Vibe Code: Eu fiz um appzinho 100% com GLM 4.7 (TV Clipboard)
Ontem eu postei o seguinte no X:
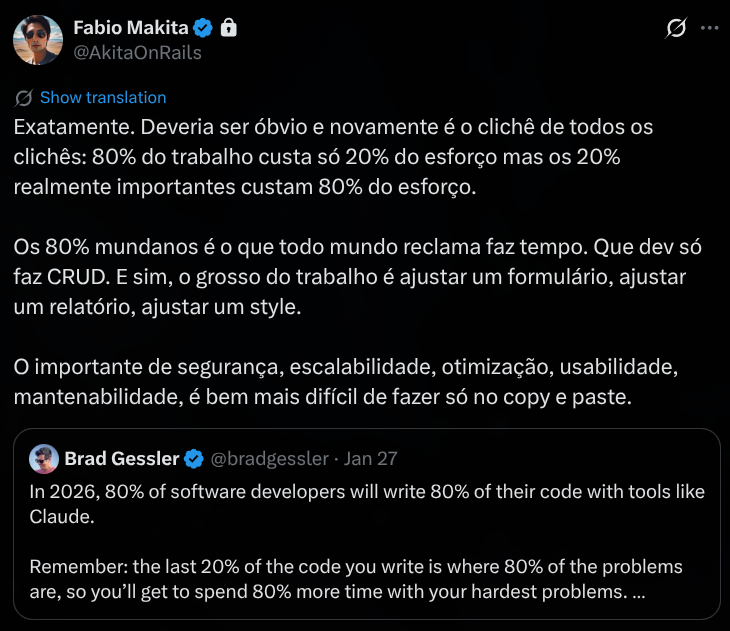 Isso é um conceito que falei múltiplas vezes nos vídeos do meu canal e em palestras. Tudo em programação acontece mais ou menos na proporção de Pareto: 80/20:
Isso é um conceito que falei múltiplas vezes nos vídeos do meu canal e em palestras. Tudo em programação acontece mais ou menos na proporção de Pareto: 80/20:
- 80% do código é “fácil” e normalmente feito em 20% do tempo. Os 20% mais importantes vão ocupar a maioria dos 80% do tempo total.
- Bugs e problemas como performance ou segurança, se consertar os top 20%, vai resolver 80% dos problemas gerais.
- 20% do escopo é realmente importante, por isso sempre dá pra simplificar, substituir, mudar, ou até cortar 80% - e é assim que se ajusta um projeto pra caber em orçamento/prazo.
Tudo é baseado em Top X. Aprender a priorizar é aprender a identificar os 20%. A diferença de alguém sênior/experiente vs alguém amador/iniciante, é que iniciantes acham que 100% é importante e não conseguem decidir os 20%. O que a experiência traz é a capacidade de cada vez separar mais rápido esses 20%.
PORÉM, é muito fácil só dizer isso. Todo mundo já ouviu isso pelo menos uma vez na vida, mas provavelmente ainda não consegue entender o que significa. Por isso resolvi fazer este (LONGO) artigo: vou mostrar na prática o que são os 80% fáceis e os 20% difíceis e como isso realmente afeta a qualidade do código, o tempo gasto e o custo.
Este artigo é para iniciantes, principalmente, mas também pra você: sênior que tem júniors pra mentorar ou professores com alunos. Usem como material de discussão e estudo com seus aprendizes. Esse é o tipo de coisa que se deve ensinar.
Como vai ser longo, lembrem-se que na versão desktop, do lado direito 👉 tem um menu com as seções pra pular direto pra cada assunto e estudar aos poucos.
O App: TV Clipboard
Escolhi um appzinho que eu queria faz tempo pro meu uso pessoal. É mais simples que um to-do list, não precisa de banco de dados nem nenhum outro serviço externo. Na prática é um comunicador peer-to-peer (p2p) via websockets.
O caso de uso é o seguinte: eu tenho um mini-PC gamer que conecto na TV da sala. Normalmente deixo um mouse do lado da poltrona pra navegar nele (é um maldito Windows 11). Mas eventualmente eu preciso digitar alguma coisa (senhas, preencher algum formulário). E eu não quero deixar minhas contas importantes logadas nesse PC (não confio em PC gamer).
Ou eu tenho que pegar meu teclado bluetooth, ou usar o teclado virtual do Windows. Ambas as opções são inconvenientes pra uma sala. MAS, e se eu pudesse abrir um site (que já vai estar no bookmark), aparece um QR Code que eu abro via meu smartphone e dali posso digitar ou colar o que está no meu clipboard mobile e transferir pro clipboard do mini-PC imediatamente? Esse é o app:
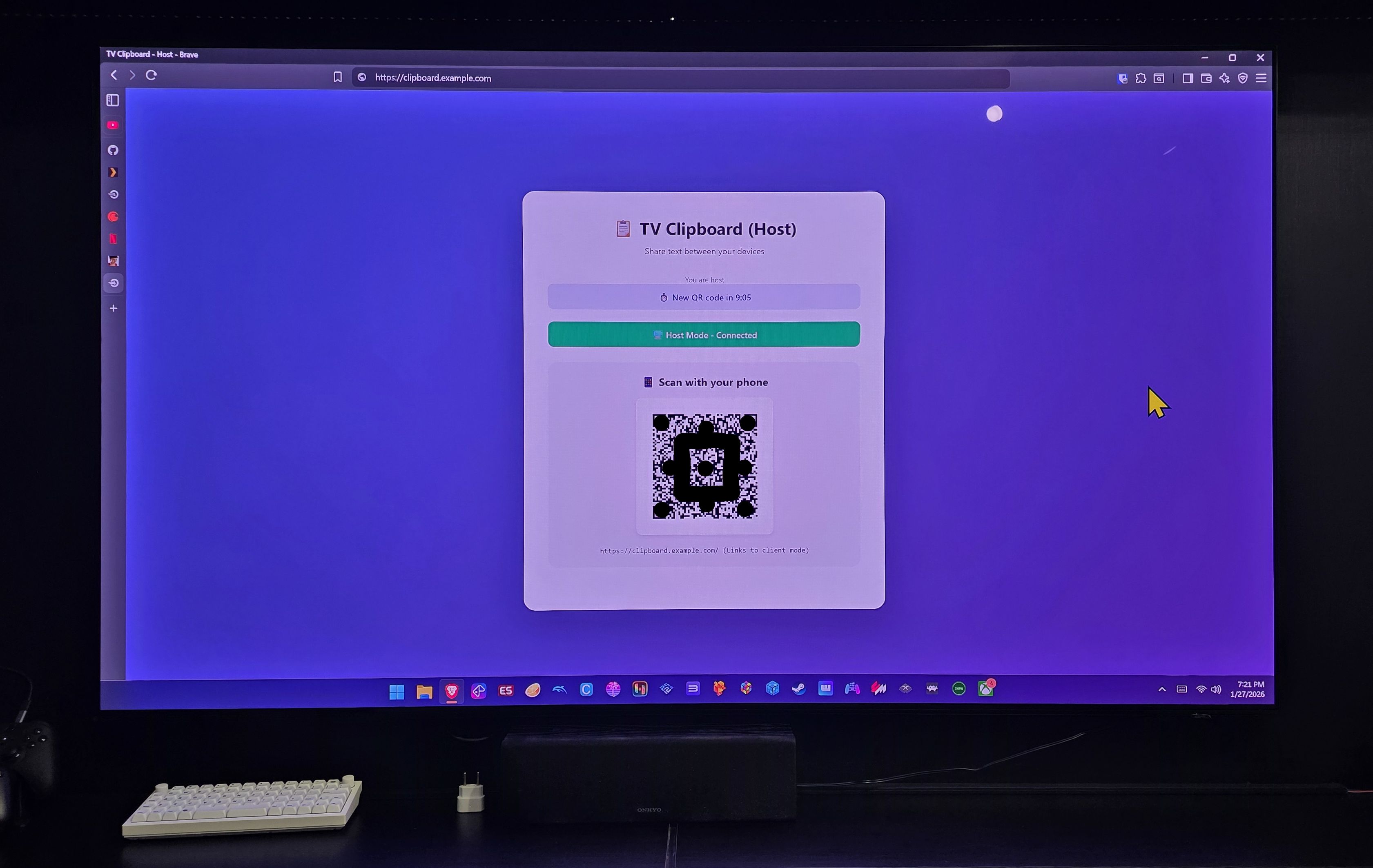
Daí eu abro a câmera do meu celular, escaneio esse QR Code e ele vai abrir esta página:
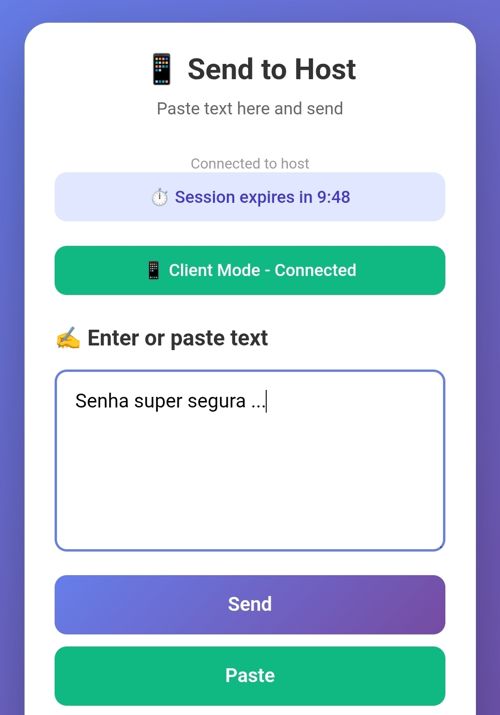
Pronto, agora posso digitar qualquer coisa ou colar a senha do meu gerenciador de senhas (clicando em “paste”) e quando enviar, na TV vou ver o seguinte:
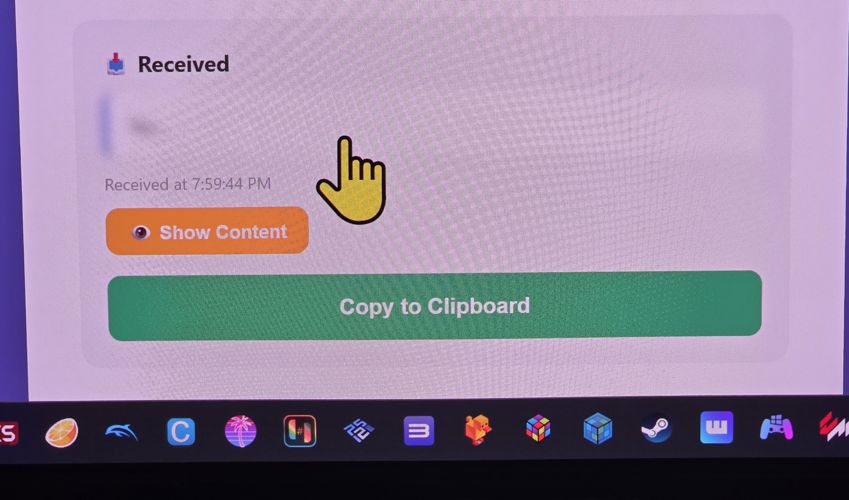
Vai aparecer que recebi, e automaticamente já vai pro clipboard da TV. Ele mostra “blurred” porque se for uma senha não quero que fique legível grande na TV - e sim, o mouse é gigante porque é mais fácil de eu ver na TV.
Isso é útil não só pra TV, mas pra qualquer situação onde eu queira mandar textos do meu celular pra um dos meus PCs também. Muita gente acaba usando WhatsApp ou outros comunicadores pra isso. Eu, por exemplo, tenho um grupo “Só eu” que só tem eu nele, pra ficar mandando links e coisas bobas do meu celular. Daí eu sempre deixo o WhatsApp Web aberto numa aba do meu PC e posso pegar de lá. WhatsApp pra mim é um clipboard remoto.
Mas isso não é seguro pra mandar coisas como senhas, endereços de cripto, ou qualquer outra mensagem mais sensível. WhatsApp é uma empresa sem nenhuma transparência. A propaganda “diz” que eles têm encriptação de ponta a ponta, mas eu não acredito nisso. É igualmente provável que eles abram tudo no meio do caminho e deixem registrado - são dados que valem dinheiro, ainda mais nesta era de treinamento de LLMs.
Recomendação: NUNCA COMUNIQUE NADA IMPORTANTE VIA WHATSAPP.
Pra transferir arquivos eu já uso LocalSend:
Daí que veio a inspiração: eu queria um LocalSend pra Clipboard. Eu tenho certeza que já existam dezenas de apps que fazem exatamente isso. Mas aí eu queria aproveitar pra fazer este exercício.
O Plano: 100% Vibe Code
Honestamente, eu sei o suficiente de front-end, comecei minha carreira sendo “web master” nos anos 90. Mas eu detesto front-end. É demorado, é trabalhoso, yuck. Em particular, detesto lidar com CSS. Em mais particular, não tenho prazer em fazer Javascript. Por isso, sempre tenho preguiça de começar um web app do zero. Mas com Vibe Coding, essa é uma das partes que eu já posso me livrar, especialmente se eu não me importo com a aparência exata que vai ficar, contanto que não fique torto.
Aproveitando, vou usar uma linguagem que eu sei o básico mas não tenho nem experiência suficiente e muito menos fluência (ou seja, sozinho eu seria lento): GoLang. Por que Go:
- compila binário nativo: eu nem preciso da performance mas ter um compilador vai ajudar a LLM ter feedback de erros óbvios.
- sem dependências: depois vou querer fazer deploy no meu home server, e vai ser infinitamente mais fácil fazer o setup de docker com um binário sem dependências, comparado com um Ruby ou Python que tem que instalar muita coisa.
- ferramental padrão completo: além de compilador ele já tem formatador, linter, testes e tudo mais que também vai dar bom feedback à LLM
- sintaxe simples, curta e pouco ambígua. Gosto como Go é Python-like. Não considero nenhuma das duas “bonitas” (em termos de estética, eu prefiro muito mais um Swift, Kotlin ou Ruby). Mas diferente de Javascript e até mesmo Rust, é bem menos “verbose” e bem menos ambígua.
- standard library rica. Diferente de Javascript, não precisa ficar instalando 500 libs externas pra coisas básicas.
- como vou usar websockets, channels de GoLang vão facilitar minha vida. O mecanismo assíncrono dele é mais simples, robusto e melhor do que reactor de Node.
- o mais importante: porque eu quero. É um projeto pessoal, que só eu vou usar, eu escolho o que bem entender e ponto final.
Aliás, como eu não sou fluente em Go, provavelmente vou deixar passar alguma má prática ou anti-pattern óbvio. Se isso acontecer, você que é sênior de Go, não deixe de comentar abaixo explicando o que acha.
Se quiserem já ver como ficou, o código todo está neste GitHub. Eu vou ficar linkando trechos dele o tempo todo.
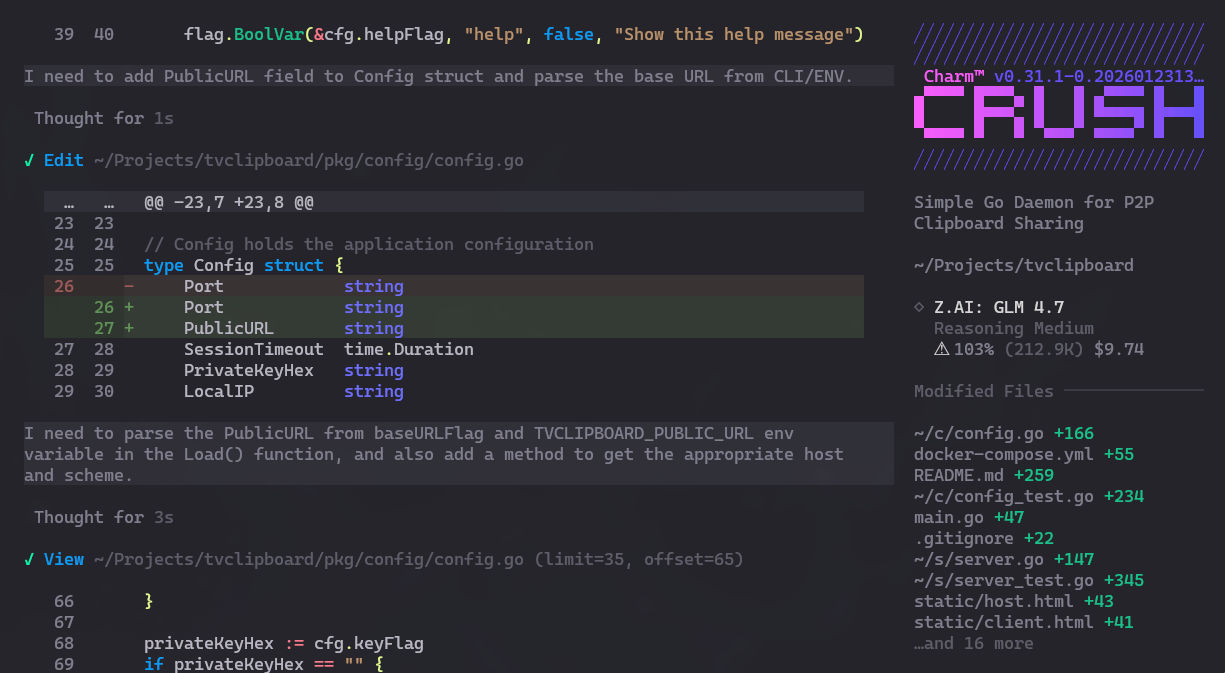
Outro objetivo é testar o quão bom o famoso GLM 4.7 realmente é. Já escrevi posts e tweets sobre ele antes. Já tentei rodar a versão Flash no meu PC local (é bom, mas BEM lento). No geral, minha impressão é que ele tem qualidade similar a um Claude Opus, GPT Codex, Gemini, mas é BEM mais lento (no mínimo 2x mais lento). Significa que se eu tivesse usado Gemini ou Claude, chegaria no mesmo resultado, mas talvez levasse metade do tempo, porém com um custo maior de tokens (GLM é mais “barato”).
Vamos ao TL;DR: ele conseguiu implementar o app como eu queria, mas DEMOROU. Eu levei um dia inteiro, almoçando e jantando na frente do PC enquanto o Crush ficava pensando, um total de mais de 10 HORAS. E, segundo o OpenRouter, gastei pouco mais de USD 40 (mais de 200 reais). Não foi nem rápido nem barato, considerando o escopo do app. Lembrando: é mais simples que um To-Do List.
Em termos de tamanho, mesmo um app simples destes deu mais de 3.000 linhas de código (LOC) de GoLang:
=== Code Statistics ===
Total Go code: 3493 lines
Production code: 1431 lines
Test code: 2062 lines
Test ratio: 1.44:1
Top 10 largest files:
3493 total
602 ./pkg/server/server_test.go
560 ./pkg/hub/hub_test.go
385 ./pkg/token/token_test.go
304 ./pkg/hub/hub.go
283 ./pkg/server/server.go
263 ./i18n/i18n.go
262 ./pkg/config/config_test.go
253 ./pkg/QR Code/QR Code_test.go
243 ./pkg/config/config.goE de Javascript deu mais de 1.000 LOC:
=== JavaScript Code Statistics ===
Total JavaScript code: 1360 lines
Production code: 787 lines
Test code: 573 lines
Test ratio: 0.73:1
All JavaScript files:
1360 total
573 static/js/test.js
313 static/js/client.js
249 static/js/host.js
114 static/js/common.js
111 static/js/i18n.jsAh sim, de curiosidade, adicionei scripts loc.sh e loc-js.sh pra fazer essa contagem.
Fase 1: Fazendo “Funcionar” - o que isso significa?
Diferente do que muitos amadores podem pensar, não basta digitar a descrição da aplicação (como eu fiz na seção anterior), como um prompt, jogar na LLM e ele vai automaticamente sair com um app que funciona: NÃO VAI.
É o que eu falava 2 anos atrás e continua sendo assim: não importa quanto mais as LLMs evoluírem. Eles podem ficar um pouco mais rápido, um pouco mais eficientes, mas a arquitetura ainda é a mesma desde 2022: transformers são geradores de texto glorificados, com um fator de sorteio aleatório que sempre vai embutir entropia no processo (nunca vai ser exato, determinístico). SEMPRE vai precisar de intervenção humana (e bastante).
Agora vou demonstrar com um exemplo real o que isso significa.
No final, eu parei este projeto depois de 43 commits. Eu segui o processo que sempre digo que é o melhor: fazer prompts pequenos, uma funcionalidade de cada vez, checar que funciona e está correto, mandar fazer git commit e partir pra próxima funcionalidade ou requerimento.
Numa conta de padeiro, cada commit ficou pronto depois de uma meia dúzia de prompts, em média. Vamos dizer que foi então 43 commits x 6 prompts = quase 258 prompts ao longo de mais de 12 horas. Alguns prompts foram uma frase simples que resolveu em 2 segundos. A maioria levava minutos e múltiplas iterações do agente (Crush).
A janela de contexto do GLM 4.7 é média: uns 200 mil tokens. O Crush tem um mecanismo que quando chegar muito mais de 90% de uso, ele manda resumir o contexto até agora, pra poder resetar e recarregar desse resumo pra continuar. Mas ele ainda tem bugs e às vezes crasheia e perde o contexto:

Aí eu preciso recuperar o último prompt, às vezes eu mesmo digitar parte do contexto que foi interrompido, pra ele conseguir continuar de onde parou. É trabalhoso e precisa ficar prestando atenção. Esse é um problema que um Gemini tem menos porque a janela de contexto dele é MUITO maior (mas a atenção no meio vai degradando, quanto maior vai ficando, é um trade-off).
“Ah, o Akita só pode ser burro. Eu já fiz um app de Todo e não chegou nem perto de 250 prompts. Ele fez errado.”
Agora vamos começar a parte que separamos os meninos dos homens. De fato, pra “fazer funcionar” não precisa de tudo isso de prompts. Dos 43 commits que levaram 10+ horas, eu já tinha um app que “funcionava” depois de 10 commits pequenos, que levou cerca de 1 hora.
Se quiserem ver a versão “v0.1”, basta fazer assim:
git clone https://github.com/akitaonrails/tvclipboard.git
cd tvclipboard
git fetch --tags
git checkout v0.1Esta versão tem 1.827 LOC de GO e 255 LOC de Javascript. Mas o backend Go mesmo tem só 549 LOC vs 1.431 LOC no final. E isso porque nesta versão mínima eu já adicionei testes unitários de backend (1.278 LOC), que a maioria dos iniciantes nunca coloca. Então daria pra “resolver” meu problema em pouco mais de 800 LOC, menos de 1 hora e meia dúzia de prompts.
A estrutura do projeto ficou assim. Guardem esta imagem pra comparar como vai ficar no final:
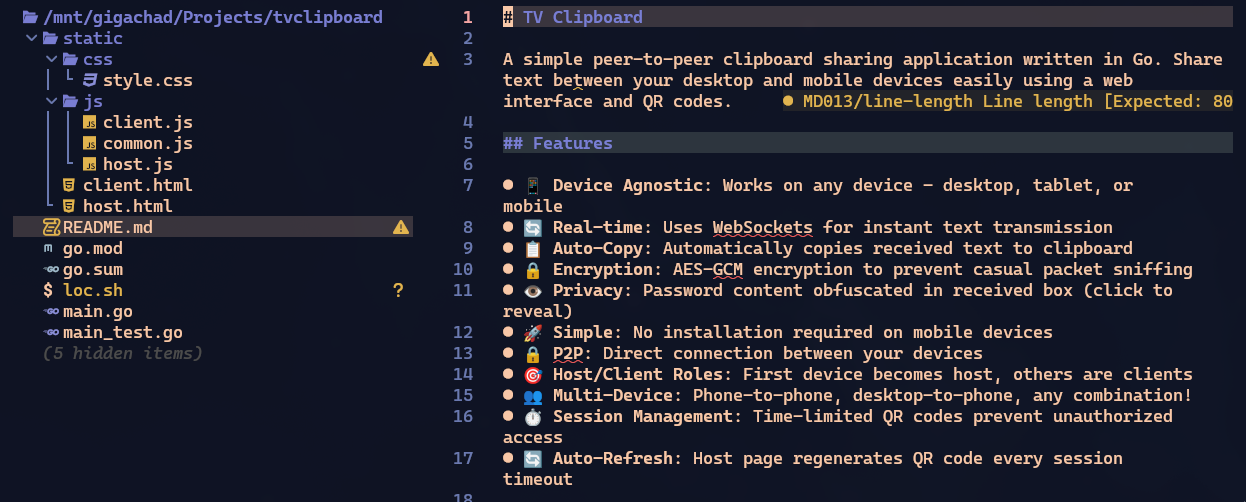
Nesta versão já abre o que eu chamo de página “host” que é a página que abriria na minha TV, mostrando o QR Code pra conectar. Já tem a página “client”, que é o que o QR Code vai abrir no meu celular. E já consegue colar texto no cliente, mandar pro host e copiar no clipboard dele. Bem simples.
É aqui que 99% das pessoas iriam parar e dar por completo.
Fase 2: Indo além de “só funcionar”
Vou repetir: este projeto é mais simples que um todo list e é feito exclusivamente pra somente eu usar, em casa, na minha rede local. Qualquer um que pensar “ah, isso tudo é desnecessário pra esse app” - EU SEI!.
A ideia é demonstrar o mínimo que se precisa pensar num projeto de verdade. Se estiver fazendo um brinquedo só pra você sozinho, tanto faz a qualidade.
Pra quem for sênior de Go, ou Javascript (porque vou usar no front), eu sei que vocês vão pensar “ah, ele deveria ter usado framework X ou biblioteca Y” - EU SEI!! 😅 No final vai ter uma seção onde vou discutir um pouco dessas outras opções, esperem antes de sair comentando!!
Voltando ao conceito de Pareto. Eu falei que 20% do trabalho mais importante custa 80% do tempo, mas isso é só uma ordem de grandeza. No meu exemplo, o projeto todo levou mais de 10 horas e “pra funcionar” levou só 1 hora. Então está mais pra 90/10 em vez de 80/20.
O que diabos custou 90% do tempo se em 10% “já funcionava”??
1. Gerenciamento de Tokens
A primeira coisa que eu penso quando vejo um QR Code é que o link dentro dela seja descartável e volátil. Não é uma regra e obviamente depende do app. Pro meu appzinho é sim “overkill” mas vou fazer pra dar de exemplo. (não vou ficar repetindo toda hora “sim, pro meu app não precisava”, esta é a última vez).
Eu não quero que uma visita que use meu app em casa consiga bookmarkar o link e conseguir usar fora daqui (eu vou expor meu serviço na internet pra conseguir usar de qualquer lugar depois). Eu quero que cada uso seja único e que expire depois de alguns minutos, exigindo um novo QR Code.
Portanto eu preciso de algum sistema de tokens que expira.
Este artigo já vai ser muito longo, então não vou ficar copiando o código inteiro de cada funcionalidade. Vou sempre indicar o commit onde implementei pra vocês pesquisarem depois e mostrar só trechos pra ilustrar.
Enfim, o objetivo vai ser ter uma URL como http://clip.example.com/?token=blablabla. Nada de outro mundo.
Sim, poderia ser um JWT, mas meu uso é muito simples então mandei fazer do zero e o GLM 4.7 inventou uma estrutura JSON com uma chave privada aleatória e um timestamp, que ele resolveu encriptar com AES (não precisava mesmo) e encodar em hexadecimal pra ser o token (fica hiper longo, mais de 100 caracteres).
Ficou um monstrinho assim:
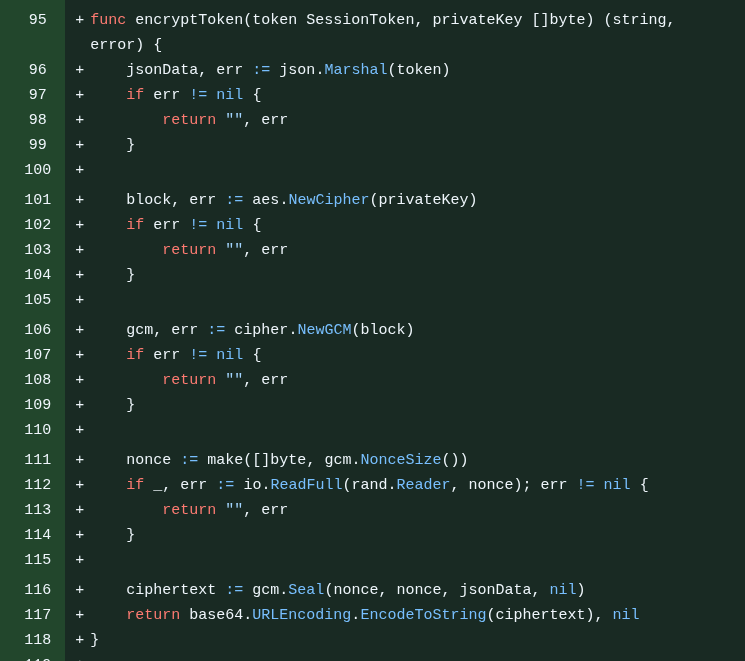
Eu não gostei mas resolvi deixar assim porque está funcionando. Eu posso mexer nisso mais tarde - inclusive, muita coisa foi feita “fora de ordem” porque eu fui fazendo à medida que ia lembrando. Não tinha um planejamento passo-a-passo escrito antes. Literalmente tirei da cabeça em tempo real mesmo.
O objetivo disso é lembrar que Gerenciamento de Sessão é uma preocupação que todo dev tem que ter na cabeça num sistema de verdade.
2. Primeiro Refatoramento
O código principal já estava com mais de 500 LOC, os testes com mais de 1000 LOC. Isso é muito grande pra ficar num arquivo só. Então pedi pro GLM refatorar em pacotes. Esse tipo de coisa eu sei que o Claude Code faz com mais facilidade, mas o GLM se saiu bem também. No final ficou algo assim:
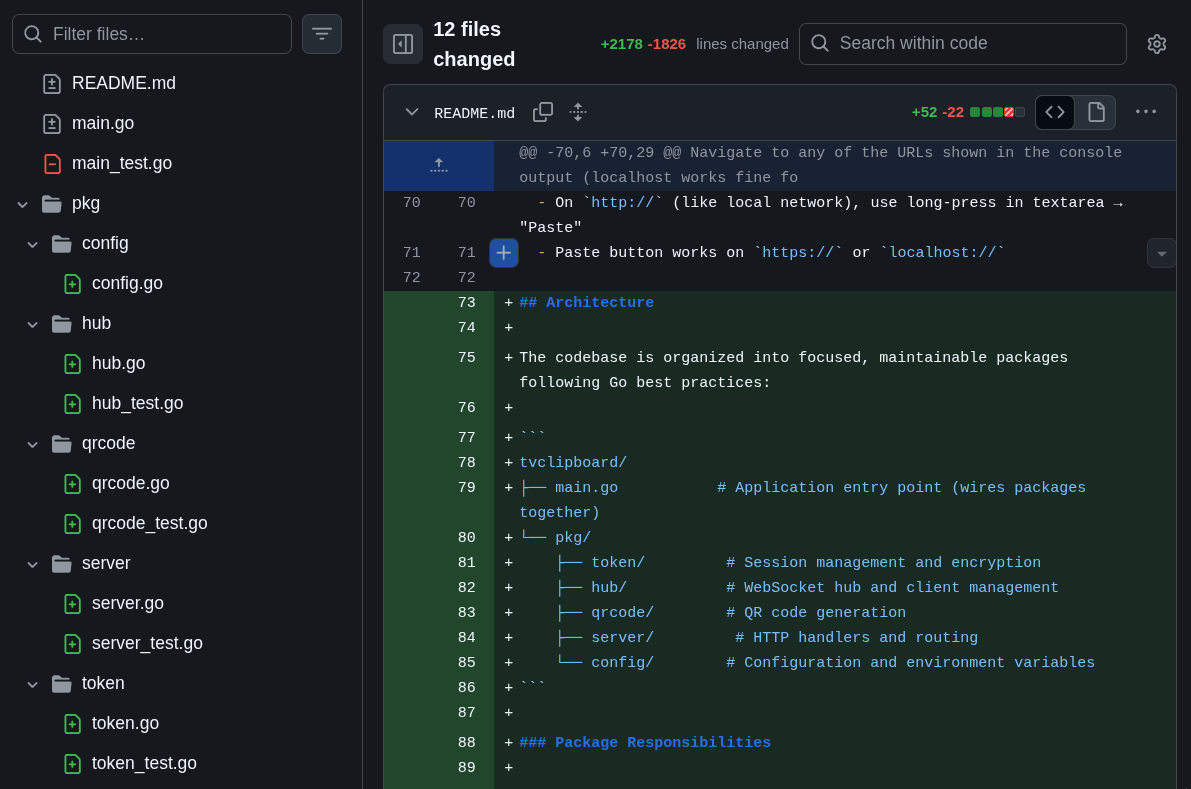 Isso é o que chamamos de “Separation of Concerns”. Cada pacote tem um domínio isolado. Um pacote pra lidar só com opções de configuração, outro pra cuidar só do servidor HTTP, outro pra lidar só com a geração de QR Code e outro pra lidar só com gerenciamento de Tokens. Cada um com testes unitários no mesmo pacote.
Isso é o que chamamos de “Separation of Concerns”. Cada pacote tem um domínio isolado. Um pacote pra lidar só com opções de configuração, outro pra cuidar só do servidor HTTP, outro pra lidar só com a geração de QR Code e outro pra lidar só com gerenciamento de Tokens. Cada um com testes unitários no mesmo pacote.
Pedir pra fazer testes desde o começo foi uma grande ajuda à LLM, porque vira e mexe ele rodava o teste, ficava confuso do porquê não funcionava e caia a ficha que precisava ajustar a implementação. Todo feedback automatizado é importante pra LLM ter contexto pra trabalhar.
E refatoramento não é algo que se faça apenas uma vez. É um processo que tem que ser feito de tempos em tempos pra consolidar e simplificar o código, melhorando a mantenabilidade.
O objetivo disso é lembrar que “só porque funciona”, não significa que o código fica congelado e não se mexe mais.
3. Suporte a Docker
Como eu iria rodar no meu home server, suporte a Docker é obrigatório. Mas independente disso, é uma boa prática manter um Dockerfile que funciona. É outro tipo de “teste automatizado”: ver se consegue “buildar” uma imagem e rodar. E documentar pra outro usuário que ele não precisa instalar nada no sistema dele pra rodar, basta rodar o Docker:
docker run -d \
--name tvclipboard \
-p 3333:3333 \
akitaonrails/tvclipboard:latestInclusive, o comando acima funciona, caso você queira testar imediatamente. Eu subi a imagem na minha conta no Docker Hub.
E se já não tinha implementado assim, isso também força que você adicione opções de configuração na forma de variáveis de ambiente (como TVCLIPBOARD_SESSION_TIMEOUT) ou via argumentos em linha de comando (como --expires), expondo o que é configurável.
O objetivo aqui é lembrar como é importante automatizar build e documentar como usar pra outras pessoas.
4. Organizar Javascript e adicionando Cache Busting
Pra “só funcionar”, lá no começo, bastava fazer um “index.html” e ir escrevendo if host ou if client no meio do HTML e JS. Mas pelo menos o GLM iniciou duplicando um host.html e um client.html. Mas o javascript estava todo inline entre tags <script>...</script> e duplicado nos dois arquivos, então outro passo de refatoração foi pedir pra ele separar common.js, client.js, host.js.
É o mínimo do mínimo de mantenabilidade. Novamente: refatoração não acaba num passo só.
Mas eu poderia esbarrar num problema. Sendo um sisteminha muito simples, não tenho nada de ETAGs implementado e nem asset pipeline como WebPack ou similares.
Num web framework dinâmico, a maioria vai ter suporte a gerar arquivos de CSS e JS dinamicamente mudando os nomes pra coisas como /assets/host-20260128123456.js e toda vez que editarmos algum JS, o pipeline vai regenerar esse arquivo com outro nome.
Quando abrimos num navegador web, ele vai sempre tentar “cachear” assets estáticos como imagens, JS, CSS, pra não ficar pedindo a mesma coisa toda hora. Se ele já baixou host.js, no próximo “reload”, se pedir o mesmo arquivo, basta pegar do cache em vez de pedir pro servidor de novo.
O problema disso é se mudarmos o conteúdo do arquivo e manter o mesmo nome. O navegador vai achar que é a mesma coisa e você vai ficar horas coçando a cabeça pensando “porra, eu já consertei isso, porque não aparece??” - e pode ser cache.
Pra evitar isso, existem técnicas de Cache Busting, como cabeçalhos ETAG. Mas o mais comum é só adicionar algum tipo de indicador de timestamp na URL, por exemplo /static/js/host.js?v=20260128120431. Desta forma, sempre que meu servidor reiniciar, o timestamp vai mudar (não é a melhor regra, mas pra agora funciona). A URL vai ser diferente e o navegador vai ser forçado a baixar a versão mais nova, garantindo que eu não perca tempo caçando problemas de cache.
Novamente, qualquer web framework minimamente competente, com suporte a templates de HTML, vai ter isso, mas eu pedi pra fazer do zero:
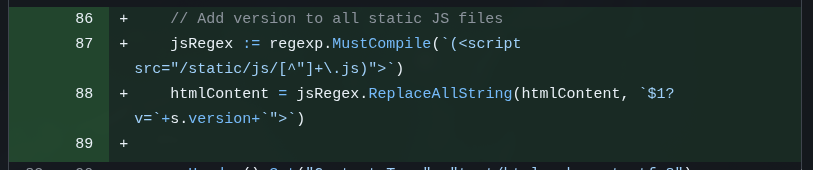 Como eu sirvo páginas estáticas de HTML, o código do meu servidor precisa modificar as URLs antes de mandar pro navegador, e é isso que o commit acima faz.
Como eu sirvo páginas estáticas de HTML, o código do meu servidor precisa modificar as URLs antes de mandar pro navegador, e é isso que o commit acima faz.
Ao escrever este post, notei que ele adicionou cache busting pros arquivos “.js” mas esqueceu do “style.css”, que ficou sem. Eu não notei porque não mexi quase nada no CSS original que ele fez. Mas novamente, pra demonstrar que LLMs nunca são perfeitas e tem que ficar constantemente checando se ele não esqueceu nada ou deixou sobrar coisas. Mandei ele consertar neste último commit
O objetivo aqui é lembrar que não basta só jogar arquivos no servidor sem saber como eles são servidos. Todo front-end precisa saber como um navegador funciona. Não basta “saber HTML”.
5. Adicionando Argumentos de Linha de Comando e fazendo mais limpeza
Os próximos três commits são besteiras que eu deveria ter feito squash num único commit.
Aqui é mais pra lembrar que não é inteiramente ruim deixar um agente como Crush fazer git commits automaticamente, mas precisa prestar atenção pra talvez ter que mandar desfazer (git tem como refazer commits, com opções como -amend).
Eu só adicionei opções de linha de comando. Agora o binário tem este suporte:
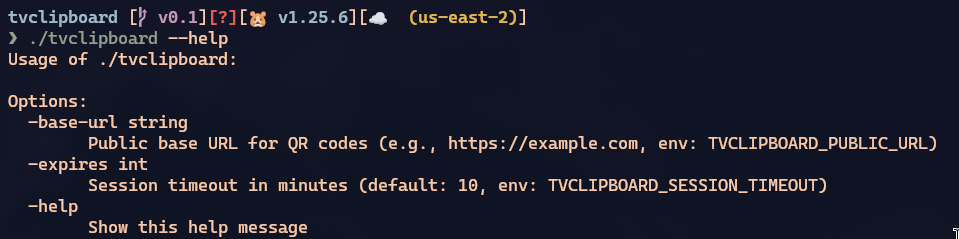
E como ele esqueceu de documentar no README, o outro commit é pra isso. Por isso falei que o certo era dar squash num commit só, porque são a mesma tarefa.
6. Configuração de ambiente de Dev vs Produção
Este é outro ponto que todo iniciante ignora. O famoso “ah, mas na minha máquina funciona”.
Em web, principalmente, a “sua máquina”, sempre vai ser um localhost, ou 127.0.0.1 ou 0.0.0.0 (assista à minha playlist sobre Redes) pra entender a diferença.
O problema: se subir esta app localmente no meu PC, eu acesso por http://localhost:3333. Quando o QR Code for gerado, ele vai usar “localhost”. Agora imagine seu celular tentando carregar um link de “localhost”. Obviamente, não vai funcionar. Porque no seu celular não tem o aplicativo rodando nessa porta em localhost. Eu preciso do IP do meu PC. Então, a primeira coisa que preciso pedir pra corrigir é que, caso seja localhost, que ele procure o IP do meu PC - que vai ser algo como 192.168.0.xxx. Estando meu PC e meu celular no mesmo DHCP, na mesma rede, eles conseguem se achar por esse IP privado.
Mas e quando eu subir num Docker? O IP interno de um Docker é diferente do IP externo (o container sempre está ou em NAT ou em Bridge). O IP “externo” do container vai ser algo como 192.168.xxx, mas o IP interno vai ser algo como 172.xxx. Novamente, se o QR Code usar o IP interno, vai dar problema.
Então eu preciso de uma nova configuração, que normalmente se chama PUBLIC URL ou PUBLIC HOST ou só HOST. Onde eu declaro explicitamente.
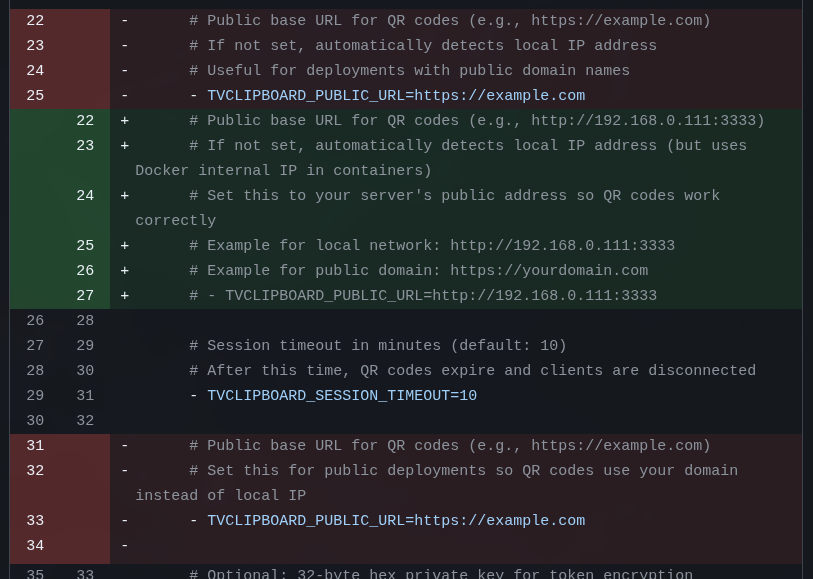
Por exemplo, quando terminar, como falei, vou deixar meu serviço exposto na internet usando um domínio válido pessoal. Algo como https://clip.example.com com suporte a TLS e tudo mais. Então eu preciso que no docker-compose.yml eu consiga ter uma opção assim:
- TVCLIPBOARD_PUBLIC_URL = https://clip.example.comE assim o QR Code é gerado com este nome em vez de ter que tentar adivinhar. Mas ao mesmo tempo, se não passar nada, assume “localhost”.
Neste primeiro commit ele ainda não faz tudo isso - eu fui fazendo aos poucos. Mas é como se começa esse tipo de funcionalidade.
O objetivo aqui é lembrar que “rodar na minha máquina” (localhost) não significa nada. Não vamos colocar “sua máquina” em produção. “Funcionar” significa “funcionar FORA da sua máquina”.
7. Mais limpeza de código
Estou de propósito mencionando “limpeza de código” o tempo todo pra que fique bem claro que uma parte considerável do trabalho de programação é “limpar” código que já foi feito.
Os próximos quatro commits são só manutenção.
Por exemplo, sem querer a LLM largou um trecho duplicado dentro do código. Não quebrou nada porque foi na configuração de Docker Compose:
 Além disso, tem um comportamento acidental na forma como este app funciona que resolvi deixar como “feature”. Sempre precisa ter um navegador que abre primeiro que automaticamente se torna o Host e exibe um QR Code. O próximo navegador a abrir precisa do link desse QR Code e vira o “client”.
Além disso, tem um comportamento acidental na forma como este app funciona que resolvi deixar como “feature”. Sempre precisa ter um navegador que abre primeiro que automaticamente se torna o Host e exibe um QR Code. O próximo navegador a abrir precisa do link desse QR Code e vira o “client”.
Mas quando o host fecha, o client perde a conexão e automaticamente é promovido a host. Eu não pedi pra ser assim mas acabou ficando, então pedi pra deixar e documentar.
O objetivo aqui é lembrar que LLMs não são perfeitas, vão deixar sobras pra trás, e você precisa ficar o tempo todo monitorando.
8. Otimizando Javascript
Os próximos três commits são pra dar uma limpeza no Javascript.
Da última vez que mexemos, eu só tinha pedido pra ele tirar os Javascript inline do HTML e separar em arquivos “.js” reusáveis. Mas chegou a hora de dar uma olhada neles.
De cara, deu pra ver que tinha duplicação entre client e host, então pedi pra deduplicar e jogar no “common.js”.
Além disso tinha vários pequenos probleminhas:
- um monte de variáveis e funções no escopo global (poluição de global: má prática)
- websockets que abrem mas sem nada checando o fechamento
- timers sendo ativados mas nunca desativados (leaks)
O código Javascript “que funciona” sempre é assim: tudo global, tudo aberto, nada checado, vários leaks. Isso é normal e toda LLM vai fazer assim.
Também não acho que precisa fazer prompts desde o começo exigindo SOLID e tudo mais. Primeiro faz funcionar, depois faz funcionar direito, finalmente faz funcionar rápido. É sempre nessa ordem, especialmente num escopo simples com este.
Por isso agora é hora de pedir pra refatorar. E a primeira coisa a fazer é sempre isolar o escopo, por exemplo, num bloco assim:
(function() {
'use strict';
...
})();O problema disso é que toda função que o HTML pedia, como “onclick”, vai falhar porque agora não tem mais nada no escopo global. Uma vez tudo escondido, agora tem que ir expondo somente o que realmente precisa público.
Isso se chama IIFE Encapsulation (Immediately Invoked Function Expression). Tem milhares de práticas como essa que Javascript precisa pra ficar “mais limpo”. Eu sei, eu deveria estar usando módulos, Typescript, bla bla, mas esse é um exemplo simples mesmo.
O objetivo aqui é lembrar que, só porque “funciona”, não significa que “está bom”, principalmente com Javascript.
9. Otimizando o Golang
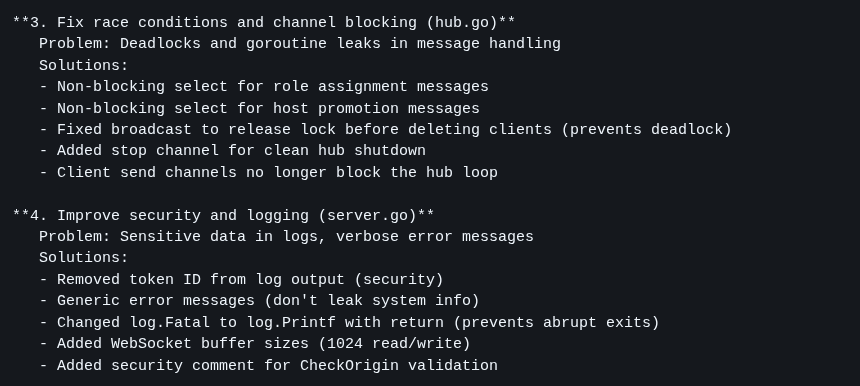
Esta é a seção mais longa. O código Golang já “funciona”, mas ele não está bom ainda. Eu sei que tem race conditions em channels, eu sei que o tratamento de erros está ruim, eu sei que ainda tem micro problemas de segurança, então quero consertar o que puder.
Os próximos 6 commits lidam com:
- Refactor: Improve error handling, race conditions, and graceful shutdown
- Fix: Critical race conditions, memory leaks, and security issues
- Security: Add message size validation and rate limiting to prevent abuse
- Config: Tighten security limits and add origin validation
- Fix: CORS origins, Web Crypto API fallback, and clipboard issues
- Fix: QR code uses correct port from PublicURL and document Web Crypto API HTTPS requirement
O próprio GoLang tem ferramenta pra checar race conditions, o Data Race Detector. Basta colocar a opção --race em comandos como go build ou go test. E felizmente o GLM foi esperto e imediatamente usou essa ferramenta quando pedi pra checar esses problemas.
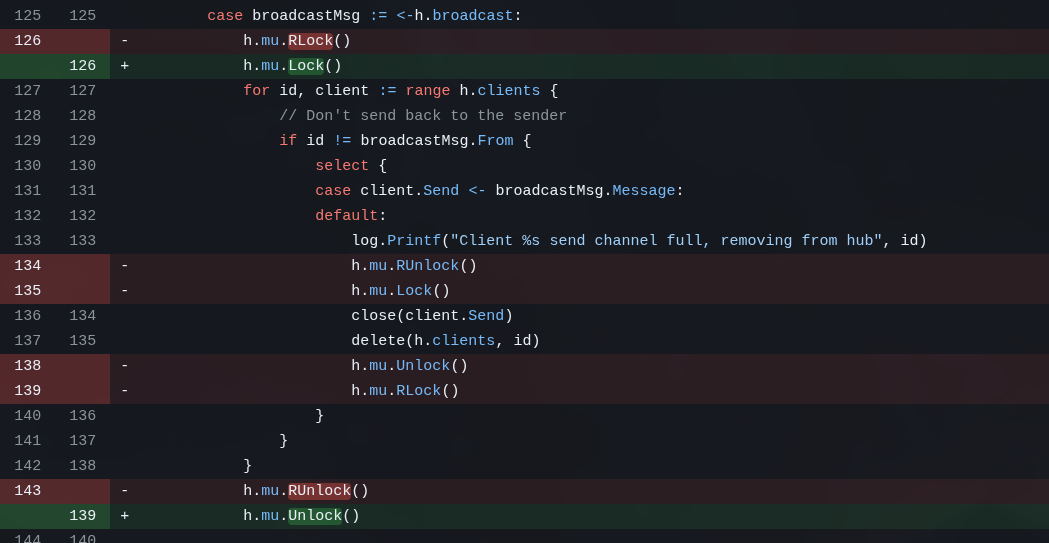
Race conditions acontecem quando duas tarefas assíncronas tentam modificar a mesma estrutura de dados, por exemplo. Uma das formas de “consertar” é colocando Locks ou Mutexes em estruturas que só podem ser modificadas sincronamente. Qualquer aplicação que tenha qualquer coisa assíncrona, eventualmente vai ter problemas de condição de corrida. Não é “talvez”, é “quando”.
Um servidor precisa ser “bem comportado”, não pode simplesmente “crashear”, dar “panic”. Mas o primeiro código “que funciona” que o GLM fez tinha vários trechos assim:

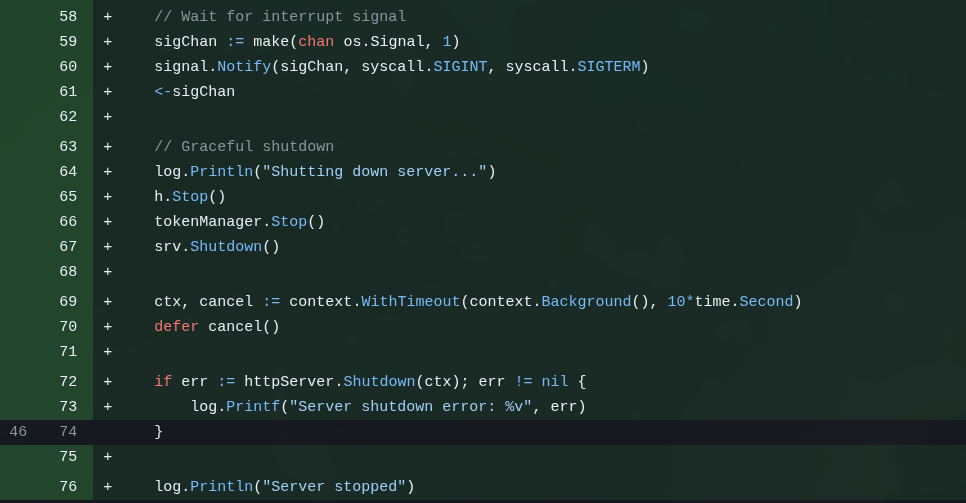
Isso está errado. Além disso precisamos que o servidor aceite corretamente sinais de sistema como SIGINT, SIGTERM, etc. É quando damos “Ctrl-C”, por exemplo, ou o Docker manda desligar o container. Ele não vai simplesmente crashear o programa, primeiro ele vai pedir pro programa se desligar sozinho, dando chance dele fazer limpeza, como dar flush em arquivos, fechar portas e coisas assim.
Isso se chama Graceful Shutdown.
Não parei pra checar o quão certo o GLM estava mas segundo ele mesmo, alguns dos problemas que ele mesmo encontrou, no código que ele mesmo fez, incluem coisas assim:
Como podem ver, só porque “compila”, não quer dizer que está ok. Só porque “roda”, não quer dizer que está ok. Mesmo pedindo pra checar MÚLTIPLAS VEZES a LLM não acha todos os erros de uma só vez. Cada um desses commits levou horas pra conseguir resolver e eu tive que intervir múltiplas vezes, e ainda assim eu ainda não tenho certeza que ele pegou tudo (precisaria revisar com mais calma - mas eu queria publicar este artigo logo 😂).
10. Adicionando Sistemas de Segurança
Novamente, nada disso é necessário num sistema que somente eu vou usar na minha rede local, mas você como desenvolvedor precisa se responsabilizar.
SEMPRE considere que todo usuário do seu sistema é MALICIOSO! Essa é a REGRA, não a exceção.
Um exemplo bobo: o usuário pode colar e transmitir qualquer texto via websockets pro meu servidor. As 3 coisas mais óbvias que imediatamente passaram na minha cabeça foram:
a) Quando o host recebe o texto, ele renderiza no HTML na caixa de “Recebido”
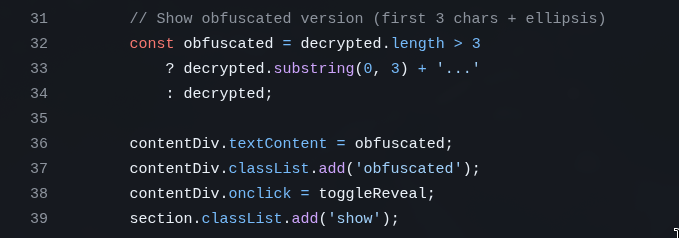
E se o usuário mandar um <script>....</script>? Isso vai renderizar no HTML e o navegador vai EXECUTAR. É assim que funciona Code Injection. É assim que funciona XSS (Cross-Site Scripting). Isso era muito comum em antigos fóruns ou sistemas de comentários. Pra evitar isso se deve SANITIZAR tudo que vem do usuário.
Felizmente, o jeito que o GLM fez já é sanitizado porque ele escreve o conteúdo com textContent em vez de innerHTML, então o texto é escrito literalmente sem executar:
 Por acaso ele fez certo de primeira, mas precisa checar porque ele poderia ter feito errado.
Por acaso ele fez certo de primeira, mas precisa checar porque ele poderia ter feito errado.
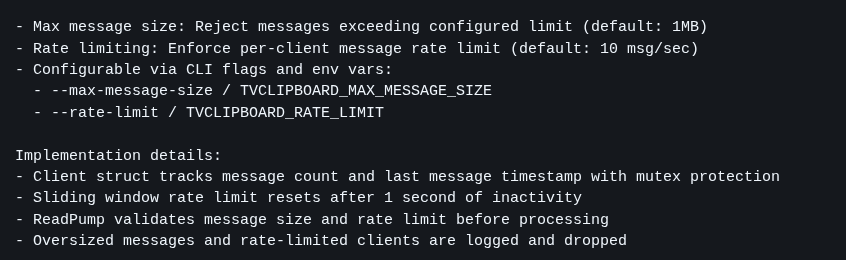
b) Não tinha checagem de tamanho da mensagem
Nunca um usuário pode conseguir enviar um texto de tamanho qualquer. Ele sempre pode tentar diretamente dar POST com um arquivo de gigabyte pra ver se estoura algum erro de Overflow no servidor, expondo algum exploit de segurança.
TODO campo de usuário precisa de limites e precisa checar não só no cliente/front-end, mas mais importante, no backend:
 c) Tem que rejeitar Spammers!!
c) Tem que rejeitar Spammers!!
Novamente, não pode assumir que todo mundo vai usar seu web app bonitinho. A regra é achar que todo mundo vai tentar derrubar ou invadir. E uma forma de fazer isso é criar um script pra ficar fazendo milhares de POST por segundo pra tentar algum tipo de Denial of Service, onde o servidor enfileira tanta requisição que vai estourar.
O certo é configurar isso num outro serviço que vai ficar na frente do seu, como Cloudflare.
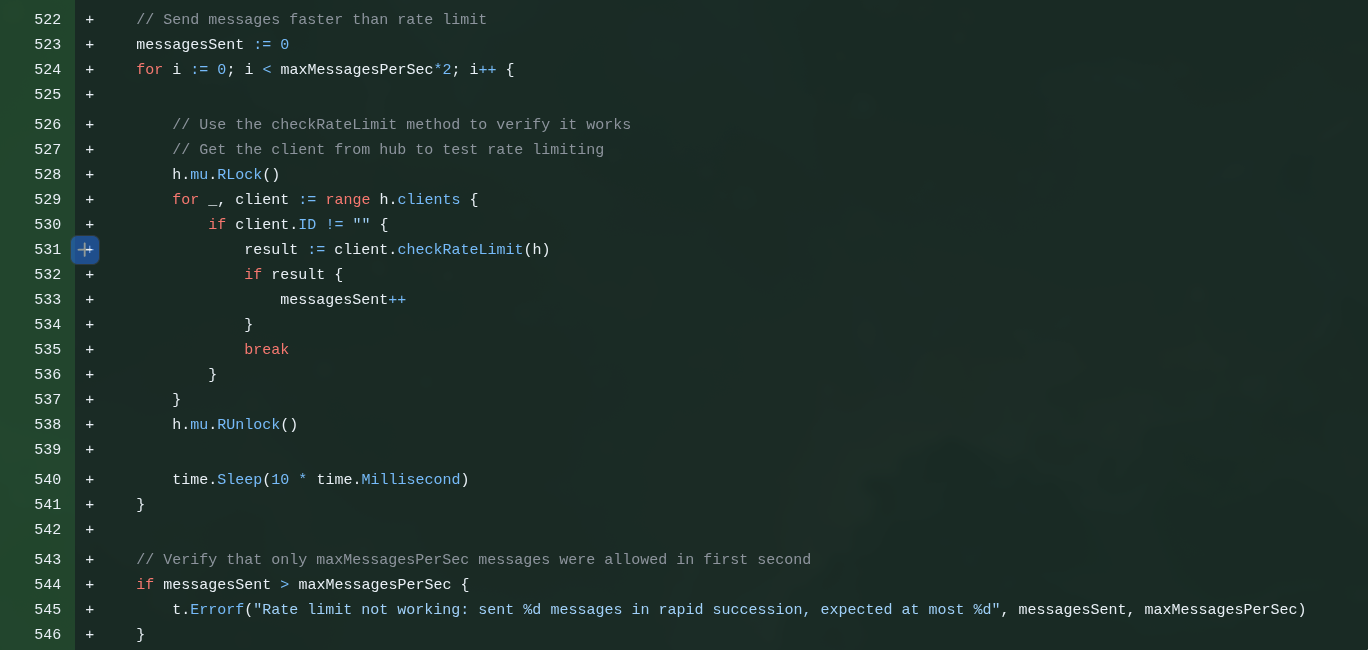
Mas não custa implementar um fallback na sua aplicação mesmo. Um jeito de configurar quantas requests um mesmo usuário pode fazer de cada vez (ex. 4 requisições por segundo - ninguém vai colar texto tantas vezes por segundo numa app dessas).
Se tentar mais que isso, o app tem que imediatamente REJEITAR e dropar a conexão, sem gastar tempo processando mais, liberando recursos pra outras requisições de verdade. Isso se chama RATE LIMITING.
 d) Outro problema que iniciantes não param pra pensar é em CORS e Origin Check.
d) Outro problema que iniciantes não param pra pensar é em CORS e Origin Check.
Como falei antes, temos Javascripts como /static/js/common.js. Não é nenhum grande problema outra pessoa usar porque não tem nenhum grande segredo neles. Mas no mínimo eu não quero que algum site “http://malware.pk/index.html” da vida inclua dentro dele um https://clip.example.com/static/js/common.js e eu fique pagando pelo tráfego dele.
Eu quero que somente a MESMA ORIGEM, no caso “clip.example.com”, seja capaz de carregar arquivos no mesmo servidor. Ninguém de fora é bem-vindo e isso é a BOA PRÁTICA. Estude CORS (Cross-Origin Resource Sharing). Isso é mais importante se seu sistema são múltiplos domínios onde um depende do outro, daí você quer - controladamente - permitir somente determinados outros domínios que estão sob seu controle.
Regra de tudo em rede é DENY ALL e depois ALLOW [específico]. NUNCA deve ser ALLOW ALL.
Pra implementar isso demorou um bocado, porque o GLM ficou se enrolando de como permitir “localhost”, mas também “192.168.xxx:3333”, mas também “clip.example.com” (via porta 443), etc. Não é difícil, só o GLM que se complicou todo e eu tive que intervir várias vezes com prompts pra colocar ele na direção certa. Acabou dando múltiplos commits até ele acertar.
e) Outro probleminha que iniciante não pensa: PERMISSÕES de recursos do navegador.
Toda vez que carregar esse sistema em “localhost” e ele receber a mensagem pra jogar no clipboard, vai aparecer este alerta pedindo permissão:
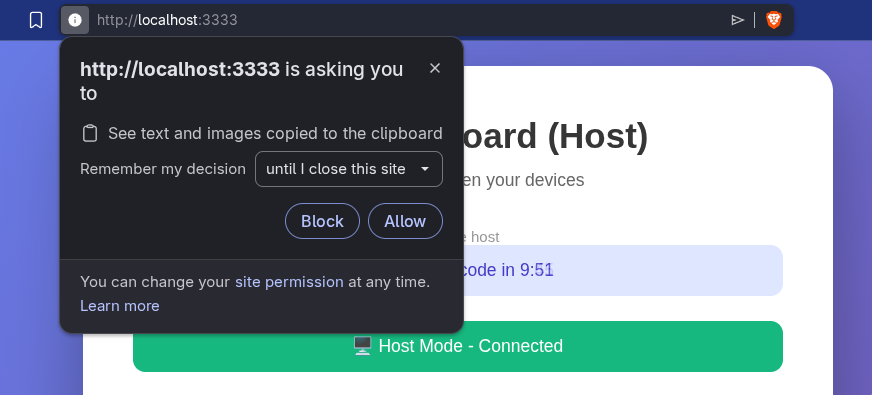
E isso é normal e correto: nada deveria ter acesso a coisas fora do navegador. Por isso o Javascript pede “manda pro clipboard”, daí o navegador intercepta, checa a permissão e, se não tem ele pede. Toda vez vai pedir. Mas se usar um domínio de verdade (ex. clip.example.com), ele vai perguntar uma vez e depois lembrar pra cada domínio. É um dos motivos pelos quais vou expor na internet: pra ter um domínio de verdade.
Expor serviços na internet é PERIGOSO. Por isso eu fiz este artigo explicando como usar domínios de verdade e este outro artigo sobre como usar Cloudflare Zero Trust.
f) Tinha outro fator de segurança que é “overkill” mas eu quis implementar mesmo assim.
Digamos que eu queira rodar somente em localhost. Digamos que seja uma rede privada, mas compartilhada (visitas, companheiro de quarto, escritório, etc). Ao rodar em localhost não vai ter TLS, ou seja, os pacotes HTTP vão trafegar em texto aberto.
Qualquer um com um Wireshark pode ficar “escutando” (“sniffing”) os pacotes na rede e interceptar os meus. E se justo eu estiver passando dados sensíveis, como uma senha, vai dar pra ver aberto.
O certo é rodar com TLS (HTTPS). Mas só pra um “quebra-galho”, pedi pro GLM implementar uma obfuscação simples (não é um processo totalmente seguro, mas usa AES-GCM), mas já serve pra não ficar óbvio com um sniffer. Pra isso ele vai usar Web Crypto API.
Mas tem um porém: Web Crypto API está disponível somente se o site abrir com HTTPS ou se for localhost. Mas se eu tentar http://192.168.xxx:3333, não vai estar disponível. Pra isso tem este commit pra lidar com isso e documentar.
O objetivo aqui é mostrar como aspectos de segurança, otimização, mantenabilidade são muito mais do que um iniciante pensa. Aliás, nunca vai pensar, porque precisa ter estudado antes pra saber que existe.
11. Licenças Open Source
Esse tema sozinho seria assunto pra um longo artigo, mas na prática eu tendo a pensar simples:
- se for um projeto que eu não me importo se alguém vai contribuir ou não, basta abrir com licenças PERMISSIVAS, como BSD, MIT
- se for um projeto que eu gostaria de ter contribuição e que ninguém use comercialmente, basta colocar uma licença RESTRITIVA, como GPL
- se for restritivo e for um app que poderia virar um SaaS (daí o código não é distribuído, então não precisaria contribuir), daí adiciona AGPL (Affero)
Foi o que eu fiz neste: coloquei licença AGPL 3.0.
O aviso é pra não deixar LLMs escreverem o arquivo de licença. Sempre pegue textos sobre leis, regulamentos e regras do site oficial. A LLM sempre produz uma versão resumida ou incompleta ou até errada mesmo. Documentos legais precisam ser EXATOS, não pode ter palavras erradas e sentidos ambíguos ou afirmações incompletas.
LLMs não são boas pra gerar textos legais corretos de primeira, sempre vai ter erros. Sempre assuma que textos assim estão errados: não existe “compilador” de leis.
12. Resolvendo o problema dos tokens longos demais
Lá atrás eu falei que os tokens que o GLM gerou pra mim são grandes demais (mais de 100 caracteres). Isso resulta em links super gigantes.
Não é um problema porque ninguém vai ter que digitar isso e nem é pra bookmarkar. Aqui é mais uma escolha pessoal mesmo: eu gosto de tokens curtos em URL.
A vantagem do token longo é que eu não preciso implementar nenhum tipo de “banco de dados” (key-value store, ou KV Store - Memcached, Redis). Isso porque toda a informação da sessão (ID e timestamp de expiração), estão encodados dentro desse token, por isso ele é longo. É uma struct json, encriptada com AES, convertida em Hex.
Tentando manter o mesmo conceito, neste primeiro commit eu pedi só pra ele tentar otimizar o tamanho da estrutura. Então o GLM sozinho escolheu tentar mudar de UUID (36 chars) pra um Hex ID aleatório de 24 chars. Trocar de timestamp padrão ISO (24 chars) pra UNIX (10 chars). Isso desceu dos 130 a 140 chars pra uns 112 chars. Uma redução na faixa de 20% a 25%.
Não foi uma tentativa ruim. Mas no final eu realmente não estava engolindo tokens grandes assim (poderia ser cookie também, eu sei, mas queria manter tudo na URL).
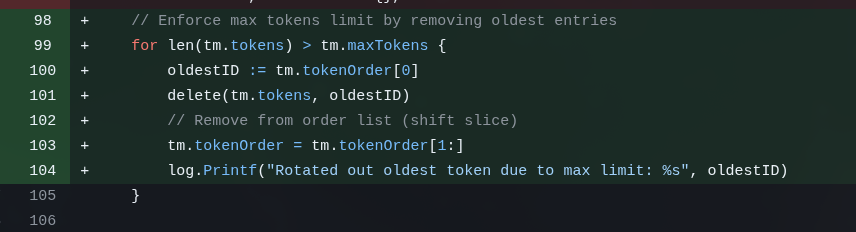
No final decidi que queria tokens realmente curtos (de 8 chars, base62) e aí precisaria guardar a Sessão em algum “storage”. Decidi que ia ser “in-memory” (afinidade ao processo, mas eu só vou rodar 1, sem load balancer, então tá ótimo). E isso seria um FIFO com rotação (chaves mais velhas vão sendo descartadas pra dar espaço pra chaves mais novas e pronto, elas expiram mesmo).
Este é o commit dessa funcionalidade e ainda tive que intervir várias vezes. Por alguma razão ele achou que seria uma boa idéia ter goroutine em background pra ficar limpando os tokens expirados desse storage. Mas isso é completamente desnecessário se for um FIFO. Ele fez, eu tive que mandar desfazer. Essa é a rotina.
13. Mais refatoramento e limpeza (quase acabando!)
Os últimos 6 commits são MAIS MANUTENÇÃO!!
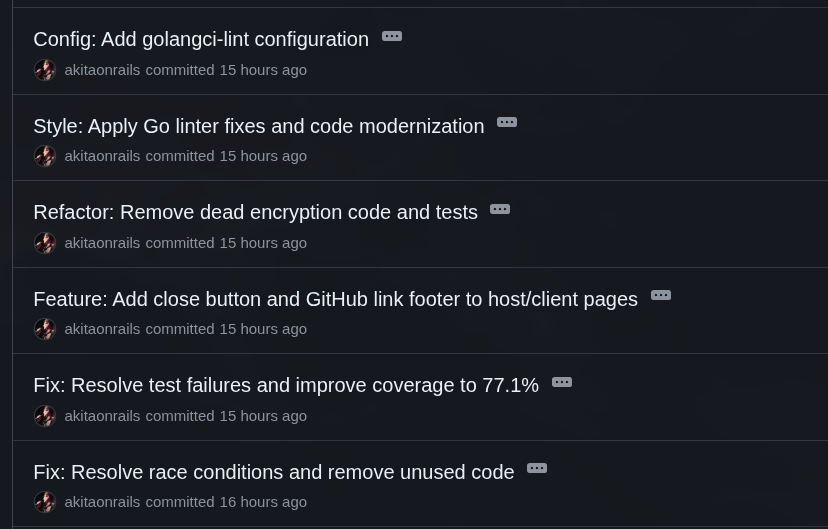
Parece zoeira, mas isso que eu fiz de manutenção é até pouco. Num projeto de verdade isso faz parte da rotina. Toda vez que você adiciona alguma coisa nova, vai estragar alguma coisa que já tinha, e vai precisar ajustar pra não acumular débito técnico.
Lembram que rodamos checagem de race condition? Adicionamos código novo, tem que checar de novo. E ele achou mais problemas corrigidos neste commit. Não lembro agora se já tinha lá atrás e ele pulou sem corrigir, ou se nas últimas mexidas acabou gerando esses novos bugs.
Depois de tanto adicionar coisas e refatorar, resolvi aumentar mais um pouco a cobertura de código do Go. O comando go test tem a opção -coverprofile pra ajudar a checar quais partes do seu código não foram testadas ainda. Então pedi pro GLM adicionar testes pras novas funcionalidades como Rate Limiting, checagem de tamanho da mensagem, check origin e outras coisas.
Mandei adicionar uma besteira que é um botão de “Fechar” no lado cliente, pra não ficar acumulando tabs no meu smartphone.
Depois que mandei trocar o sistema de tokens, não precisa mais encriptar a estrutura de timestamp. Mas ele deixou pra trás testes unitários sobre isso. Então mandei tirar. Novamente: LLMs vão deixar coisas incompletas pra trás. Muitas vezes ele não sabe se mantém um código pra não quebrar o teste, ou se é pra tirar o teste porque o código não é mais necessário.
Depois pedi pro Go rodar linter e suporte a golangci-lint pra últimas checagens. Um Linter é tipo uma checagem de formatação, sintaxe e boas práticas de codificação numa linguagem em particular. Mas a maior parte dos ajustes foi espaços sobrando, poucas indentações erradas e coisas desse tipo. Nada de mais.
Uma última coisa que foi negligência minha mesmo, é que estava esquecendo de adicionar testes de Javascript. Uma parte considerável do código é front-end pra lidar com WebSockets e tudo mais. Precisa adicionar, e isso foi neste commit.
Como fiz tudo de uma vez só, aí já pedi pra adicionar ESLint também, e priorizar testar tudo só unitariamente, com mocks e stubs pra ser tudo headless e sem precisar carregar Chromium. Só testar as funções publicamente expostas mesmo. Isso elevou a cobertura de testes de front-end de zero pra 73%, o que é uma ótima cobertura. Veja o commit pra ver como ficou.
14. Última coisa: I18n
Isso foi uma coisa que lembrei enquanto já estava escrevendo este artigo. Completamente desnecessário, mas eu queria ver se o GLM conseguiria fazer. E “conseguiu”. Eu não detalhei como eu queria e deixei ele pensar na solução. Eu teria feito o servidor em Go fazer a troca dos strings antes de enviar o HTML pro client.
Mas o GLM preferiu adicionar isso no lado do front-end e trocar as strings via Javascript. Não está errado, mas não é o melhor jeito.
Justamente tradução de linguagens é uma coisa que IAs foram feitas originalmente pra serem boas: Processamento de Linguagem Natural (NLP). Mandei extrair todos os textos em inglês e depois fazer uma versão em Português do Brasil, e posso dizer que ele fez direitinho:
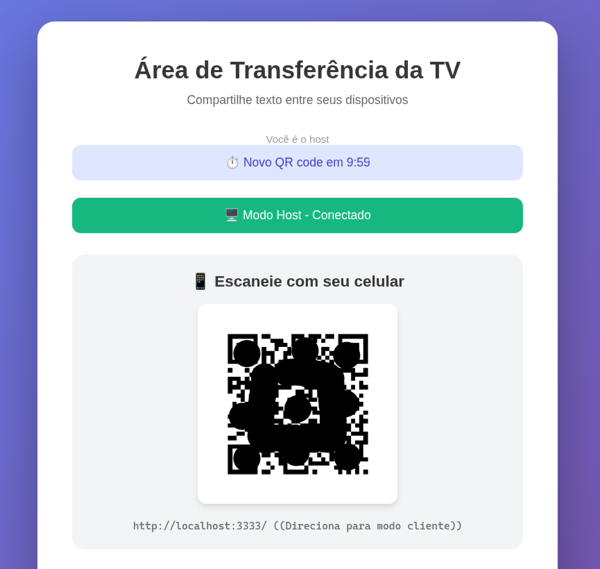
Num web app de verdade é uma coisa que sempre precisamos ficar preocupados: de não deixar mensagens pra usuário “hardcoded” e sempre ficar extraindo e testando. O que me leva à última parte:
Não era Melhor usar Framework X ou Biblioteca Y?
Povo de Go talvez não goste que eu não tenha usado Gin, Fiber ou outro web framework. Mas realmente neste caso o app é simples demais. Não tem mais que 3 endpoints. A parte mais complicada seria o WebSockets, que não ficaria muito diferente usando um framework. Ou checagens maiores como de CORS, que também não seria muito menos LOC.
No lado do Javascript, talvez I18n valesse a pena eu ter importado algum pacote pronto, mas novamente, é muito simples. Não tinha nenhuma grande funcionalidade que tive que reinventar a roda.
Claro, isso porque este app é miseravelmente pequeno, como falei no começo. Um app maior de verdade, eu recomendaria mesmo usar um framework popular com bom suporte da comunidade, bem documentado e tudo mais. Mas coisas do tamanho de um ToDo List realmente não faz diferença a menos que o exercício fosse aprender a usar determinado framework.
Pensando nisso, tem que tomar cuidado porque nenhuma LLM vai escolher pra você. Se começar com prompts pequenos, uma funcionalidade de cada vez (que é o jeito certo), ele tende a escrever as coisas tudo do zero, sem importar nenhuma biblioteca.
Você tem que saber de antemão que biblioteca vai pedir pra cada coisa!
Novamente, um iniciante não saberia, então acabaria reinventando a roda dezenas de vezes em vez de usar bibliotecas populares.
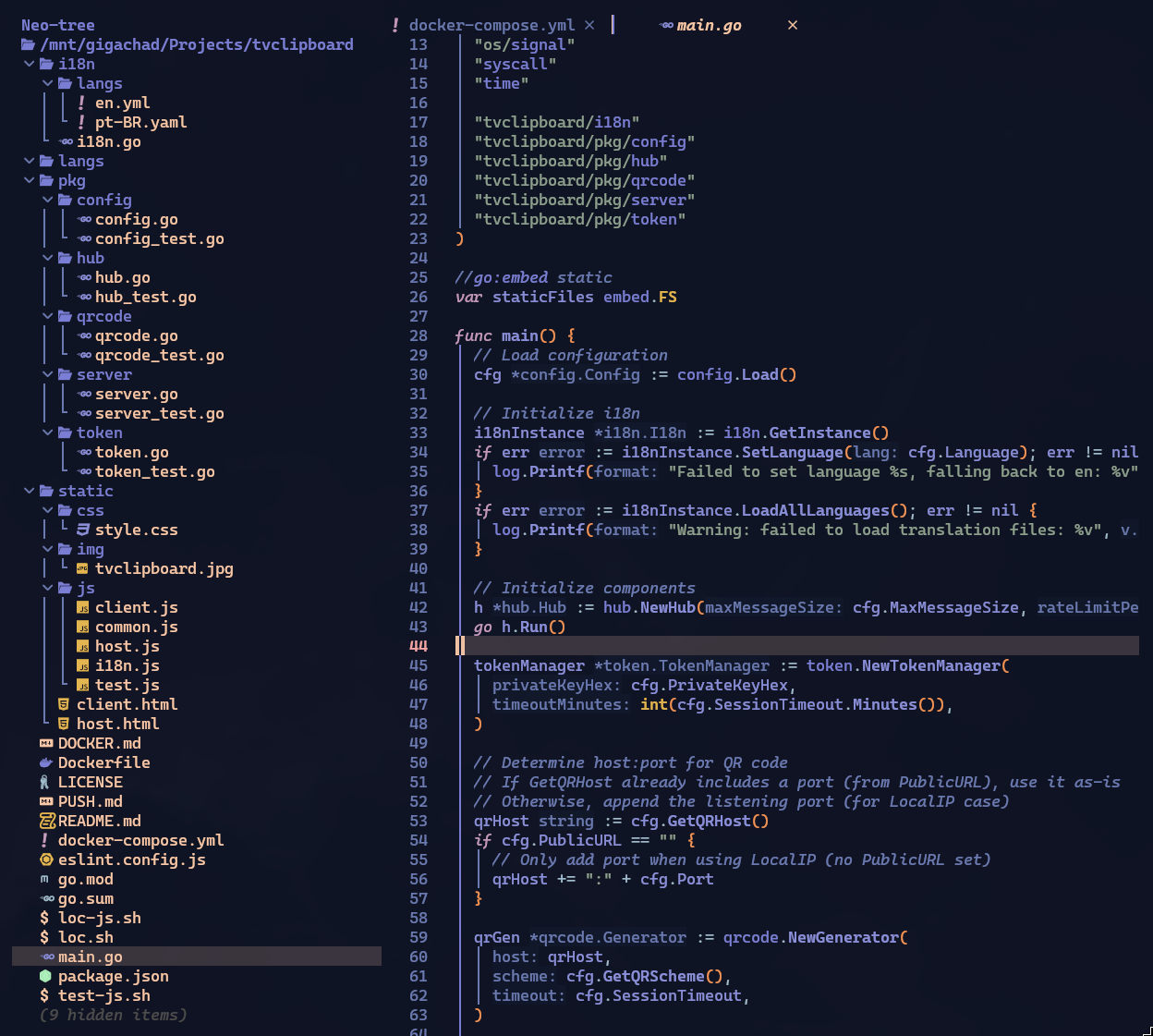
Lembram que falei, lá no começo, pra guardar como era a estrutura do projeto na versão v0.1 que “já funcionava”? Eis como fica no final num projeto de verdade:
Conclusão
Ufa! Foi Longo! Parabéns se chegou até aqui!
Minha experiência neste projetinho foi de ter um estagiário super motivado que eu precisei ficar o dia inteiro olhando atrás do ombro e toda hora falando:
“Opa! Para tudo, tá errado!” “Opa! Desfaz e faz de novo mas deste outro jeito!” “Opa! Não, você já tinha feito isso errado antes e tá repetindo!”
Não estou brincando quando falei que foram mais de 250 prompts. E isso é uma estimativa por baixo, eu acho que escrevi MUITO mais que isso.
Tão logo terminei o processo de Vibe Coding, já fiz push no GitHub e comecei a escrever este artigo, então ainda faltam horas de REVISÃO do código todo, do começo ao fim, pra ver se não deixei passar nada. Não daria pra colocar em produção sem fazer isso! Se alguém ver coisas estranhas no código, fiquem à vontade pra mandar nos comentários.
Foi realmente como se eu estivesse mentorando um estagiário. Mas com um problema: diferente de um estagiário de verdade, a LLM já se esqueceu de tudo que eu ensinei pra ele.
Quando for fazer um novo projeto com o GLM, ele vai cometer praticamente TODOS os mesmos erros e equívocos. É como se eu estivesse mentorando um estagiário cego e com memória de peixe dourado.
É extremamente cansativo!!
No final levou umas 12 horas pra codificar tudo, e eu tenho a impressão que um desenvolvedor sênior de Go teria feito sozinho na metade do tempo. Um júnior teria levado esse tempo, ao longo de uns 2 ou 3 dias (parando pra pesquisar).
Eu já sabia disso, já repeti dezenas de vezes, mas a noção de:
“Não preciso mais contratar programador, a IA faz tudo sozinha.” - é uma GRANDE FALÁCIA.
E não vai melhorar muito mais do que isso. Já estamos no topo da curva em S que eu expliquei em todo podcast que participei e nos videos do meu canal. Custa ordens de grandeza mais energia pra treinar a próxima versão do que levou todas as versões anteriores, pra ter uma evolução incremental.
Enquanto a arquitetura for a mesma, não vai sair disso. Precisa de alguma NOVA DESCOBERTA (que não aconteceu até hoje, desde 2021 quando saiu Transformers).
Um Claude Code vai ser um pouco mais rápido que GLM. A próxima versão do GLM vai ser um pouco mais rápido. Talvez o tempo de 12 horas que eu levei, vire 6 horas (pra este app miserável). Mas o PROCESSO vai ser o mesmo: ele faz errado, eu mando consertar, e faz isso ad eternum.
Não vai existir fazer um único prompt e no final sair um app perfeito, seguro, otimizado, etc. SEMPRE vai sair com bugs na primeira vez. Por isso que alguém que não é programador não deve fazer software pra colocar em produção só com Vibe Coding: precisa passar por revisão de um programador experiente de verdade.
Isso não é opcional.
Post-Mortem
Esta seção foi escrita no dia seguinte à publicação do artigo original. Depois de terminado, pedi ao Claude Code pra fazer uma análise profunda da qualidade, focando em segurança e testes. E ele achou VÁRIOS erros. Lembram que falei que não dava pra colocar em produção sem revisar com calma antes?
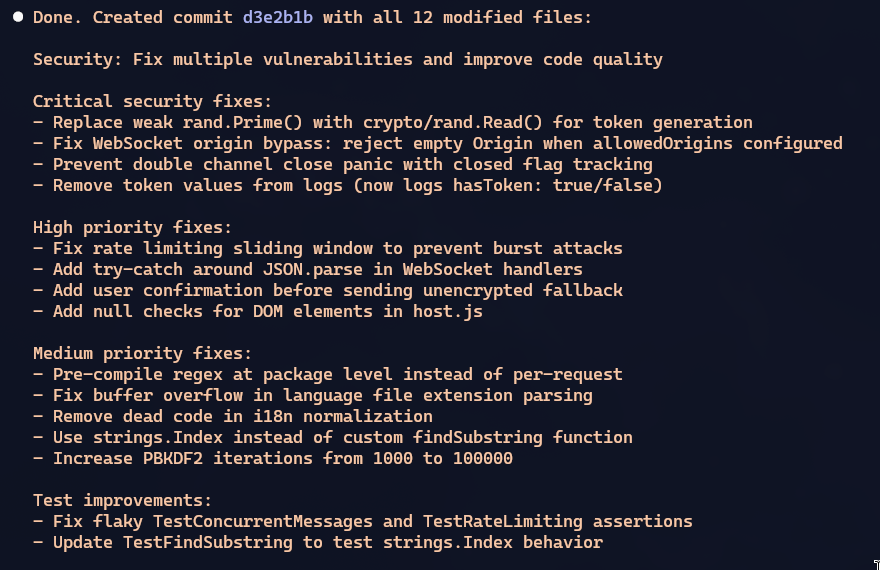
Este é o commit com os consertos, dêem uma olhada.
Então ele “Já funcionava” na Fase 1, com um monte de problemas. Eu intervi e gastei 90% do tempo na Fase 2 adicionando a fundação. Não revisei propriamente e publiquei o arquivo, agora retornei e ainda tem problemas.
Software NUNCA está “finalizado”.
Mesmo isso que o Claude Code encontrou, não significa que corrige TUDO. Significa que corrige ALGUMAS COISAS. Nenhum software nunca tem “garantia” que está perfeito. Isso não existe.
Mesmo se tivesse começado com Claude Code, como falei antes, teria sim, sido mais rápido. Mas tudo depende do que você vai pedir pra ele. Se você não souber exatamente os requerimentos e especificações de segurança, ou performance, ou escalabilidade, ou mantenabilidade ANTES de pedir, ele vai fazer ALGUMAS COISAS. Não necessariamente as COISAS PERFEITAS, mas só ALGUMAS COISAS.
Daí alguém pode dizer “Tá vendo? Agora que revisou com Claude Code, vai estar perfeito”
Então, depois eu ainda pedi pro GPT 5.2 Codex fazer a mesma análise extensiva e adivinha: ele também encontrou mais probleminhas. Muito menos, claro. Mas veja bem, depois do GLM 4.7, do Opus 4.5, o GPT 5.2 ainda achou mais coisas. NUNCA ACABA!
Em particular, lembram como lá atrás eu tinha feito tokens serem encriptados, depois mudei o requerimento pedindo pra não ser e deixar in-memory no servidor? Ainda sobrou código antigo dessa funcionalidade. O GPT 5.2 achou que era pra terminar de implementar a encriptação e começou a colocar de volta. Tive que interromper e mandar ele parar e remover. Nem o Opus 4.5 removeu esse dead code.
Sempre, você que pede é o responsável por pedir exatamente e checar depois.