fica soltando coisas aleatórias pra mostrar que sabe? Mas que na prática não faz nenhuma diferença? Pois é, é isso.
2. GPT 5.2 Codex
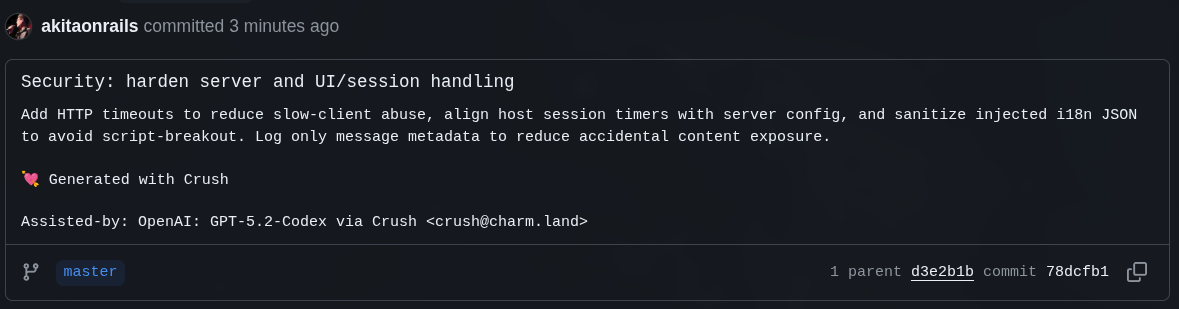
Apesar de ser OpenLieAI, eu acho o GPT 5.2 Codex mais “honesto” do que o Opus. Ele não tenta ser tão smartpants o tempo todo, querendo se mostrar onde não precisa. Eu acho que ele vai mais direto ao ponto e segue mais de perto exatamente o que eu pedi, em vez de tentar fazer tangentes que eu não pedi - e acabam sendo desnecessárias.
Só desta vez, sei lá porque, ele fez o pior commit message de todos (super curto e sem explicação). Mas ele achou uma coisa bem idiota que GLM e Opus não prestaram atenção: configuraçãozinha boba de timeout:
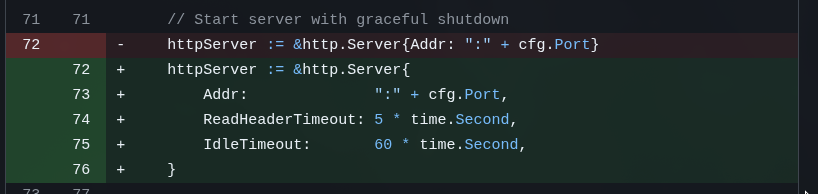 Pro meu app, não é necessário. Mas neste estágio que eu realmente pedi pra analisar EXTENSIVAMENTE, me surpreende que o prolixo do Opus deixou passar isso.
Pro meu app, não é necessário. Mas neste estágio que eu realmente pedi pra analisar EXTENSIVAMENTE, me surpreende que o prolixo do Opus deixou passar isso.
E o GPT esbarrou no problema que falei acima do token encriptado: tive que interromper quando ele começou a tentar reimplementar a encriptação porque viu sobras do passado. Nesse caso eu mandei explicitamente remover essas sobras. Mas nem GLM, nem Opus e nem GPT se ligaram que isso não era mais necessário e continuaram tentando mexer nessa sobra velha.
3. Kimi 2.5
Toda semana surge mais uma versão nova que todo mundo fica hypando. 3 semanas atrás era MiniMax v2.1, 2 semanas atrás era GLM 4.7, agora é Kimi 2.5, então resolvi testar ele pelo OpenRouter. E o TL;DR é que eu gostei dele.
Achei mais lento que Opus ou GPT, mas melhor que GLM. E ele realmente continuou achando itens que não sei como o Opus deixou passar.
Novamente, é uma coisa besta e desnecessária pro meu appzinho, mas ninguém até agora se preocupou em configurar headers de segurança:
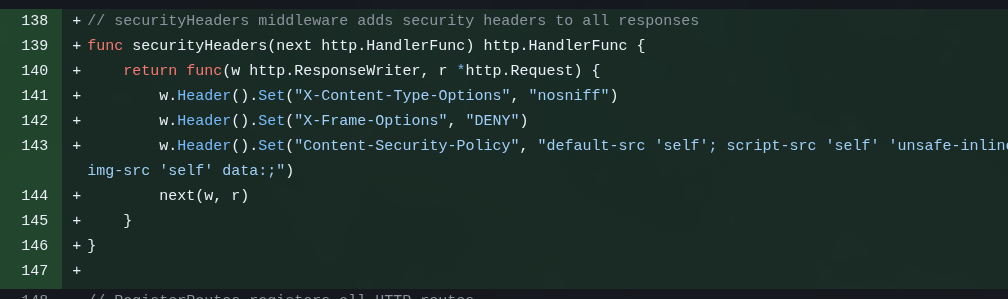
Em um web app de verdade, tem que colocar!
Outra coisa desnecessária mas que precisa num app de verdade: pattern de WebSocket Ping/Pong pra não desconectar se ficar idle:
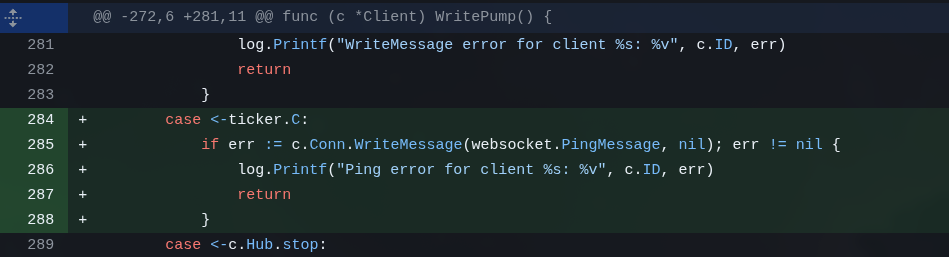
O interessante foi o Opus não ter sugerido isso. Viram? Ele é prolixo, fica sugerindo um monte de pequenas coisinhas desnecessárias pra parecer inteligente, mas as coisas realmente interessantes, ele não lembra.
Mas aí o Kimi também sugeriu colocar de volta uma funcionalidade que eu tinha mandado o GLM tirar: rotina de limpeza do storage de tokens in-memory:
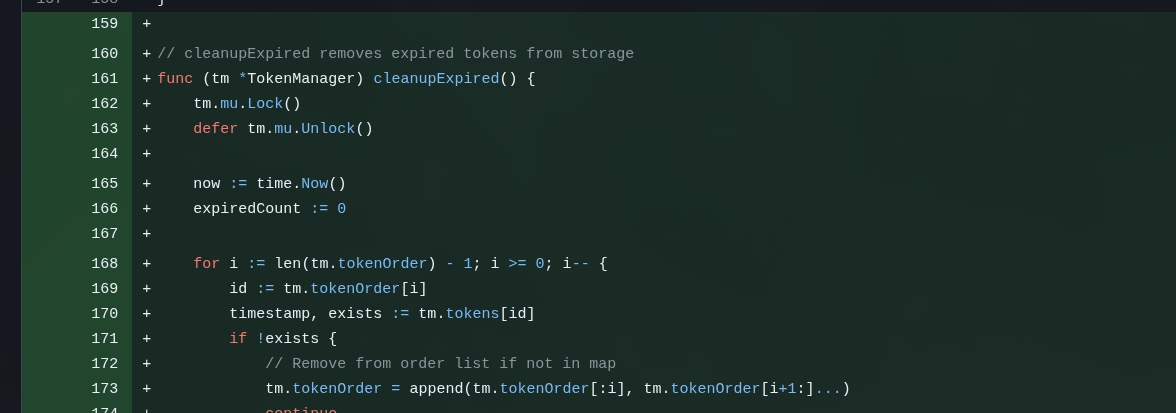
Como já expliquei: isso é server-side. Quando acabar espaço, automaticamente o novo token toma lugar do mais antigo e pronto. Mas o Kimi provavelmente ficou preocupado de deixar tokens expirados sobrando na memória. Só que é overengineering: é um storage hiper pequeno, kilobytes, talvez. Não precisa deixar uma rotina rodando em background pra ficar limpando uma lista em memória.
Mesmo num app de produção, eu não colocaria isso!
Teve um tweet de brincadeira sugerindo que o Kimi era uma versão pirata do Claude. Apesar de ser piada, esse comportamento de ficar implementando coisas desnecessárias que nem um estagiário que lê blog post e quer ficar se mostrando, é realmente bem parecido com o Claude. 😂
4. Gemini 3 Pro Preview
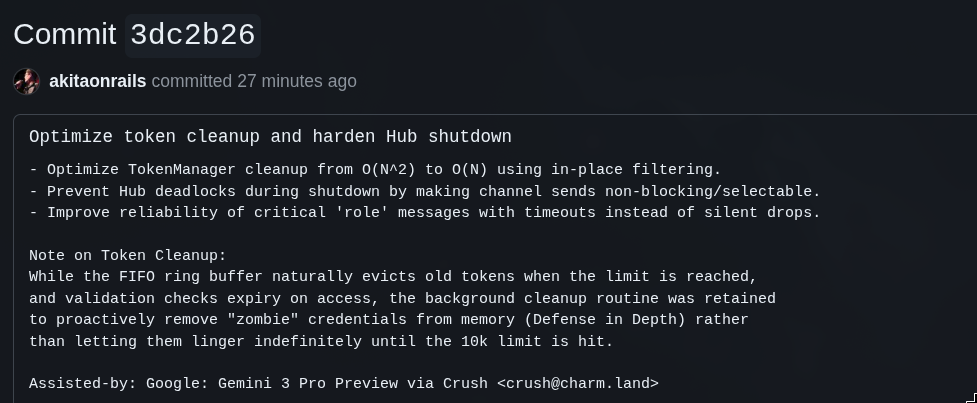
Diferente do Opus, assim como GPT, eu tendo a pensar no Gemini como sendo um pouco mais “honesto” e direto ao ponto também. Às vezes eu ainda pego ele se enrolando e sugerindo tangentes desnecessárias, mas no geral eu sinto que ele se prende ao meu prompt um pouco mais de perto mesmo.
No caso dele, além da análise, eu pedi explicitamente pra reavaliar a necessidade da rotina de cleanup que o Kimi adicionou a mais.
E o Gemini concordou com o Kimi e quis manter, e ainda otimizou a rotina!! 🤦♂️
Mas pelo menos ele ainda achou um deadlock durante o shutdown do servidor que ninguém antes pensou. Não é nada grave, e é só na situação de shutdown, mas mesmo assim, eu pedi uma análise EXTENSIVA de todos os anteriores, eles sugeriram coisas desnecessárias, e pularam isso. Num app de produção é importante ter esse cuidado. É o tipo de coisa que pode bloquear restart de containers em produção ou causar delays/timeout sem sentido.
5. MiniMax v2.1
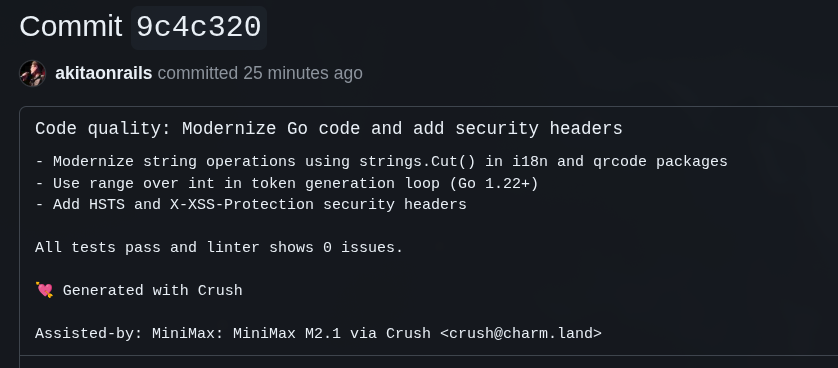
A esta altura eu realmente espero que não tenha mais muita coisa que precise mexer, mas o MiniMax ainda achou mais coisinhas bestas faltando.
O Kimi colocou headers de segurança faltando no servidor HTTP mas esqueceu de fazer o mesmo pra WebSockets:
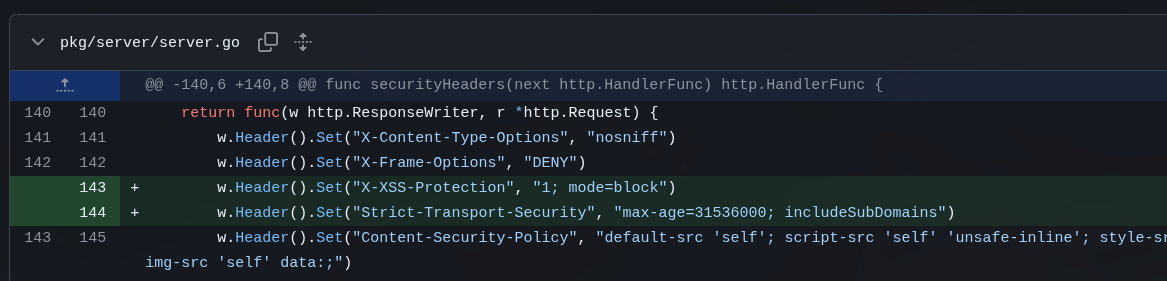
E a esta altura, 5 LLMs depois, ainda tem algumas besteiras de boas práticas de Go que todo mundo deixou passar. Esta bobagem, por exemplo:
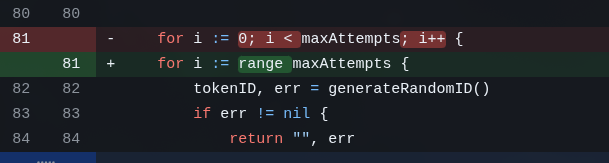
De novo: isso não é nada. Mas todo mundo checou, analisou, rodou linters e tudo mais e só o MiniMax consertou essa sobra. SEMPRE TEM SOBRA
Conclusão
Dá pra continuar, eu poderia continuar rodando mais LLMs em cima disso. Mas lembrem-se: isso tudo foi só em cima de um appzinho miseravelmente pequeno, menor que um to-do list. Imagine num app grande, complexo, com usuários de verdade, em produção?
Não subestimem programação, é muito mais complexo do que vocês, iniciantes, pensam.
Eu acabei de rodar o equivalente a dezenas de bilhões de dólares, devo ter queimado energia suficiente pra abastecer uma casa inteira nos datacenters da Z.AI, Anthropic, OpenAI, Google, etc e ainda assim, tem sobras.
E mesmo com tudo isso, eu não tenho confiança nenhuma de colocar este appzinho em público. Pro meu uso pessoal privado está overengineered, mas pra produção, eu ainda precisaria gastar horas de revisão manual e testes manuais, QA extensivo, scans de segurança e tudo mais pra garantir que não sobrou nada importante ainda.
LLMs são EXCELENTES, me ajudam muito. Mas são estagiários muito motivados, e não gênios que fazem tudo sozinhos. Longe disso.